学習済みのCNNモデルを用いて猫画像と犬画像を分類する方法の紹介 Part 1
学習済みのモデルを用いることで少ない学習コストで機械学習を進めることができる。
犬と猫の画像の分類
犬と猫の画像の分類はKaggleのコンペで提供された問題で犬と猫の25,000枚の画像から構成されているデータセット。
準備
まずはKaggleのサイトからデータをダウンロードします。
初めて利用する場合はユーザー登録をしておいてください。
データをダウンロードしたら、ダウンロードしたデータを扱い易いようにディレクトリごとにざっくり下記のようなディレクトリ構成にします。
画像パスは自分の環境に置き換えてください。
| ディレクトリ名(論理名) | 説明 | パス |
|---|---|---|
| original_dataset_dir | ダウンロード画像 | 'C:\Users\minarai\Downloads\dogs-vs-cats\train' |
| base_dir | 学習用データのベースディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir' |
| train_dir | 訓練データディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\train' |
| validation_dir | 検証データディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\validation' |
| test_dir | テストデータディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\test' |
| train_dogs_dir | 訓練用犬画像のディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\train\dogs' |
| train_cats_dir | 訓練用猫画像のディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\train\cats' |
| validation_dogs_dir | 検証用犬画像のディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\validation\dogs' |
| validation_cats_dir | 検証用猫画像のディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\validation\cats' |
| test_dogs_dir | テスト用犬画像のディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\test\dogs' |
| test_dogs_dir | テスト用犬画像のディレクトリ | 'C:\Users\minarai\Pictures\dogs-vs-cats\base_dir\test\cats' |
では早速、始めましょう。
# 訓練画像を用意
import os, shutil
"""
データの準備
"""
# オリジナルデータ
original_dataset_dir = 'C:\\Users\\minarai\\Downloads\\dogs-vs-cats\\train'
# 機械学習用の画像を格納するディレクトリ
base_dir = 'C:\\Users\\minarai\\Pictures\\dogs-vs-cats\\base_dir'
# ディレクトリがなければ作成します
if os.path.isdir(base_dir) == False:
os.mkdir(base_dir)
# 訓練データ、検証データ、テストデータ用のディレクトリ
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
# ディレクトリがなければ作成します
if os.path.isdir(train_dir) == False:
os.mkdir(train_dir)
if os.path.isdir(validation_dir) == False:
os.mkdir(validation_dir)
if os.path.isdir(test_dir) == False:
os.mkdir(test_dir)
# 訓練用 犬、猫のディレクトリ
train_dogs_dir = os.path.join(train_dir, 'dogs')
train_cats_dir = os.path.join(train_dir, 'cats')
# ディレクトリがなければ作成します
if os.path.isdir(train_dogs_dir) == False:
os.mkdir(train_dogs_dir)
if os.path.isdir(train_cats_dir) == False:
os.mkdir(train_cats_dir)
# 検証用 犬、猫のディレクトリ
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
# ディレクトリがなければ作成します
if os.path.isdir(validation_dogs_dir) == False:
os.mkdir(validation_dogs_dir)
if os.path.isdir(validation_cats_dir) == False:
os.mkdir(validation_cats_dir)
# テスト用 犬、猫のディレクトリ
test_dogs_dir = os.path.join(test_dir, 'dogs')
test_cats_dir = os.path.join(test_dir, 'cats')
# ディレクトリがなければ作成します
if os.path.isdir(test_dogs_dir) == False:
os.mkdir(test_dogs_dir)
if os.path.isdir(test_cats_dir) == False:
os.mkdir(test_cats_dir)
# 訓練用データをコピー ※画像名は cat.i.jpg/dog.i.jpg 格納されている
for i in range(2000):
cat_file = 'cat.{}.jpg'.format(i)
dog_file = 'dog.{}.jpg'.format(i)
cat_src = os.path.join(original_dataset_dir, cat_file)
dog_src = os.path.join(original_dataset_dir, dog_file)
if i < 1000:
cat_dst = os.path.join(train_cats_dir, cat_file)
shutil.copyfile(cat_src, cat_dst)
dog_dst = os.path.join(train_dogs_dir, dog_file)
shutil.copyfile(dog_src, dog_dst)
elif i < 1500:
cat_dst = os.path.join(validation_cats_dir, cat_file)
shutil.copyfile(cat_src, cat_dst)
dog_dst = os.path.join(validation_dogs_dir, dog_file)
shutil.copyfile(dog_src, dog_dst)
else:
cat_dst = os.path.join(test_cats_dir, cat_file)
shutil.copyfile(cat_src, cat_dst)
dog_dst = os.path.join(test_dogs_dir, dog_file)
shutil.copyfile(dog_src, dog_dst)
# 画像数を確認
>>> print('total training cat images:', len(os.listdir(train_cats_dir)))
>>> print('total training dog images:', len(os.listdir(train_dogs_dir)))
>>> print('total validation cat images:', len(os.listdir(validation_cats_dir)))
>>> print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
>>> print('total test cat images:', len(os.listdir(test_cats_dir)))
>>> print('total test dog images:', len(os.listdir(test_dogs_dir)))
total training cat images: 1000
total training dog images: 1000
total validation cat images: 500
total validation dog images: 500
total test cat images: 500
total test dog images: 500
モデルの読み込み
早速、学習済みモデルを読み込んでいきます。
kerasのライブラリにインストールされているVGG16というモデルを利用します。
Kerasで利用可能なモデルはこちら「Keras>>Docs>>Applications」から確認できます。
from keras.applications import VGG16
# 学習済モデル VGG16のインスタンスを生成
conv_base = VGG16(
weights = 'imagenet', # 重みのチェックポイント箇所
include_top = False, # 全結合分類器を含めるかどうか(元のモデルは1000個のラベルに分類するモデル)
input_shape = (150, 150, 3) # 画像テンソルの形状(省略した場合はネットワークが任意に判断)
)
# モデルを確認
>>> conv_base.summary()
モデルを確認します
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
データの前処理
CNNへデータを突っ込むために画像データを4次元テンソルへ変換します。
※詳しくは「只今勉強中! 機械学習ライブラリがやっていること」を見てね。
・下記のような流れで4次元テンソルへ変換します。
1 画像ファイルを読み込む
2 JEPEG から RGBのピクセルグリッドへ変換
3 浮動小数点型のテンソルへ変換
4 ピクセル値(0-255)を0~1の範囲へ変換
# データの前処理
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
"""
1. 画像ファイルを読み込む
2. JPEGファイルをRGBピクセルグリッドにデコード
3. 浮動小数点型のテンソルに変換
4. ピクセル値(0-255)を0-1の範囲に変換する
"""
# 画像のチャネル情報を 1/255でスケーリング
datagen = ImageDataGenerator(rescale = 1./255)
batch_size = 20
def extract_features(directory, sample_count):
"""
return:
features: 訓練データの予測値が格納
labels : ラベル
"""
# 入力層
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
# 対象の画像を(batch_size, 150,150,3) (batch_size, 2) に変換
generator = datagen.flow_from_directory(directory, target_size=(150, 150), batch_size=batch_size, class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size: (i + 1) * batch_size] = features_batch
labels[i* batch_size: (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
# sample_count数分の画像の処理を終えたらループエンド
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
# 画像数 ラベル数
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
学習済みモデルのレイヤーに合わせてデータを成形
モデルのblock5_poolの後ろにモデルを追加して訓練を行っていきますので、block5_poolレイヤー用にデータの前処理を行います。
# 全結合分類用にデータを成形 ※model.suumaryの結果を参照- (None, 4, 4, 512)
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
モデルの訓練
# コンパイルと訓練a
model.compile(optimizer=optimizers.RMSprop(lr=2e-5), loss='binary_crossentropy', metrics=['acc'])
history = model.fit(
train_features,
train_labels,
epochs=30,
batch_size=batch_size,
validation_data=(validation_features, validation_labels)
)
訓練の実施
Train on 2000 samples, validate on 1000 samples
Epoch 1/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.5764 - acc: 0.6875 - val_loss: 0.4235 - val_acc: 0.8610
Epoch 2/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.4043 - acc: 0.8230 - val_loss: 0.3493 - val_acc: 0.8810
Epoch 3/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3390 - acc: 0.8620 - val_loss: 0.3164 - val_acc: 0.8790
Epoch 4/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.3127 - acc: 0.8685 - val_loss: 0.2990 - val_acc: 0.8830
Epoch 5/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2806 - acc: 0.8890 - val_loss: 0.2836 - val_acc: 0.8910
Epoch 6/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2482 - acc: 0.9025 - val_loss: 0.2831 - val_acc: 0.8800
Epoch 7/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2444 - acc: 0.9045 - val_loss: 0.2638 - val_acc: 0.8950
Epoch 8/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2238 - acc: 0.9140 - val_loss: 0.2584 - val_acc: 0.8970
Epoch 9/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2106 - acc: 0.9210 - val_loss: 0.2632 - val_acc: 0.8910
Epoch 10/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2015 - acc: 0.9185 - val_loss: 0.2503 - val_acc: 0.9010
Epoch 11/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1915 - acc: 0.9320 - val_loss: 0.2486 - val_acc: 0.9020
Epoch 12/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1786 - acc: 0.9345 - val_loss: 0.2482 - val_acc: 0.8980
Epoch 13/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1744 - acc: 0.9340 - val_loss: 0.2525 - val_acc: 0.8990
Epoch 14/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1630 - acc: 0.9420 - val_loss: 0.2440 - val_acc: 0.9020
Epoch 15/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1524 - acc: 0.9495 - val_loss: 0.2441 - val_acc: 0.9010
Epoch 16/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1489 - acc: 0.9480 - val_loss: 0.2436 - val_acc: 0.9030
Epoch 17/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1444 - acc: 0.9530 - val_loss: 0.2418 - val_acc: 0.9030
Epoch 18/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1344 - acc: 0.9580 - val_loss: 0.2419 - val_acc: 0.9050
Epoch 19/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1340 - acc: 0.9560 - val_loss: 0.2412 - val_acc: 0.9010
Epoch 20/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1282 - acc: 0.9550 - val_loss: 0.2407 - val_acc: 0.9000
Epoch 21/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1220 - acc: 0.9615 - val_loss: 0.2490 - val_acc: 0.8980
Epoch 22/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1124 - acc: 0.9630 - val_loss: 0.2494 - val_acc: 0.8990
Epoch 23/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1138 - acc: 0.9615 - val_loss: 0.2500 - val_acc: 0.8980
Epoch 24/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1027 - acc: 0.9660 - val_loss: 0.2554 - val_acc: 0.8970
Epoch 25/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1020 - acc: 0.9655 - val_loss: 0.2514 - val_acc: 0.8980
Epoch 26/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.0997 - acc: 0.9675 - val_loss: 0.2450 - val_acc: 0.9020
Epoch 27/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.0966 - acc: 0.9680 - val_loss: 0.2439 - val_acc: 0.9000
Epoch 28/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.0896 - acc: 0.9700 - val_loss: 0.2687 - val_acc: 0.8910
Epoch 29/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.0849 - acc: 0.9770 - val_loss: 0.2442 - val_acc: 0.9010
Epoch 30/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.0843 - acc: 0.9730 - val_loss: 0.2448 - val_acc: 0.9000
訓練結果を出力
# jupyterで出力するときは下記も入力
%matplotlib inline
# 訓練データをプロット
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# 正解率
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.figure()
# 損失値
plt.plot(epochs, loss, 'bo', label='Trainin Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.figure()
plt.show()
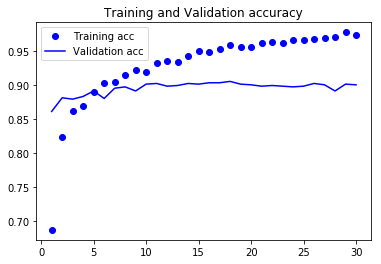
正解率をグラフで表示
損失値をグラフで表示
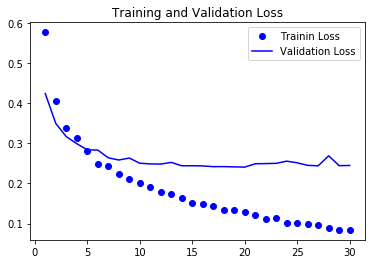
まとめ
検証結果をみると正解率は90%前後で横ばいのようです。(それでも十分に思えますが)
損失値も横ばいで過学習に陥ってるとは言い切れないですが、応用編ではさらに効率的なモデルの学習方法を紹介していきたいと思います。