はじめに
Apache POIを使用してExcelを読み込む際、取消線のあるセルや非表示のセルは飛ばしたいと思い、その方法を調べてみました。
自身のメモとして記載しますがよければ参考にしてください。
※基本的なApache POIの書き方は割愛します。
もくじ
1. 非表示行列
非表示(または幅を0)にした行・列のデータを読み込まないようにします。
※今回初めて知りましたが、Excelの行・列の幅を0にすると、非表示と同じ扱いになるようです。
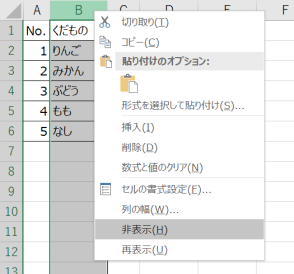
1. 非表示行の判定
行が非表示になっているかの判定を行います。
for(Row row : sheet){
// 行が非表示か判定
if(row.getZeroHeight()){
// 非表示の場合、次の行を読み込む
continue;
}
...
}
2. 非表示列の判定
列が非表示になっているかの判定を行います。
Apache POIではブック➡シート➡行➡列で読み込んでいくので、
列の場合セル単位での判定が必要です。
また、列はCellクラスに非表示判定がないためSheetクラスにて判定処理を記載する必要があります。
for(Cell cell : row){
// 列が非表示か判定
if(sheet.isColumnHidden(cell.getColumnIndex())){
// 非表示の場合、次のセルを読み込む
continue;
}
...
}
※この処理は全てのセルにて、毎回判定するようになっていますが、データ量の多いファイルや複数ファイルを一度に多量に読み込む場合は、処理がかなり遅くなります。多量のデータを扱う場合は列番号をリストに保持しておくなどするといいかもしれません。
2. 取消線
取消線が引かれているセルを読み込まないようにします。
セル全体に取消線が引かれているものとセルの一部(文字の一部)に取消線が引かれているもので対応方法が異なるので別々に紹介します。

1. セル全体に取消線がある
セル全体に取消線があるかどうかの判定方法です。
for(Cell cell : row){
// セルのフォントを取得
CellStyle style = c.getCellStyle();
Font font = c.getSheet().getWorkbook().getFontAt(style.getFontIndex());
// セルに取消線があるかどうかを判定
if(font.getStrikeout()){
// 取消線がある場合、次のセルを読み込む
continue;
}
...
}
2. セル内の一部に取消線がある
セルの一部に取消線がある場合は読み込むExcelの拡張子の種類によって書き方を使い分ける必要があります。
※HSSFやXSSFについての詳しい情報はこちらをご覧ください。
拡張子がxlsxの場合
取消線がかかっている文字列を取得します。
例)あいうえお → うえ
// XSSFRichTextString形式にてセルの値を取得
XSSFRichTextString richStr = (XSSFRichTextString) cell.getRichStringCellValue();
// セル内の文字列に当たっているフォントの塊の数を取得
int cnt = richStr.numFormattingRuns();
// フォントが当たっていないときは0になる
if (cnt == 0 ) {
continue;
}
for (int i = 0; i < cnt; i++;) {
// インデックスがi番目のフォントの塊を取得
XSSFFont xssfFont = richStr.getFontOfFormattingRun(i);
// 塊にフォントが当たっていなかった場合
if (xssfFont == null) {
continue;
}
// 塊にフォントが当たっていた場合、取消線があるかどうかの判定
if (xssfFont.getStrikeout()) {
// 取り消し線がある場合、i番目のインデックスの塊の文字列を取得
System.out.println(richStr.getCTRst().getRArray(i).getT());
}
}
上記の通り、xlsxの場合は比較的単純に取得することができます。私自身はFormattingRun系の処理の意味を理解するのに少し悩みましたが、処理を見る限り「あいうえお」だと「あい」「うえ」「お」の塊で分けてみているようでした。(ただ「あい」はフォントなし、「うえ」「お」は文字サイズ、文字フォント(メイリオなど)、取消線の有無…で取得されていました。)
拡張子がxls(Excel 97-2003 ver.)の場合
HSSFFontは型が古いバージョンのせいもあってか、XSSFのようにフォントそのものの取得ができず、取消線のついているIndexのみを取得するようです。
String cellStr = cell.getStringCellValue();
HSSFRichTextString richStr = (HSSFRichTextString)cell.getRichStringCellValue();
// フォントが当たっている塊の数を取得
int cnt = richStr.numFormattingRuns();
if (cnt == 0){
continue;
} else {
int startStrikeoutIndex = -1;
boolean isStrikeoutStartIndex = false;
for (int i = 0; i < cnt; i++;) {
// インデックスがi番目のフォントの塊を取得
Font hssfFont = wb.getFontAt(richStr.getFontOfFormattingRun(i));
int index = richStr.getIndexOfFormattingRun(i);
// 塊にフォントが当たっていなかった場合
if (hssfFont == null) {
if (isStrikeoutStartIndex) {
System.out.println(cellStr.substring(startStrikeoutIndex, index));
isStrikeoutStartIndex = false;
}
continue;
}
// フォント設定はあるが取り消し線がない場合
if (!hssfFont.getStrikeout()) {
if (isStrikeoutStartIndex) {
System.out.println(cellStr.substring(startStrikeoutIndex, index));
isStrikeoutStartIndex = false;
}
}
// 一部に取り消し線がある場合
else if (hssfFont.getStrikeout()) {
startStrikeoutIndex = index;
isStrikeoutStartIndex = true;
if (i + 1 == cnt) {
// 最後の塊の場合はここで出力する。
System.out.println(cellStr.substring(startStrikeoutIndex, cellStr.length()));
}
}
}
}
私が調べた中で、使える処理を使って実装したため、かなり力技になってしまいました。簡単に仕組みを説明すると「あいうえお」の場合、取り消し線のある部分の1文字目のIndexをstartStrikeoutIndexとして取得し(「い」の場合1)、isStrikeoutStartIndexをtrueにします。その後isStrikeoutStartIndexがtrueの場合、startStrikeoutIndexとその次の塊の最初の文字のIndex(「う」の部分なので2)の間にある文字が取り消し線が当たっている文字になるので、その部分を取得しています。
おわりに
かなり苦労した部分だったため、必要な時に見返せるようにまとめました。同じことをしたいと考えている方のお役に立てばよりうれしいです。
参考
- [Excelシート内の「取り消し線(打ち消し線)」設定の判定の仕方]
(http://blog.livedoor.jp/itawasa7/archives/52144136.html)