導入
普段からChatGPT+に課金しGPTsを利用しているのですが、ふとせっかくなので勉強がてらAPIサーバーを自前で構築し、GPTsの機能を拡張して自分だけの最強のGPTsを作ろうと思い至りました。
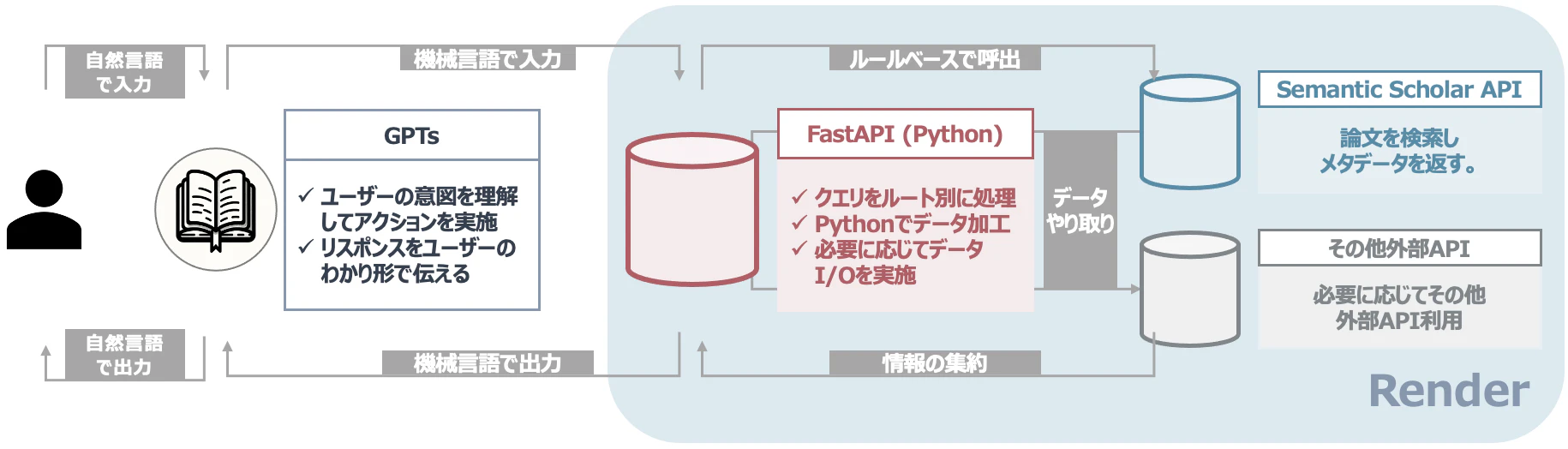
そこでこの記事ではGPTsの機能を手軽に拡張する方法について書きたいと思います。具体的には
- FastAPIを使ったAPIサーバー構築
- Renderの無料枠を使ったサーバーのデプロイ
- GPTs Actionとの連携
について見ていきます。
なお対象読書は
- GPTsには触ったことあるけどActionは利用したことない
- GPTsもアクションも触ったけど自分でAPIサーバーは建てたことない
という方を対象にしています。
そのためGPTsそのものの説明については割愛します。(僕自身今回FastAPIを触る目的で実装しています。そういう意味ではWeb開発周りは初心者なのでご了承ください、、)
この記事は概要パートと実装パートで分けているので、コードのみに興味がある方は直接実装パートに飛んでください。
【今回作るGPTについて】
今回作成するGPTは対話形式で学術論文を検索して、オープンアクセスの場合論文を読み込み内容について要約してくれる、というものです。
このGPTのポイントは(ユーザーが添付した資料経由ではなく)「Web上にあるPDFから情報を抽出できる」ことです。というのも現状のChatGPTはWebブラウジングはできてもPDFを自分で読み込む能力はないのです、、
一方で本稿の目的はあくまでも「カスタムのAPIを作ってGPTsで呼び出す」ことにあるため、今回実装する機能はさほど重要ではない(し、実用性も薄い)ことをご留意ください!
概要
この章ではGPTsとAPIの基本的な概念について見ていきます。すでに馴染みのある方はスキップして実装パートをご覧ください。
GPTs
コンセプト
さてChatGPTの有料機能であるGPTsについてはすでにさまざまな記事が書かれているので割愛しますが、端的にいうと 「対話形式でプロンプトエンジニアリングができる機能」 です。「GPT Builder」と呼ばれるアシスタントと「どのようなチャットボットを作りたいか」チャットを通じて会話をしていき、その会話の結果としてユーザーの用途に最適化された初期プロンプトが出来上がる、というイメージです。
【GPT Builderについて】
なお、GPTs Builderも一つのGPTsであり、こちらがどのようなプロンプトで作成されたかOpenAIが公開しています。プロンプトエンジニアリングの宝庫となっており非常に勉強になるのでぜひご一読を。
できること
GPTsは前述の通りチャットボットを作るためのサービスですが、所定の初期プロンプトでコンディショニングされた単なる対話だけでなく、いくつかの拡張機能を持たせることができます。
- 画像生成:OpenAIのDALL-Eを呼び出して画像を生成する機能を追加
- Webブラウジング:Bingを使ったWeb検索と検索結果の要約機能を追加
- Code Interpreter:Pythonを使った簡易的なデータ分析を実施する機能を追加
- Action:外部APIの呼び出し機能を追加
この4番目の機能が今回フォーカスしたい内容です。
GPTsにおけるこちらの「Action」とはOpenAPI形式のAPI設計書を事前に登録しておくことで、任意のタイミングでGPTsがAPIを呼び出し、返ってきた情報(JSON)を使ってチャットの返事を生成できる、というものです。OpenAIのAPIではFunction Callingと呼ばれる機能と類似しています。
API
コンセプト
さて先ほど説明したGPTsのアクションでも肝となっているAPIですが、「そもそも外部APIってなんぞや」という方に向けて簡単に説明すると、「特定のフォーマットで入力した情報(=リクエスト)に対して、特定のフォーマットで対応する情報(=レスポンス)を返す仕組み」と理解すれば良いかなと思います。
WebAPIにおいてはリクエストを投げる側はユーザーであり、貰ったリクエストを処理してレスポンスとして返すのがAPIサーバーと呼ばれるもので、両者間をインターネットが繋げています。
【APIサーバーとWebサーバー】
どこまで比喩が正しいかは保証しませんが、APIをWebブラウジングと照らし合わせるとわかりやすいかもしれません。
ChromeやEdgeなどでWeb閲覧をする場合、アドレスバーにURLを入力するとアドレスに該当するWebサーバーへとリクエストが飛び、サーバーからWebページを構成するファイル(htmlなど)がレスポンスとして返され、これらをブラウザがレンダリング(可視化)します。APIも基本的な構成はそのままで、リクエストがより動的にできる(パラメータの指定などができる)のとレスポンスがJSONを始めとした様々なファイルに対応しているイメージです。
(実際はApplication Protocol Interface と呼ぶほどなので細かいプロトコル(情報交換の仕組み)は異なるかもしれませんが、、)
外部APIにはさまざまなものが存在しますが、例えば
- 猫の種類(=リクエスト)に対して猫の画像(=レスポンス)を返すAPI
- キーワード(=リクエスト)に対して該当論文情報(=レスポンス)を返すAPI
- 文書(=リクエスト)に対して記事を作成し投稿情報(=レスポンス)を返すAPI
などなどがあります。なおAPIを活用することで「データの読み取り」だけでなく(最後の例にもあるとおり)「データの書き込み」も可能であることを留意ください。
一例として論文検索API(ここではSemantic Scholar API)を利用すると、下記のように検索キーワード(query)に「attention」と入れることで該当の論文情報を返してくれます。
Request
https://api.semanticscholar.org/graph/v1/paper/search?query=attention&fields=title,authors&limit=1
Response
{
"total": 2918761,
"offset": 0,
"next": 1,
"data": [
{
"paperId": "204e3073870fae3d05bcbc2f6a8e263d9b72e776",
"title": "Attention is All you Need",
"authors": [
{
"authorId": "40348417",
"name": "Ashish Vaswani"
},
# その他著者名が続く
]
}
]
}
【GPTsのActionについて(再)】
繰り返しになりますがGPTsのActionとは、ユーザーのメッセージから外部APIを呼び出すためのパラメータを推定し、所定フォーマットに沿ってリクエストを投げた上で、レスポンス内容をユーザーへの返信メッセージに組み込む機能にほかありません。
先の論文APIでいうと、現在ハードコーディングしているリクエストが、Actionを使うことでユーザーとの対話からGPTsが勝手に書いてくれて、尚且つそのレスポンス(JSONの中身)をチャット上で自然に返してくれる、というイメージです。
カスタムAPI
上記いくつかの外部APIを紹介しましたが、ネット上にはありとあらゆるAPIが存在する一方で、これらが必ずしも自分の実現したい要件を満たしているとは限りません。例えば僕の場合は、論文を検索してPDF文書を抽出するAPIが欲しかったのですが、Semantic Scholar APIやarXiv APIなど既存の論文検索APIではPDF文書を抽出する機能が存在しませんでした。
そのような時は自分でAPIサーバー(リクエストを処理してレスポンスを返すシステム)を構築する必要が発生します。幸いシンプルなAPIサーバーであれば構築は簡単であり、Pythonとクラウドのプラットフォームサービスを使えばすぐに実装可能です。
なお今回は比較的シンプルなAPI機能を実装しますが、サーバー上では様々なデータ処理も可能なため、複雑な機能(例えば検索した論文をNotionに保存する、など)を持たせることも可能であり、尚且つGPTsと併用することでシナジーを生み出すこともできます。
実装
実装パートでは先にAPIサーバーを構築して、次にGPTsとの連携を実施します。
APIサーバー
FastAPI
今回は比較的シンプルなAPIサーバーをクイックに実装したかったため、FastAPIを使いました。FastAPIはPythonのWebフレームワークであり、数行のコードでサーバーの構築を可能としてくれます。
FastAPIを使ったAPIサーバー構築やAPIのお作法についての記事は他にもたくさんあるためスキップします。今回は
- Request
- 検索したい論文に関する情報(キーワードやタイトル)
に対して
- 検索したい論文に関する情報(キーワードやタイトル)
- Response
- 検索に最も近しいOpen Access論文のPDF文書
を返すGETメソッドを実装します。なお論文の検索はSemantic Scholar APIを、PDFの抽出はPyPDF2を利用します。
サーバー
まずはFastAPIのスケルトンです。
from fastapi import FastAPI, HTTPException, Query
import uvicorn
app = FastAPI()
@app.get("/")
def read_root():
# ルートページ(ピング)
return {"message": "Welcome to the PaperSearch server!"}
@app.get("/search")
def search_route(query: str = Query(..., description="The query string to search for papers")):
# 検索ページ
# 入力されたキーワードをもとに論文を検索
paper = ss_search_paper(query)
if not paper:
raise HTTPException(status_code=404, detail="No papers found")
# 検索結果からPDF文書を取得し内容を抽出
full_text = fetch_and_read_pdf(paper["openAccessPdf"]["url"])
paper.update({"full_text": full_text})
# 論文情報と文書テキストを返す
return {"message": "Data processed", "result": paper}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000, log_level="info")
FastAPIの特徴として、簡単にルートを設定できるところが挙げられます。上記のコードでは127.0.0.1:8000/search へのGETリクエストに対して、@app.get("/search") デコレータを通じて search_route関数が呼び出される仕様になっています。
【パラメタ定義について】
search_routeの引数において query パラメタを定義しています(query: str = Query...)が、こちら明示的に型定義することによって後続のGPTs利用時に必要なOpen APIドキュメント作成を可能にしています。当初ここが抜けていて後続のGPT連携がうまくいかなったのでご注意を。
論文検索
次に論文検索機能です。
import requests
def ss_search_paper(query):
# リクエストクエリ
endpoint_url = "https://api.semanticscholar.org/graph/v1/paper/search/"
ss_api_params = {
"query": query,
"fields": "title,authors,year,openAccessPdf",
"openAccessPdf": "",
}
# リクエスト
ss_response = requests.get(endpoint_url, params=ss_api_params)
if ss_response.status_code != 200:
raise HTTPException(
status_code=ss_response.status_code, detail="Error in Semantic Scholar API"
)
return ss_response.json()["data"][0] # 論文一件のみ返す
ここではSemantic Scholar APIを呼び出しています。APIの使い方についてはドキュメントが詳しく書いてあるのでそちらを参照しながら書いています(無料枠であっても5分間に5,000クエリまで可能、、だが実態としては無料枠だとたまにリクエストが通らない)。
なお今回は簡単のため、キーワードに対して最も関連度の高い論文1本だけを持ってきています。
PDF抽出
最後に論文抽出機能です。
from PyPDF2 import PdfReader
from io import BytesIO
def fetch_and_read_pdf(pdf_url):
# PDFを取得
response = requests.get(pdf_url)
if response.status_code != 200:
raise HTTPException(
status_code=response.status_code, detail="Failed to fetch PDF"
)
# PDFから文書を抽出
file = BytesIO(response.content)
reader = PdfReader(file)
full_text = "".join([page.extract_text() for page in reader.pages])
full_text = full_text.replace("\n", " ")
# String型に変換した文書を返す
return full_text
ここではSemantic Scholar APIから得られたオープンアクセスPDFのURLにアクセスして、PDF文書を読み取りStringに変換しています。この「Webを通じてPDFを読み込む機能」がChatGPTの基本機能のみでは実現できない機能です。(この辺のコードはChatGPTに作ってもらいました、、最初に提案してもらったコードはPyPDF周りでバグっていましたがこれくらいならサクッといきますね)
All together
全てを一緒にしたコードはこちら。基本的に上記3つのスニペットをくっつけたのみです。
なお、後続のデプロイにおいては必須ライブラリを記述した requirements.txt も必要なので、同フォルダ内に作成しておきます。
fastapi
uvicorn
requests
pypdf2
Local Server
FastAPIを使ってサーバーのコードを書いたら、まずはローカルで走らせてみましょう。
ターミナルから
python main.py
でサーバーを起動すると、http://127.0.0.1:8000 にてアクセスできるようになります。
試しにターミナル上で curl でAPIリクエストを投げてみると
curl http://127.0.0.1:8000/search?query=yolo
下記のように論文の全文が返ってきました!
{
"message": "Data processed",
"result": {
"paperId": "a11cdd96e030ba7a4fe7f885de8c0a739af4bae6",
"title": "A Comprehensive Review of YOLO: From YOLOv1 to YOLOv8 and Beyond",
"year": 2023,
"openAccessPdf": {
"url": "https://arxiv.org/pdf/2304.00501",
"status": "GREEN"
},
"authors": [
{
"authorId": "3161727",
"name": "Juan R. Terven"
},
{
"authorId": "2858806",
"name": "Diana Margarita Córdova Esparza"
}
],
"full_text": "A COMPREHENSIVE REVIEW OF YOLO A RCHITECTURES IN COMPUTER VISION : FROM YOLO V1TOYOLO V8AND YOLO-NAS PUBLISHED AS A JOURNAL PAPER AT MACHINE LEARNING AND KNOWLEDGE EXTRACTION Juan R. Terven Instituto Politecnico Nacional CICATA-Qro Diana M. Cordova-Esparza Universidad Autónoma de Querétaro Facultad de Informática ABSTRACT YOLO has become a central real-time object detection..."
# 以下論文の内容数ページ分が続く
}
}
Cloud Server
さて次はこのサーバーをインターネット上からアクセスできるようにクラウドにデプロイします。
昨今ではサーバー・ストレージ等インフラ提供からデプロイまで一貫して実施してくれるサービス(PaaS)がいくつかあるのですが、今回は無料枠が存在しておりFastAPIも公式にサポートしているRenderを使おうと思います。(少し前までは無料枠の充実しているPaaSといえばherokuだったのですが、無料枠がなくなってしまったので、、)
前提条件
大前提としてGitHubのアカウントを持っており、先ほど作成したコードがリポジトリとしてアップロードされている必要があります。なおリポジトリはPublicであっても、Privateであっても構いません。
リポジトリを作るのが面倒・とりあえず回してみたい方は、僕が今回のブログ用に作成したリポジトリをクローンいただければと思います。
アカウント発行
まずはRenderでアカウントを発行します。後々Githubリポジトリを連携するのでGitHubアカウントから発行するのがおすすめです。
APIサーバー構築
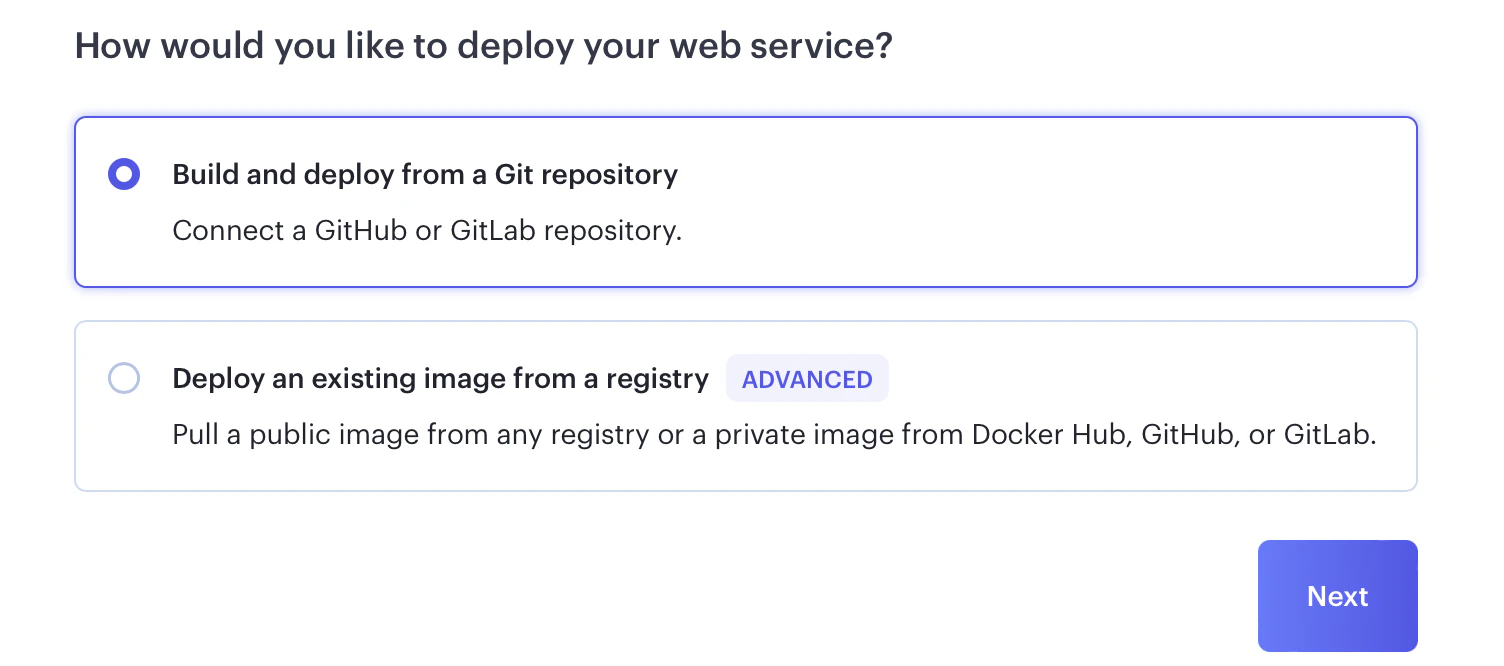
ログイン後、ページ上部にある「New +」をクリックして「Web Service」を選びます。

またデプロイの仕様としては「Gitリポジトリからデプロイする」を選択します。
サインアップ時にGitHubアカウントを連携していなかった場合、こちらの前後のタイミングでアカウント連携が必要になります。アクセス権限は「All repositories」に設定するのが楽かと思います。
連携がうまくいくとGitHubのリポジトリが表示されるため、今回新たに作ったAPIサーバーのソースコードがあるリポジトリを選択します。
リポジトリを選択するとデプロイ設定のページが開きますが、基本的にはデフォルト値のままで大丈夫です。
ただし Start Command は下記のとおり設定のうえ、Instance Type の無料枠(Free)を設定してください。
uvicorn main:app --host 0.0.0.0 --port $PORT
あとはデプロイするのみです!ページ下部の Create Web Service でAPIサーバーを世に出します!
デプロイ
デプロイを実行するとWebアプリケーションのダッシュボードページに遷移します。
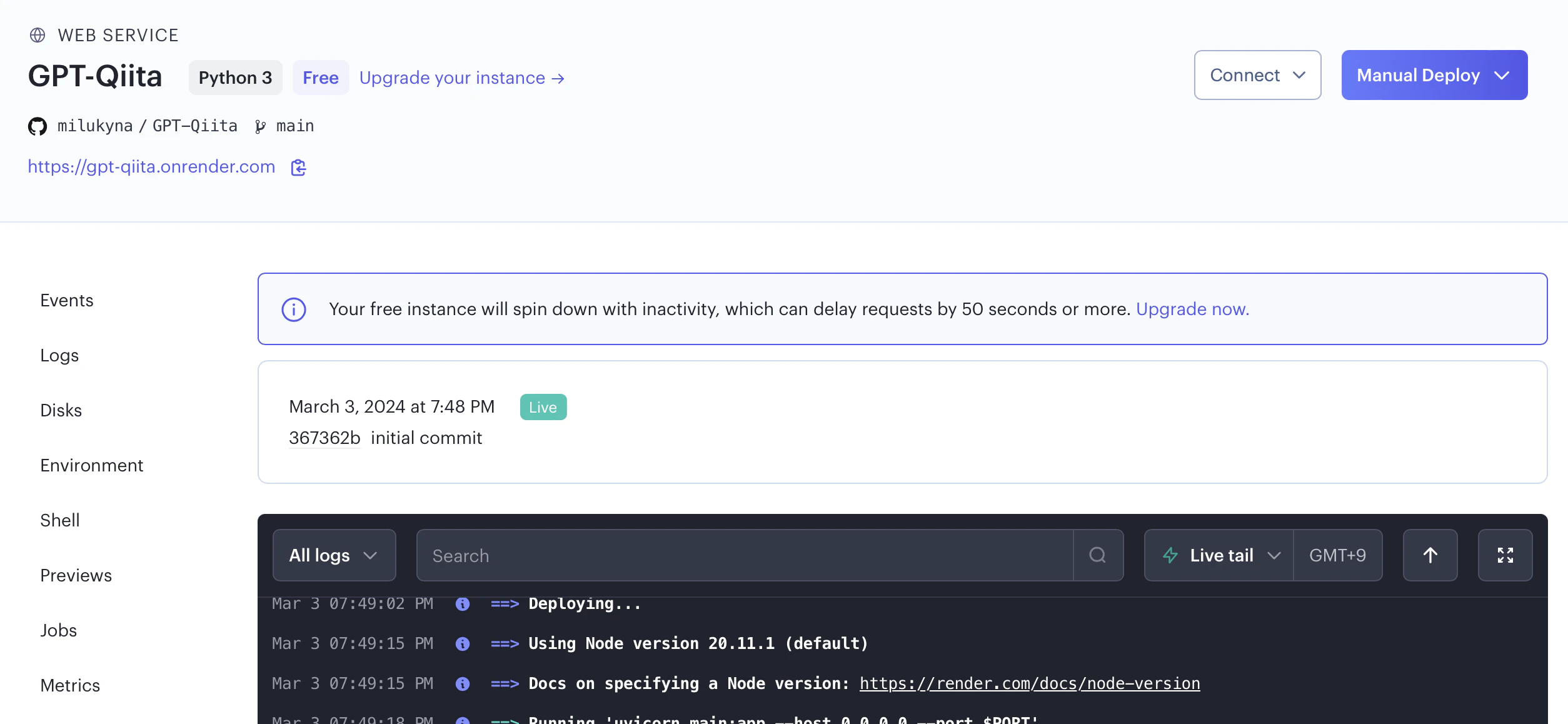
ここまでの設定を正しく進めていれば、ビルドにしばらく時間をかけたのちにデプロイが完了するはずです(ロギング画面で Your Service is live 🎉 と表示されていればOkです)。
ページ上記にあるリンクがAPIのエンドポイントとなっている(https://gpt-qiita.onrender.com)ので、試しにブラウザで打ってみましょう。
先ほどローカル環境で実行した時と同じレスポンスが返ってきました!

これでAPIサーバーの構築は終了です。
なお、Renderではデフォルトで Auto Deploy がオンになっているので、GitHub上の main ブランチにコミットすれば自動で最新コードを再デプロイしてくれます。
GPTs
続いてGPTsの作成です。今回GPTsの基本的な作り方については端折って(例えばこちら)前項で作成したAPIサーバーとの連携に集中したいと思います。
API仕様書の取得
API仕様書とは読んで字の如くAPIの設計書を指しているのですが、こちらはFastAPIで作ったサーバーなら簡単に取得することができます!
先ほどRenderでデプロイしたAPIサーバーのURLに /docs と追加してブラウザからアクセスするのみです。僕の場合だと現在APIサーバーは https://gpt-qiita.onrender.com にデプロイされているので、https://gpt-qiita.onrender.com/docs にアクセスします。すると下記のようなページに遷移するはずです。
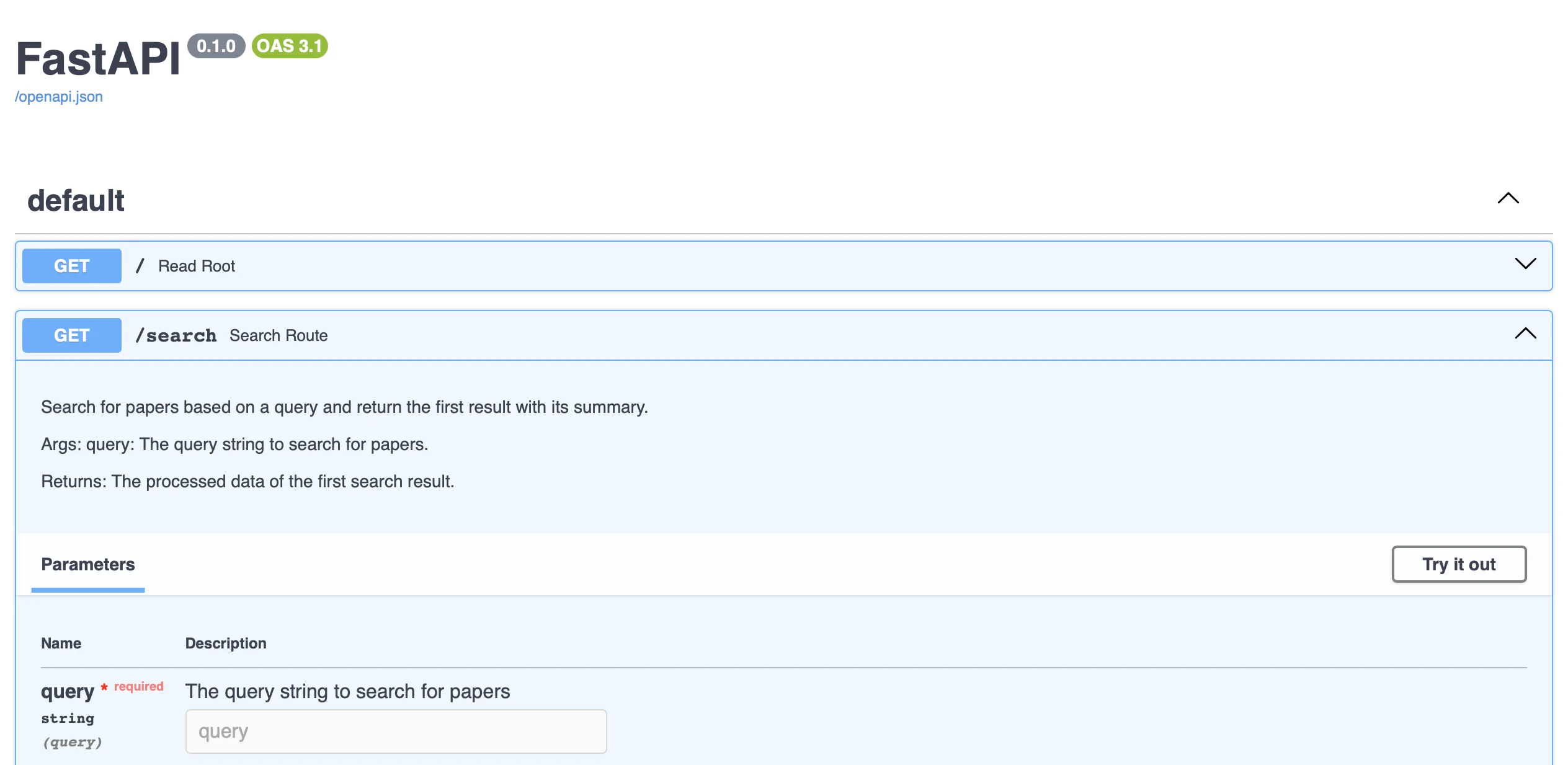
こちらが我々のAPIサーバーの仕様書であり、上部にある /openapi.json をクリックするとOpenAPI仕様書が表示されます。

Actionの設定
あとはこちらをGPTのActionの箇所にコピペするのみです。新規のGPTの作成画面を開くと Configure タブ下部にある Create new action を選択します。
すると Enter your OpenAPI shema here という枠が出てくるのでこちらに先ほどのAPI仕様書をコピペします。
が、一点だけ追加しなければならない行があります。 FastAPIから得たデフォの仕様書だとサーバーの所在地(URL)が欠けているので、そちらを追記します。
"servers": [
{
"url": "https://gpt-qiita.onrender.com"
}
]
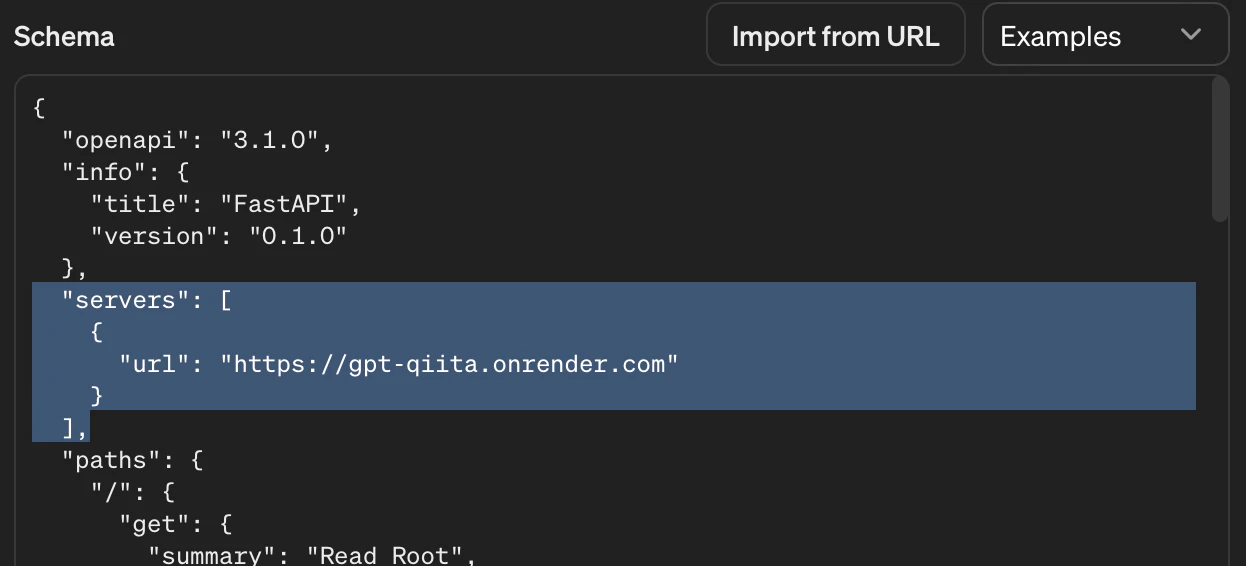
さてこれでActionの準備が整いました。試しにTest ボタンを押してGETが上手くいくか確認しましょう。
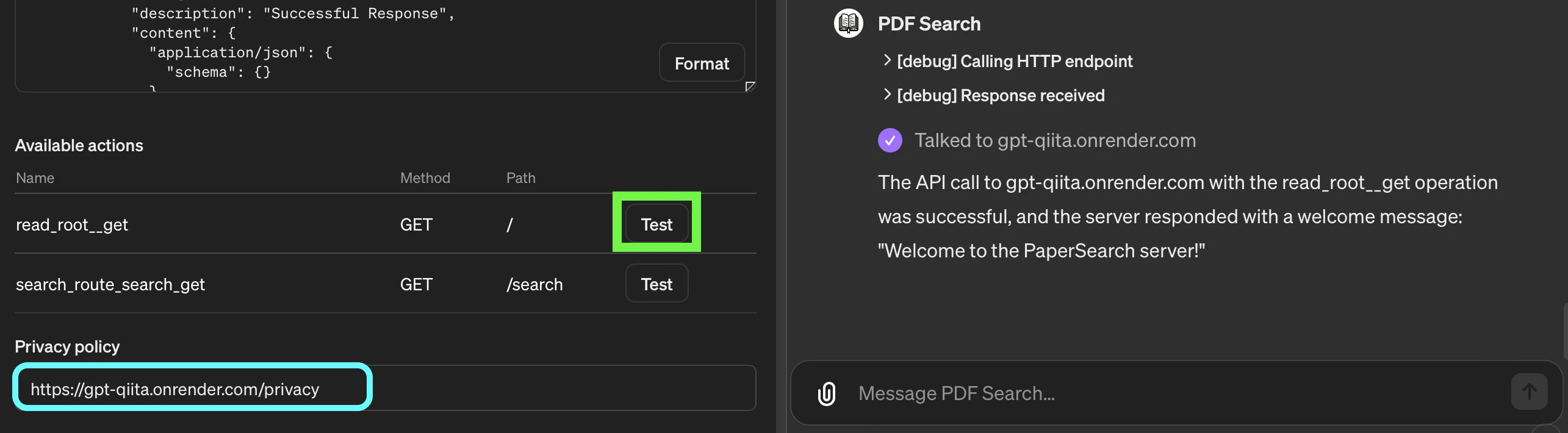
【Privacy Policyについて】
上記スクショ水色の枠で囲ってある Privacy Policy の枠ですが、GPTを公開するためにはこちらを埋める必要があるので、適当なURLを入れてください。
GPTの設定
GPTの設定はさほど重要ではないため今回は端折ります。今回は単純にユーザーとの会話で必要に応じてAPIを利用し結果をいくつかの観点で表にまとめるよう設定しました。

Action in GPT in Action
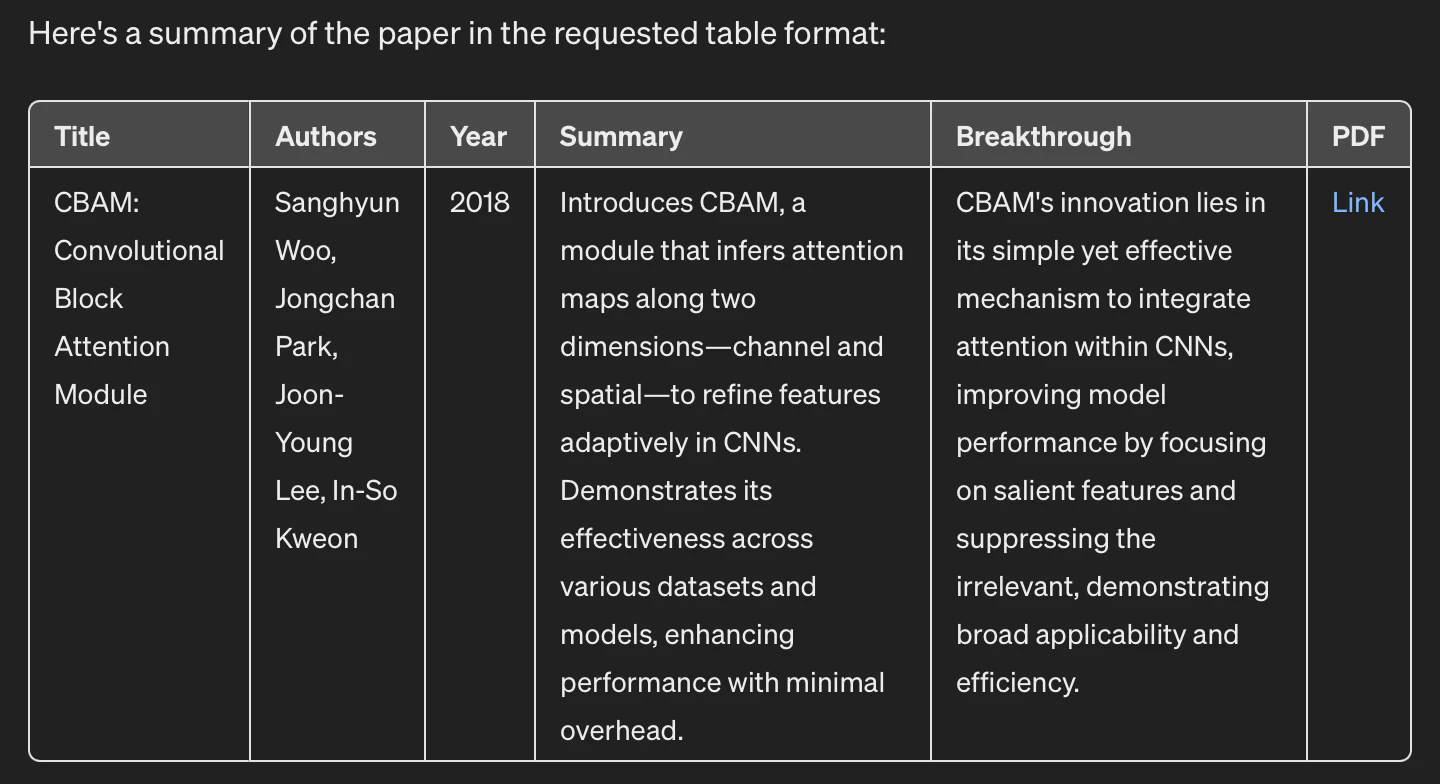
最終的に完成したGPTsがこちらです!
できることは非常に限られているのですが、論文を探すことを促すと検索した上で論文内容を読み込みテーブルにまとめ、必要に応じて中身についての質問に答えてくれます。

【PDF Searchの利用について】
繰り返しになりますが、今回は実装方法のデモを目的としています。作成したGPTの活用性は低く(例えば文書丸ごと返すので長すぎるとGPTで対処しきれずエラーが出るなど、、RAG実装の機運)、なおかつSemantic Scholar側のAPI仕様からリクエストが通らないケースもたまにあるのでご了承ください。
まとめ
GPTsとFastAPI並びにRenderを利用することで、誰でも無料で簡単に機能性豊かなチャットボットを作成するプロセスを紹介しました!
GPTsにAction機能を持たせることで様々な応用が効くことを感じてもらえたら幸いです!今回は初歩的な機能の実装に留まりましたが、自前のAPIサーバを構築すれば単一論文を検索して要約するだけでなく、複数論文の検索とそれぞれの比較や、ユーザーの入力に応じてデータベースへの保存、なども考えられます。(余談ですが僕はGPTのActionでOpenAIのAPIを呼び出してMulti-Agentsの実装など試みました、、)
APIサーバの作成は意外にシンプルなのでこの機にぜひお試しください!