環境
tensorflow == 2.2.0
keras == 2.3.1
(2020.6.10現在のGoogleColabのdefaultのversion)
コード
githubに全コードがのっています。
https://github.com/milky1210/Segnet
記事内のコードは抜粋なので実際に動かしたい方はコードのダウンロードをお願いします。
SegNetの論文の内容を要約

要旨
SEMANTIC segmentation と呼ばれる画像の各ピクセルに対して何が映ったピクセルなのかというラベルをDeep learning によって推論を行う問題においてPooling などによって低解像度になった特徴マップを元の次元に復元する上で正確な境界線にマッピングを行うモデルを提案する。

他の研究との差分
SegNet は通常のFCNのように画像を畳み込み層とpooling層で解像度を小さくしたのちにUpSampling を行っているが解像度をあげるときにpooling indiceと呼ばれる手法を用いて境界が不鮮明になることを防いでいる。
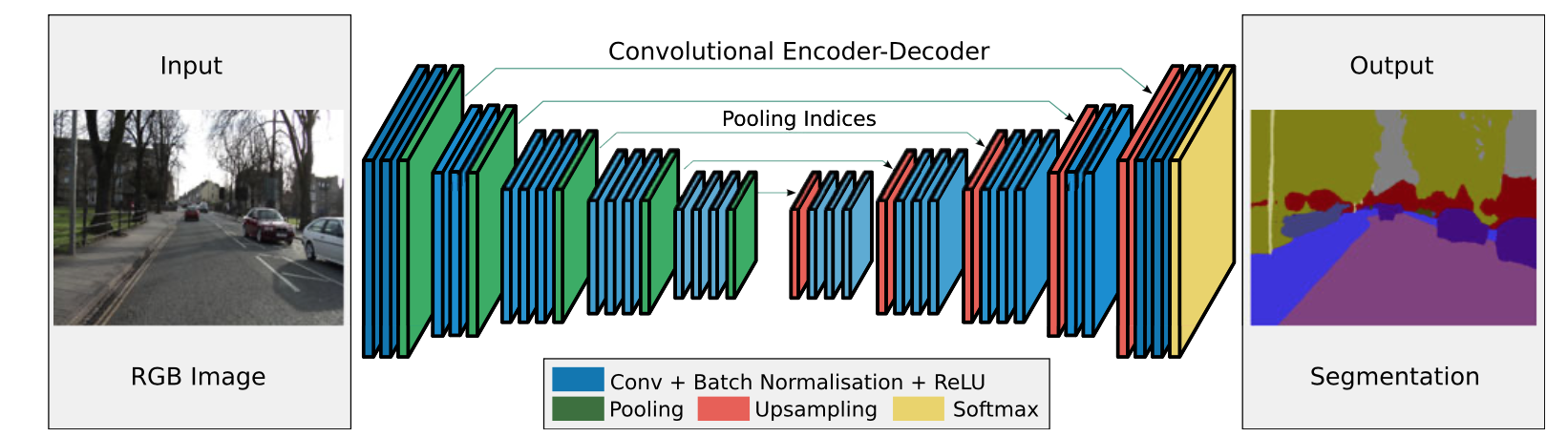
ここでEncodeやDecodeにはVGG16のモデル(画像分類で有名なモデル)の形を継承している。
Pooling indices
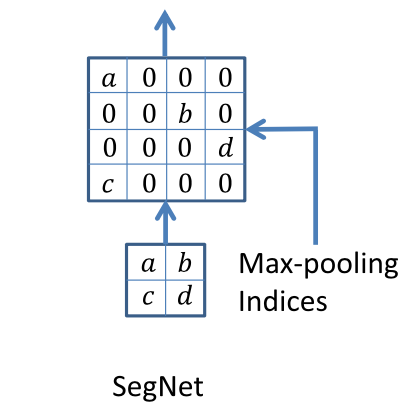 この図のようにMax Poolingを行ったときにMaxがどこにあったかを覚えておき、UpSamplingの時にその位置に各特徴マップをうつすというものである。
この図のようにMax Poolingを行ったときにMaxがどこにあったかを覚えておき、UpSamplingの時にその位置に各特徴マップをうつすというものである。
性能をVOC12を用いて比較
VOC12とは
SegNetの論文内でも性能の検証のために用いられている画像認識や画像検知、セグメンテーションなどの問題をサポートしているデータセットである。
ここからダウンロードできる。
ダウンロードするとVOCdevkit/VOC2012/の中にJPEGImages/とSegmentationObject/が入っておりJPEGImageを入力画像、SegmentationObjectを出力画像として訓練、検証を行う。
それぞれのディレクトリでJPEGImages/~.jpgと SegmentationObject/~.pngが対応している。背景、境界を含めて22クラス分類を行う。
実装
記事内ではモデルの定義と損失関数の定義、訓練のみ取り上げる。
また、訓練、検証は64x64の解像度で行う。
モデル定義
まず比較対象としてpooling indice のないSegNet(Encoder-decoder)をVGG16の形を模すと以下のようになる。
def build_FCN():
ffc = 32
inputs = layers.Input(shape=(64,64,3))
for i in range(2):
x = layers.Conv2D(ffc,kernel_size=3,padding="same")(inputs)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.MaxPooling2D((2,2))(x)
for i in range(2):
x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.MaxPooling2D((2,2))(x)
for i in range(3):
x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.MaxPooling2D((2,2))(x)
for i in range(3):
x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.MaxPooling2D((2,2))(x)
for i in range(3):
x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.UpSampling2D((2,2))(x)
for i in range(3):
x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.UpSampling2D((2,2))(x)
for i in range(3):
x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.UpSampling2D((2,2))(x)
for i in range(2):
x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.UpSampling2D((2,2))(x)
for i in range(2):
x = layers.Conv2D(ffc,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Conv2D(22,kernel_size=3,padding="same",activation="softmax")(x)
return models.Model(inputs,x)
vgg16を模した形にするとこのような構造となり、24層の畳み込み層を持つネットワークとなる。ここで、MaxPooling2Dによって画像を小さくし、UpSampling2Dを用いて画像を大きくしていることに注意する。
次にSegnetとこのモデルの差分をみていく。
まずSegnetはMaxPooling2Dを行う前に以下のようにしてその層でのArgMaxPooling2Dに相当する情報を保持しておく。
この関数はKerasにはなくtensorflowのものを利用する。
よって、オリジナルのKeras Layerを作成する必要がある。
以下のように関数を定義するとKeras上で動くlayerとなる。
class MaxPoolingWithArgmax2D(Layer):
def __init__(self):
super(MaxPoolingWithArgmax2D,self).__init__()
def call(self,inputs):
output,argmax = tf.nn.max_pool_with_argmax(inputs,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
argmax = K.cast(argmax,K.floatx())
return [output,argmax]
def compute_output_shape(self,input_shape):
ratio = (1,2,2,1)
output_shape = [dim//ratio[idx] if dim is not None else None for idx, dim in enumerate(input_shape)]
output_shape = tuple(output_shape)
return [output_shape,output_shape]
次にUpSamplingを行う時にargmaxであった場所に戻すLayerを定義する(こちらはかなり長め)
class MaxUnpooling2D(Layer):
def __init__(self):
super(MaxUnpooling2D,self).__init__()
def call(self,inputs,output_shape = None):
updates, mask = inputs[0],inputs[1]
with tf.variable_scope(self.name):
mask = K.cast(mask, 'int32')
input_shape = tf.shape(updates, out_type='int32')
# calculation new shape
if output_shape is None:
output_shape = (input_shape[0],input_shape[1]*2,input_shape[2]*2,input_shape[3])
self.output_shape1 = output_shape
# calculation indices for batch, height, width and feature maps
one_like_mask = K.ones_like(mask, dtype='int32')
batch_shape = K.concatenate([[input_shape[0]], [1 ], [1], [1]],axis=0)
batch_range = K.reshape(tf.range(output_shape[0], dtype='int32'),shape=batch_shape)
b = one_like_mask * batch_range
y = mask // (output_shape[2] * output_shape[3])
x = (mask // output_shape[3]) % output_shape[2]
feature_range = tf.range(output_shape[3], dtype='int32')
f = one_like_mask * feature_range
# transpose indices & reshape update values to one dimension
updates_size = tf.size(updates)
indices = K.transpose(K.reshape(
K.stack([b, y, x, f]),
[4, updates_size]))
values = K.reshape(updates, [updates_size])
ret = tf.scatter_nd(indices, values, output_shape)
return ret
def compute_output_shape(self,input_shape):
shape = input_shape[1]
return (shape[0],shape[1]*2,shape[2]*2,shape[3])
これらによって定義されたLayerを用いてSegnetを定義すると以下のようになる。
def build_Segnet():
ffc = 32
inputs = layers.Input(shape=(64,64,3))
for i in range(2):
x = layers.Conv2D(ffc,kernel_size=3,padding="same")(inputs)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x,x1 = MaxPoolingWithArgmax2D()(x)
for i in range(2):
x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x,x2 = MaxPoolingWithArgmax2D()(x)
for i in range(3):
x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x,x3 = MaxPoolingWithArgmax2D()(x)
for i in range(3):
x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x,x4 = MaxPoolingWithArgmax2D()(x)
for i in range(3):
x = layers.Conv2D(ffc*8,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Dropout(rate = 0.5)(x)
x = MaxUnpooling2D()([x,x4])
for i in range(3):
x = layers.Conv2D(ffc*4,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = MaxUnpooling2D()([x,x3])
for i in range(3):
x = layers.Conv2D(ffc*2,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = MaxUnpooling2D()([x,x2])
for i in range(2):
x = layers.Conv2D(ffc,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = MaxUnpooling2D()([x,x1])
for i in range(2):
x = layers.Conv2D(ffc,kernel_size=3,padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Conv2D(22,kernel_size=3,padding="same",activation="softmax")(x)
return models.Model(inputs,x)
損失関数と最適化
今回損失関数は各ピクセルのクロスエントロピーを利用した。
また、最適化はAdam(lr=0.001, beta_1=0.9, beta_2=0.999)を用いた。
結果
pooling indiceの有無によってどの程度結果に変化が出るかを確認した。
トレーニング内でのloss,各ピクセルでの正答率の平均をグラフにした。
まずPooling Indice の無いモデルの結果
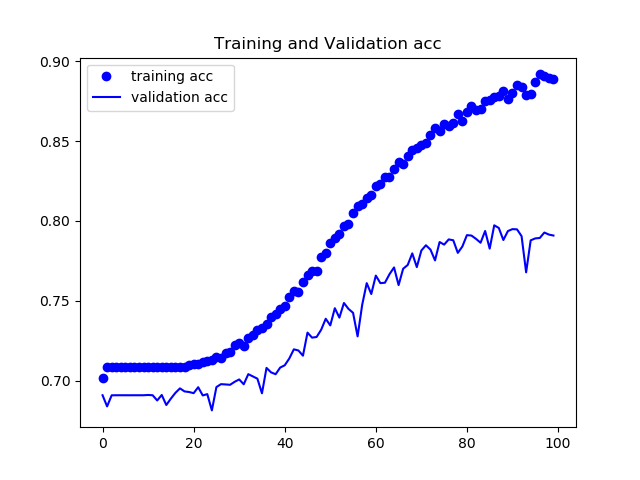
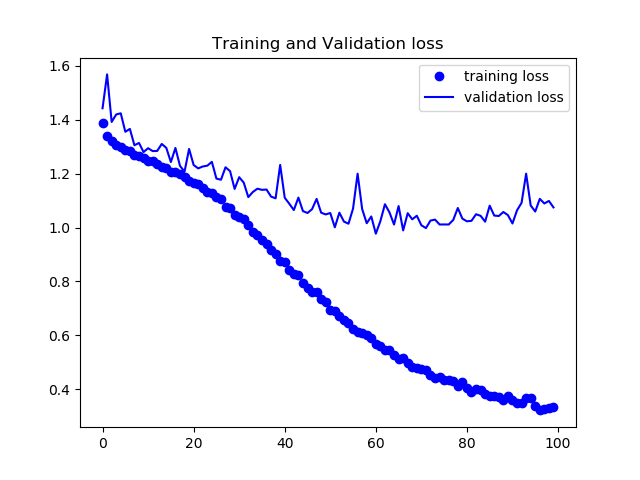
検証データは78%程度の正答率となった。
次にSegNetの結果を載せる。
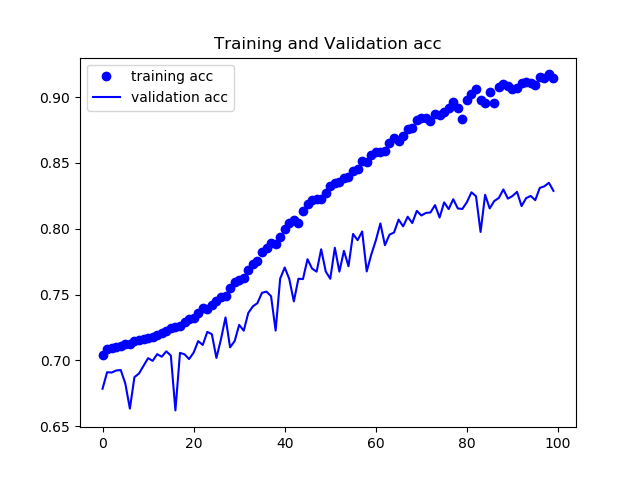
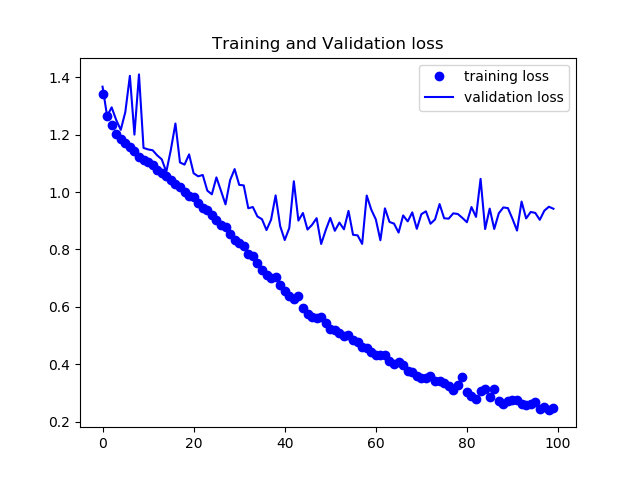
正答率82%程度で安定し、論文通りの挙動を見ることができた。
出力画像例
左から入力、Pooling Indice なし、SegNet、GTで全てテストデータ
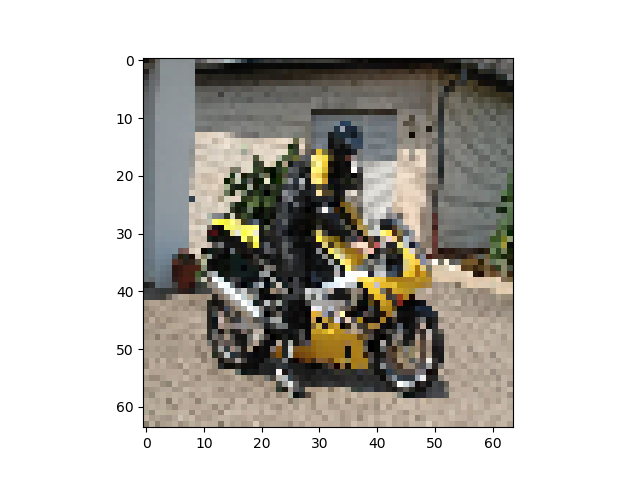
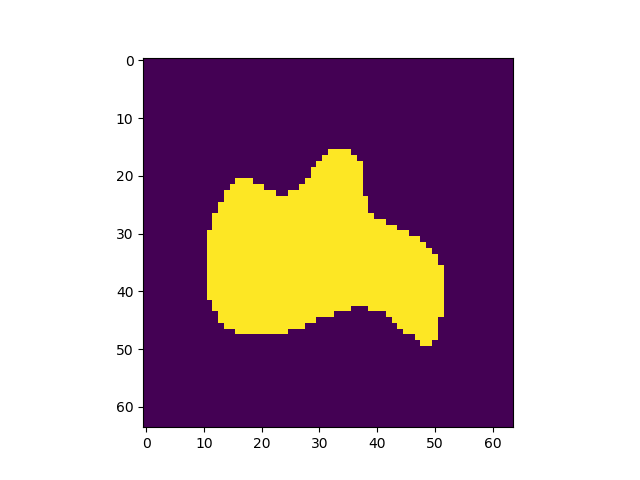

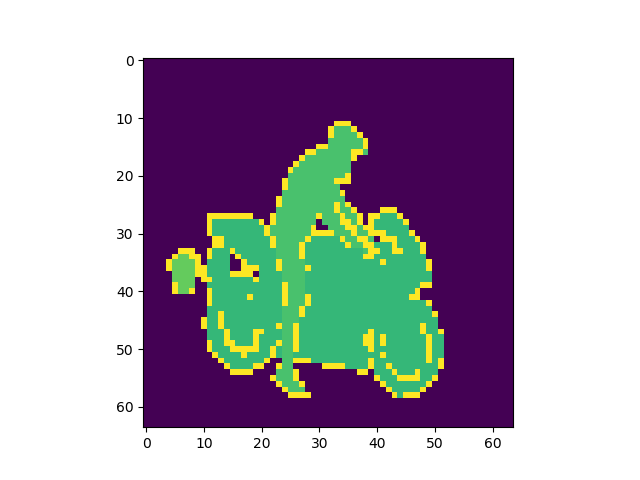

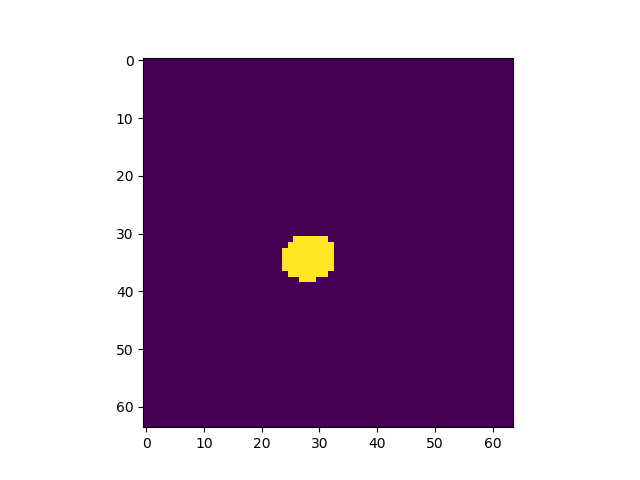
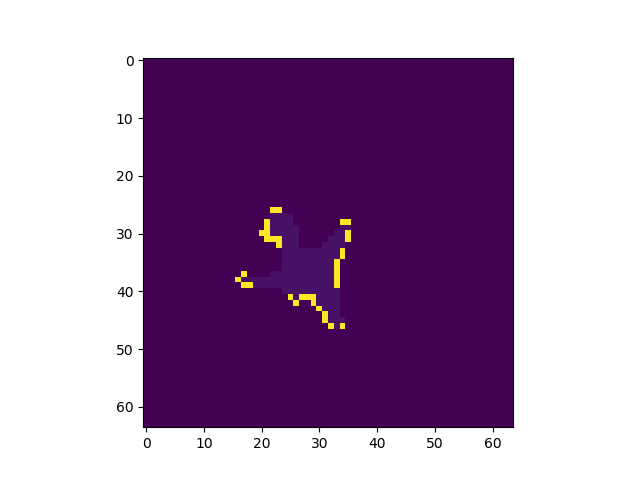
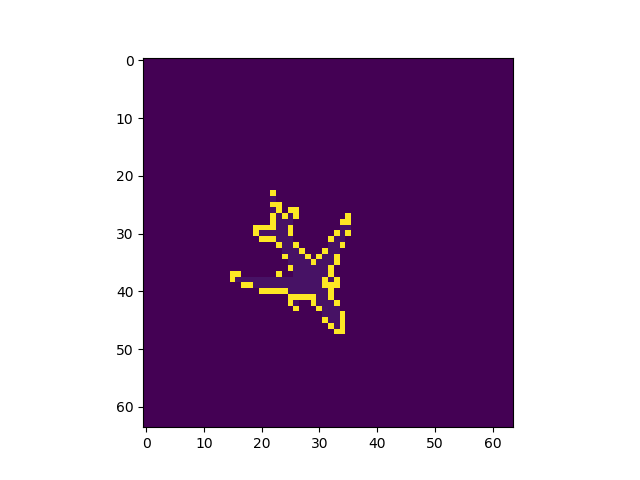
Pooling Indiceを保持することでかなり精度の向上を見込めることがわかった。