某SNSで、こんな投稿を見つけた。
Beginner vs Professional 🤣🤣🤣 pic.twitter.com/BPWF7TVAlv
— Python Programming (@PythonPr) March 23, 2026
書式指定を含まない単純な固定の文字列の出力なのに、puts や fputs ではなく printf が用いられている。
printf は、書式のパース処理が入るから遅いのではないか?
……でも、今回は書式が含まれていないからそれほどコストは増えないか?
ということで、実験してみた。
検証用コード
ループを最適化されないよう、実験を行う関数の呼び出しとそれをループで大量に繰り返す処理を分けてコンパイルした。
繰り返すコード
#include <stdio.h>
void func(void);
int main(void) {
int i;
for (i = 0; i < 1000000000; i++) {
func();
}
return 0;
}
繰り返されるコード
void func(void) {
}
#include <stdio.h>
void func(void) {
printf("hello, world\n");
}
#include <stdio.h>
void func(void) {
puts("hello, world");
}
#include <stdio.h>
void func(void) {
fputs("hello, world\n", stdout);
}
コンパイル
今回は、Amazon EC2 でコンパイル・実行を行った。
- インスタンス:t3.micro
- OS:Ubuntu Server 24.04 LTS (AMI ID:
ami-0d76b909de1a0595d) - CPU:Intel(R) Xeon(R) Platinum 8175M CPU @ 2.50GHz
- コンパイラ:gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0
繰り返すコード
以下のコマンドでコンパイルを行った。
gcc -O2 -c -o main.o main.c
コンパイル結果を確認した。
unroll して1回のループにつき2回関数を呼び出していることがわかった。
objdump -d main.o
main.o: file format elf64-x86-64
Disassembly of section .text.startup:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 53 push %rbx
5: bb 00 ca 9a 3b mov $0x3b9aca00,%ebx
a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
10: e8 00 00 00 00 call 15 <main+0x15>
15: e8 00 00 00 00 call 1a <main+0x1a>
1a: 83 eb 02 sub $0x2,%ebx
1d: 75 f1 jne 10 <main+0x10>
1f: 31 c0 xor %eax,%eax
21: 5b pop %rbx
22: c3 ret
呼び出されている関数を確認した。
呼び出されるのは func であることがわかった。
readelf -r main.o
Relocation section '.rela.text.startup' at offset 0x180 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000011 000400000004 R_X86_64_PLT32 0000000000000000 func - 4
000000000016 000400000004 R_X86_64_PLT32 0000000000000000 func - 4
Relocation section '.rela.eh_frame' at offset 0x1b0 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text.startup + 0
繰り返されるコード
最適化ありでのコンパイル
同様にコンパイルし、結果を確認した。
すると、printf は puts に置き換えられてしまったが、fputs は置き換えられなかった。
実用上「単純な printf の使用は puts に置き換えてくれることがある」ことはわかるが、今回の「printf と puts の効率を比較する」目的では、これは適さない。
gcc -O2 -c -o nop_o2.o nop.c
gcc -O2 -c -o printf_o2.o printf.c
gcc -O2 -c -o puts_o2.o puts.c
gcc -O2 -c -o fputs_o2.o fputs.c
objdump -d nop_o2.o && readelf -r nop_o2.o
objdump -d printf_o2.o && readelf -r printf_o2.o
objdump -d puts_o2.o && readelf -r puts_o2.o
objdump -d fputs_o2.o && readelf -r fputs_o2.o
nop_o2.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: c3 ret
Relocation section '.rela.eh_frame' at offset 0x138 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
printf_o2.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # b <func+0xb>
b: e9 00 00 00 00 jmp 10 <func+0x10>
Relocation section '.rela.text' at offset 0x190 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000007 000300000002 R_X86_64_PC32 0000000000000000 .LC0 - 4
00000000000c 000500000004 R_X86_64_PLT32 0000000000000000 puts - 4
Relocation section '.rela.eh_frame' at offset 0x1c0 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
puts_o2.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # b <func+0xb>
b: e9 00 00 00 00 jmp 10 <func+0x10>
Relocation section '.rela.text' at offset 0x188 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000007 000300000002 R_X86_64_PC32 0000000000000000 .LC0 - 4
00000000000c 000500000004 R_X86_64_PLT32 0000000000000000 puts - 4
Relocation section '.rela.eh_frame' at offset 0x1b8 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
fputs_o2.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: 48 8b 0d 00 00 00 00 mov 0x0(%rip),%rcx # b <func+0xb>
b: ba 0d 00 00 00 mov $0xd,%edx
10: be 01 00 00 00 mov $0x1,%esi
15: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 1c <func+0x1c>
1c: e9 00 00 00 00 jmp 21 <func+0x21>
Relocation section '.rela.text' at offset 0x1c0 contains 3 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000007 000500000002 R_X86_64_PC32 0000000000000000 stdout - 4
000000000018 000300000002 R_X86_64_PC32 0000000000000000 .LC0 - 4
00000000001d 000600000004 R_X86_64_PLT32 0000000000000000 fwrite - 4
Relocation section '.rela.eh_frame' at offset 0x208 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
最適化なしでのコンパイル
-O0 オプションにより、最適化を無効化してコンパイルした。
gcc -O0 -c -o printf_o0.o printf.c
objdump -d printf_o0.o && readelf -r printf_o0.o
しかし、それでも printf のかわりに puts を用いられてしまった。
printf_o0.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <func+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <func+0x17>
17: 90 nop
18: 5d pop %rbp
19: c3 ret
Relocation section '.rela.text' at offset 0x198 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000b 000300000002 R_X86_64_PC32 0000000000000000 .rodata - 4
000000000013 000500000004 R_X86_64_PLT32 0000000000000000 puts - 4
Relocation section '.rela.eh_frame' at offset 0x1c8 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0
アセンブリ言語を用いた printf の呼び出し
最適化ありでのコンパイル結果を参考に、アセンブリ言語を用いて強制的に printf を呼び出すようにした。
.text
.globl func
func:
endbr64
leaq hello(%rip), %rdi
jmp printf
.section .rodata
hello:
.string "hello, world\n"
.section .note.GNU-stack
.section .note.GNU-stack の行が無いと、リンク時に
/usr/bin/ld: warning: printf_asm.o: missing .note.GNU-stack section implies executable stack
/usr/bin/ld: NOTE: This behaviour is deprecated and will be removed in a future version of the linker
という警告が出たので、入れた。
gcc -c -o printf_asm.o printf.s
objdump -d printf_asm.o && readelf -r printf_asm.o
printf_asm.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <func>:
0: f3 0f 1e fa endbr64
4: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # b <func+0xb>
b: e9 00 00 00 00 jmp 10 <func+0x10>
Relocation section '.rela.text' at offset 0xf0 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000007 000200000002 R_X86_64_PC32 0000000000000000 .rodata - 4
00000000000c 000400000004 R_X86_64_PLT32 0000000000000000 printf - 4
リンク
コンパイル結果をリンクし、実行可能ファイルを作成した。
gcc -o nop main.o nop_o2.o
gcc -o printf main.o printf_asm.o
gcc -o puts main.o puts_o2.o
gcc -o fputs main.o fputs_o2.o
printf のみ、_o2.o シリーズではなく、アセンブリ言語バージョンを用いた。
実行
それぞれのプログラムを time コマンドを介して実行し、かかった時間を計測した。
time ./nop > /dev/null
time ./printf > /dev/null
time ./puts > /dev/null
time ./fputs > /dev/null
これを5回ずつ繰り返し、平均をとった。
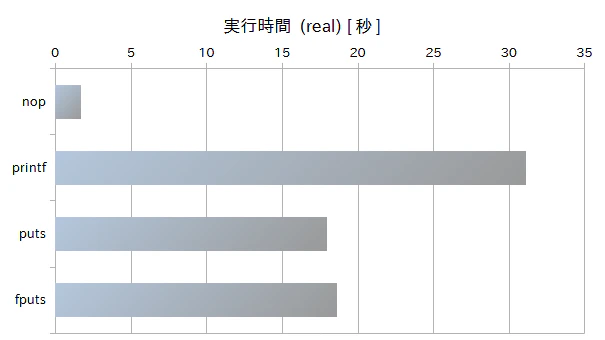
結果は以下のようになった。
| 項目\プログラム | nop | printf | puts | fputs |
|---|---|---|---|---|
| real | 1.6336 秒 | 31.0970 秒 | 17.9000 秒 | 18.6094 秒 |
| user | 1.6320 秒 | 30.4000 秒 | 17.2450 秒 | 17.9534 秒 |
| sys | 0.0014 秒 | 0.6940 秒 | 0.6532 秒 | 0.6498 秒 |
結論
今回の実験では、puts を使うのが一番速く、fputs がそれより少しだけ遅いがあまり変わらず、printf はそれらより約2倍遅いという結果になった。
とはいえ、普通にコンパイルしたら printf を用いたコードも puts に変換されたので、puts を明示的に書いたコードと変わらない速度になるはずである。
よって、好きな方を使えばいいかもしれないが、printf を使う場合はうっかり % を含む文字列をエスケープせずに出力しようとしないよう注意するべきだろう。
また、puts は勝手に改行を出力するので、改行したくない場合は fputs を使うべきかもしれない。