概要
ASMR動画では、以下のような「一瞬だけ入るノイズ」が問題になります。
- マイクにぶつかった音
- マイクスタンドのきしみ
- 床のきしみ
これらは短時間かつ突発的であり、通常のノイズ除去では対応が難しいです。
一方で、
- PCファン音などの定常ノイズ
は、例えば noisereduce などのライブラリで除去できます。
→ 本記事では
ASMRの音は残しつつ、一瞬のノイズだけを検出してカットする方法を紹介します。
やりたいこと
ノイズが鳴っている時間を検出する
入力
- 未編集のASMR音声
出力
- ノイズが鳴っている部分のタイムスタンプ
- (その区間をカットして、短めのクロスフェードで結合する)
アプローチの核心
ノイズには以下の特徴があります:
- 周囲と比べて「異常な周波数成分」を持つ
- 左右のチャンネルに同時に現れやすい
これを数値化します。
手法
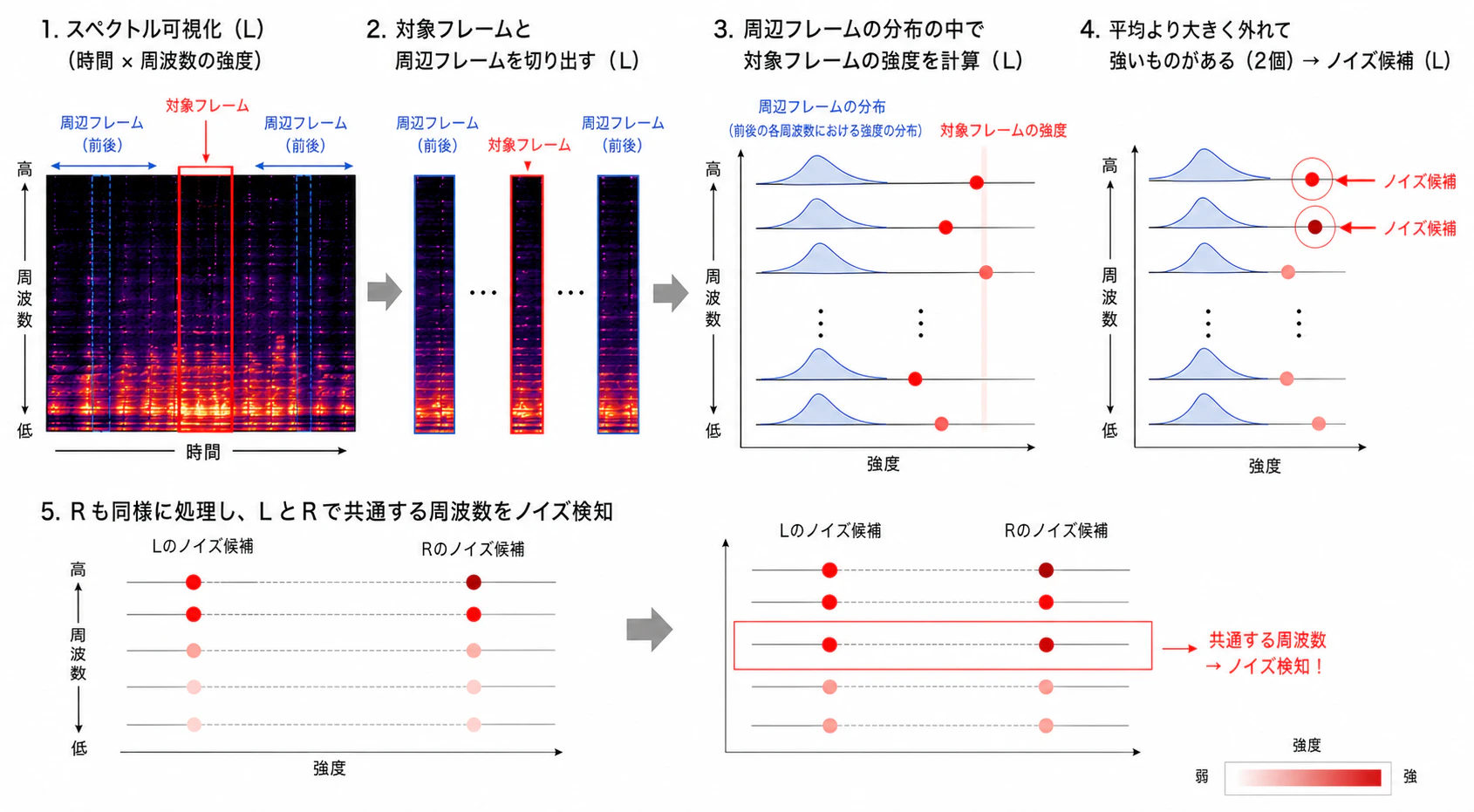
① 周波数ごとのZスコアを計算
あるフレームにおける周波数成分が
「周囲と比べてどれくらい異常か」を測ります。
$$
z = \frac{x - \mu}{\sigma}
$$
- $x$:対象フレームの周波数強度
- $\mu$:周囲フレームの平均
- $\sigma$:周囲フレームの標準偏差
→ Zスコアが大きいほどレアな音
② ステレオで共通する異常を強調
まず、周波数ごとのZスコアに対して、負の値を切り捨てる:
$$
z' = \max(z, 0)
$$
→ 平均より小さい成分(よくある音)は無視し、異常に大きい成分のみを残す
その上で、左右チャンネルで共通する異常を強調する:
$$
z_{LR} = z'_L \times z'_R
$$
→ 左右で同時に大きい周波数成分のみが強く残る
→ 片側だけのASMR音を除外しやすい
③ スコア化
周波数ごとの $z_{LR}$ をサマってスコアにする。
top_kで異常周波数を取り出し平均する
$$
score = \text{TopK平均}(z_{LR})
$$
④ 判定
- score ≥ 300 → ノイズ候補
- score ≥ 1000 → ほぼ確実にノイズ
成功した手法
ポイント
- 周囲と比較してレアな周波数を検出
- それが左右共通ならノイズとみなす
処理の流れ
- STFTで周波数解析
- 各フレームについて周囲と比較してZスコアを算出
- 左右チャンネルで共通する成分を強調
- 上位周波数の平均でスコア化
- 閾値以上をノイズとして検出
- 近い区間をマージ
import librosa
import numpy as np
import pandas as pd
from tqdm import tqdm
# 周辺と比較して周波数ごとにZスコア(∝偏差値)を算出する
# return [0HzのZスコア, 23HzのZスコア, ... 23953HzのZスコア]
def calc_freq_z(stft, f, freq_window_frame, max_duration_frame):
stft_other = np.concatenate([
stft[:, f-freq_window_frame:f-max_duration_frame],
stft[:, f+max_duration_frame:f+freq_window_frame]
], axis=1)
stft_f = stft[:, f]
# 周波数ごとにzスコアを出す(偏差値=50+10*z)
mean = np.mean(stft_other, axis=1) # 平均
std = np.std(stft_other, axis=1) # 標準偏差
z = (stft_f - mean) / (std + 1e-8) # Zスコア
return np.maximum(z, 0)
# 瞬間ノイズ除去メインフロー
def detect_noise(
wav_path,
hop_length=512, # STFTのフレームサイズ
freq_window_sec = 5, # 前後5秒の中でレアな音が異音の候補
max_duration_sec = 0.5, # 単発ノイズが発生する時間の最大値
top_k=2, # 異常周波数上位k個の平均で判断する
threshold=300, # 大きくすると検出されるノイズが少なくなる
merge_interval_sec= 2.0, # merge_interval_sec秒以内なら結合
noise_max_n=50, # ノイズの個数上限
):
# --- ① 解析 ---
y, sr = librosa.load(wav_path, sr=None, mono=False)
if y.ndim == 1:
raise ValueError("ステレオ音声が必要です")
print(" 音声解析中")
L, R = y
# STFT
stft_L = np.log1p(np.abs(librosa.stft(L, hop_length=hop_length)))
stft_R = np.log1p(np.abs(librosa.stft(R, hop_length=hop_length)))
total_frame = len(stft_L[0])
# --- ② ノイズ確度スコア算出 ---
freq_window_frame = int(freq_window_sec * sr / hop_length)
max_duration_frame = int(max_duration_sec * sr / hop_length)
print(" ノイズ確度スコア算出")
stereo_freq_scores = np.full(total_frame, np.nan)
for f in tqdm(range(freq_window_frame, total_frame - freq_window_frame - 1)):
# 前後5秒と比較して周波数ごとにZスコア(∝偏差値)を算出する。レアだとZスコアが大きくなる
z_L = calc_freq_z(stft_L, f, freq_window_frame, max_duration_frame)
z_R = calc_freq_z(stft_R, f, freq_window_frame, max_duration_frame)
# 左右に共通するノイズを強調する
z_LR = z_L * z_R
# レア周波数ランキングのトップ2を平均してスコアとする
stereo_freq_scores[f] = np.mean( np.sort(z_LR)[-top_k:] )
score_df = pd.DataFrame({
"start_time": (np.arange(total_frame)) * hop_length / sr,
"end_time": (np.arange(total_frame) + 1) * hop_length / sr,
"stereo_freq": stereo_freq_scores
})
# スコアが大きいものをノイズと判定する
score_df = score_df[score_df["stereo_freq"] >= threshold]
if score_df.empty:
print(" ノイズ検出完了(検出なし)")
return pd.DataFrame(columns=["start_time", "end_time", "stereo_freq"])
# --- ③ 連続ノイズをマージ ---
merged = []
cur = score_df.iloc[0]
for i in range(1, len(score_df)):
row = score_df.iloc[i]
# 間隔がmerge_interval_sec秒以内なら結合
if row["start_time"] - cur["end_time"] <= merge_interval_sec:
cur["end_time"] = row["end_time"]
cur["stereo_freq"] = max(cur["stereo_freq"], row["stereo_freq"])
else:
merged.append(cur.copy())
cur = row.copy()
# 最後を追加
merged.append(cur.copy())
merged_df = pd.DataFrame(merged)
# 最大個数でフィルタ
max_n_threshold = merged_df["stereo_freq"].nlargest(noise_max_n).iloc[-1]
merged_df = merged_df[merged_df["stereo_freq"] >= max_n_threshold]
print(" ノイズ検出完了")
return merged_df
if __name__ == "__main__":
import sys
results = detect_noise(sys.argv[1])
print(results)
結果と所感
この手法の良い点:
- ASMR音をほぼ壊さない
- 瞬間ノイズに強い
- パラメータ調整で精度を制御可能
特に、
→ 「周囲との差」+「ステレオ共通性」
この2つを組み合わせたのが効きました。
まとめ
ASMRのノイズ除去は、
- 定常ノイズ → フィルタで除去
- 瞬間ノイズ → 検出してカット
と分けて考えるのが重要です。
今回の方法は後者に特化したアプローチです。
実用のコツ
- thresholdは300〜1000で調整
- ノイズの検知量の調整
- top_kは2〜5あたりが安定
- ノイズの音色による。正弦波に近い音色であれば小さく、ホワイトノイズに近い音色であれば大きくする。
- merge_intervalを長くすると編集しやすい
- 短期間にカットが多すぎると感じたら長くする
おまけ(試したけどダメだった方法)
スペクトルフラックス
方法
- STFTでスペクトログラムを計算
- 隣接フレーム間の差分を取る
- その差分の大きさ(フラックス)を計算
- 平滑化(移動平均)してノイズを除去
- ローカル平均との差を取り、急激な変化を強調
- 閾値以上をイベント(ノイズ候補)として抽出
→ 「急に音が変わった瞬間」を検出する手法
問題点
- ASMRはもともと細かい変化が多い
- ささやき・タッピング・衣擦れなども検出される
- ノイズとASMRの区別がつかない
→ 検出はできるが、判別精度が低い
左右の音量差
方法
- 左右チャンネルの音量(RMSや振幅)を計算
- 左右差(|L - R|)を算出
- 差が小さい箇所をノイズ候補とする
→ ノイズは左右対称に入るという仮説
他のスコアと併用して使う前提
問題点
- ノイズが入っても、もともとのASMR音に重なるため差が出にくい
- 「ASMRのみ」と「ASMR+ノイズ」で左右差に明確な変化が出ない
→ 指標として成立しない
MFCC + k-means
方法
- 音声を短時間フレームに分割
- 各フレームからMFCC(音の特徴量)を抽出
- k-meansでクラスタリング
- 出現数の少ないクラスタを「異常(ノイズ)」とみなす
→ ノイズは出現頻度が低いという仮説
問題点
- ASMR音もバリエーションが豊富でクラスタが分散する
- レアなASMR音(例えば特殊なトリガー音)がノイズ扱いされる
- クラスタ数kの調整に強く依存する
→ 「レア=ノイズ」とは限らない
MFCC + IsolationForest
方法
- MFCC特徴量を抽出
- IsolationForestで外れ値検出
- 外れ値スコアが高いフレームをノイズとみなす
→ ノイズは統計的に外れ値になるという仮説
問題点
- ASMR音も外れ値になりやすい
- 時系列情報を無視している
- ノイズの「短時間性」が考慮されていない
→ k-meansより若干弱い印象