今回のアプリ
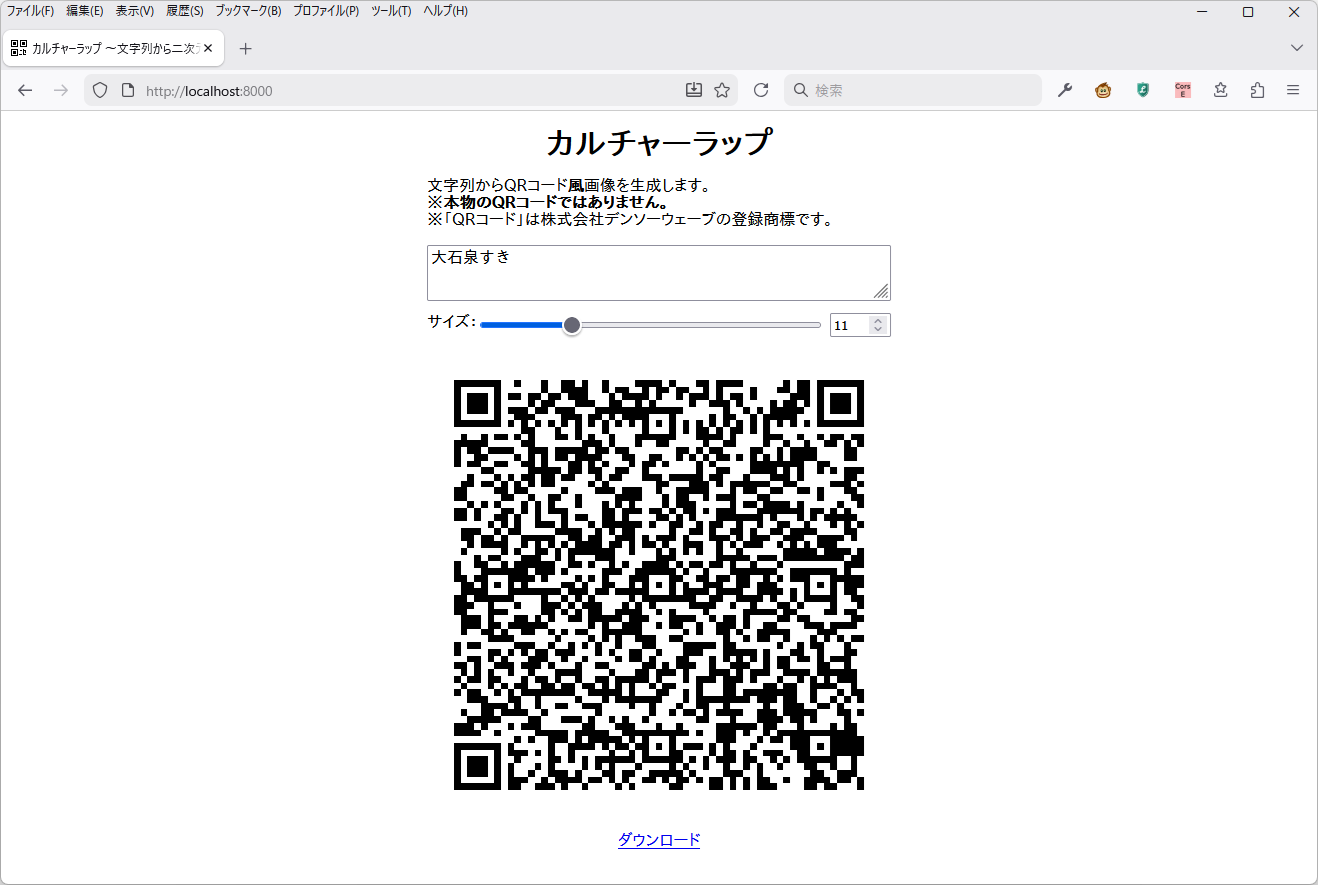
何をするアプリか
入力された文字列に基づき、QRコードではない画像を生成する。
具体的には、特徴的な部分だけQRコードの仕様に合わせ、残りの部分はランダムデータで埋めた画像を生成する。
「QRコード」は株式会社デンソーウェーブの登録商標です。
名前の由来
QRといえば文化放送。
「放送」を「包装」に置き換え、「文化」と「包装」をそれぞれ英語化。
以前の作品との比較
自分は、以前にもQRコード風の画像を作成するプログラムを書いた。
なでしこさんで偽2次元コード作成|みけCAT
このときの仕様は
- 特徴的でない部分は、単純にランダムなデータで埋める
- バージョン1にのみ対応
だった。
一方、今回のクソアプリでは
- ランダムデータを文字列から生成し、同じ文字列とバージョンなら同じ画像になる
- バージョン1~40全てに対応
と、より高機能になった。
支える技術
QRコードの特徴的な部分を調べる
ランダム生成して変わらない部分を調べる
Python の qrcode モジュールを用いて、ランダムな文字列から各バージョンのQRコードを作成して結果を平均し、表す文字列によって変わらない部分を浮き立たせた。
各バージョンで表せる文字数は、
QRコードの情報量とバージョン|QRコードドットコム|株式会社デンソーウェーブ
を参考にした。
このプログラムを実行すると、結果の画像 01.png ~ 40.png がカレントディレクトリの out ディレクトリ内に生成される。
import qrcode
import random
from PIL import Image
def random_str(length):
return ''.join(random.choices("ABCDEFGHIJKLMNOPQRSTUVWXYZ", k=length))
def get_qr(text, version):
qr = qrcode.QRCode(version=version, box_size=1)
qr.add_data(text)
qr.make(fit=False)
qr_img = qr.make_image(fill_color=(0,0,0), back_color=(255,255,255))
return (list(qr_img.getdata(0)), qr_img.size)
str_sizes = [
None,
20, 38, 61, 90, 122, 154, 178, 221, 262, 311,
366, 419, 483, 528, 600, 656, 734, 816, 909, 970,
1035, 1134, 1248, 1326, 1451, 1542, 1637, 1732, 1839, 1994,
2113, 2238, 2369, 2506, 2632, 2780, 2894, 3054, 3220, 3391
]
sample_size = 16
for size in range(1, 40 + 1):
img_sum, img_size = get_qr(random_str(str_sizes[size]), size)
for _ in range(1, sample_size):
img, _ = get_qr(random_str(str_sizes[size]), size)
img_sum = [x + y for x, y in zip(img_sum, img)]
img_data = bytes([x // sample_size for x in img_sum])
img_obj = Image.frombuffer("L", img_size, img_data)
img_obj.save("out/%02d.png" % size)
結果を8倍に拡大した画像をいくつか示す。
バージョン1 (最小サイズ):

バージョン2 (アライメントパターンが現れる):

バージョン7 (アライメントパターンが増え、バージョン情報が現れる):

バージョン21:

バージョン40 (最大サイズ):

これらを見ると、以下の部分がデータに依存せず、浮き出ていることがわかる。
- ファインダパターン (右下以外の隅にある四角)
- タイミングパターン (ファインダパターン間に伸びる白黒交互の線)
- アライメントパターン (中間にほぼ等間隔で配置される四角)
- バージョン情報 (左下と右上のファインダパターンの隣に配置されるデータ)
各部の名称は
Creating a QR Code step by step
を参考にした。
この実験では誤り訂正レベルを固定しているため、誤り訂正レベルを表す部分も固定になっているが、今回はこの部分は「特徴的な部分」に含めない (ランダム埋めする) ことにする。
また、バージョンが1上がるごとに、画像のサイズは縦横に4ずつ大きくなることもわかった。
変わらない部分の情報を拾う
以下のプログラムを用いて、out ディレクトリに格納されたデータから、
- アライメントパターンを配置する位置
- バージョン情報の内容
を抽出し、JSON として出力した。
import json
from PIL import Image
result = []
for size in range(1, 40 + 1):
img = Image.open("out/%02d.png" % size)
expected_size = 25 + 4 * size
if img.mode != "L" or img.size[0] != expected_size or img.size[1] != expected_size:
raise Exception("unexpected image format")
markers = []
for i in range(12, expected_size - 12):
v1 = img.getpixel((11, i - 1))
v2 = img.getpixel((11, i))
v3 = img.getpixel((11, i + 1))
h1 = img.getpixel((i - 1, 11))
h2 = img.getpixel((i, 11))
h3 = img.getpixel((i + 1, 11))
v = all([c == 255 for c in [v1, v2, v3]])
h = all([c == 255 for c in [h1, h2, h3]])
if v and h:
markers.append(i - 4)
elif v or h:
raise Exception("not symmetrical")
version = None
if size >= 7:
version = 0
for y in range(expected_size - 15, expected_size - 12):
for x in range(4, 10):
version <<= 1
if img.getpixel((x, y)) == 0:
version |= 1
result.append({
"version": version,
"markers": markers
})
print(json.dumps(result, separators=(",", ":")))
このプログラムを実行すると、以下の結果が得られた。(結果は整形している)
version がバージョン情報の内容を表し、markers がアライメントパターンの位置を表す。
version は、左下に配置されたバージョン情報の左上から右下を上位ビットから下位ビットで表しており、白を 0、黒を 1 で表す。
markers は、左上のファインダパターンの黒い部分の左上を 0 とし、何モジュール目かで表す。
なお、一番右と一番下のアライメントパターンの位置は、ファインダパターンに合わせれば良さそうであるため、省略した。
[
{"version":null,"markers":[]},
{"version":null,"markers":[]},
{"version":null,"markers":[]},
{"version":null,"markers":[]},
{"version":null,"markers":[]},
{"version":null,"markers":[]},
{"version":10150,"markers":[22]},
{"version":71480,"markers":[24]},
{"version":226820,"markers":[26]},
{"version":171904,"markers":[28]},
{"version":65212,"markers":[30]},
{"version":55578,"markers":[32]},
{"version":178214,"markers":[34]},
{"version":217506,"markers":[26,46]},
{"version":77982,"markers":[26,48]},
{"version":115804,"markers":[26,50]},
{"version":238944,"markers":[30,54]},
{"version":150756,"markers":[30,56]},
{"version":11736,"markers":[30,58]},
{"version":2686,"markers":[34,62]},
{"version":158530,"markers":[28,50,72]},
{"version":230086,"markers":[26,50,74]},
{"version":123898,"markers":[30,54,78]},
{"version":54116,"markers":[28,54,80]},
{"version":176728,"markers":[32,58,84]},
{"version":220124,"markers":[30,58,86]},
{"version":80608,"markers":[34,62,90]},
{"version":73030,"markers":[26,50,74,98]},
{"version":228474,"markers":[30,54,78,102]},
{"version":169470,"markers":[26,52,78,104]},
{"version":62658,"markers":[30,56,82,108]},
{"version":165421,"markers":[34,60,86,112]},
{"version":59153,"markers":[30,58,86,114]},
{"version":69269,"markers":[34,62,90,118]},
{"version":225193,"markers":[30,54,78,102,126]},
{"version":215055,"markers":[24,50,76,102,128]},
{"version":76083,"markers":[28,54,80,106,132]},
{"version":49335,"markers":[32,58,84,110,136]},
{"version":172427,"markers":[26,54,82,110,138]},
{"version":233749,"markers":[30,58,86,114,142]}
]
アライメントパターンは、バージョン2、および7の倍数のバージョンで増えることがわかった。
文字列からランダムデータを得る
今回は、Web Crypto API を用いて、以下のように文字列からランダムデータを取得するようにした。
-
importKey()で、エンコードした文字列を鍵 (パスワード) として取り込む -
deriveKey()で、PBKDF2 を用い、パスワードから AES-CTR の鍵を生成する -
encrypt()を用い、生成した鍵で全部ゼロのデータを暗号化する
今回は暗号化が目的ではなく、適当なランダムデータが得られればよいので、PBKDF2 のイテレーション数は少なく設定した。
AES-CTR による暗号化を行う際、nonce にバージョンを入れることで、同じ文字列でもバージョンによって違うランダムデータが得られるようにした。
Web Crypto API には、パスワードから直接ビット列を生成する deriveBits() も存在するが、これを用いると大きいバージョン (すなわち、比較的長いランダムデータを用いる) ではエラーになってしまった。
画像を生成する
まず、まわりの余白を除いたQRコード風画像を配置する部分に、ランダムデータを配置する。
次に、調べた位置に従って、この中の然るべき位置に
- ファインダパターン
- タイミングパターン
- アライメントパターン
- バージョン情報
を上書きする。
これにより、各セルの色を表す2値データが得られるので、これを画像ファイルにする。
今回は、白黒画像なら比較的作りやすく、かつ1個の色情報で一気に8×8ピクセルを埋めることができてお得な JPEG 形式を採用した。
今回生成する JPEG ファイルは、以下のセグメントとマーカーからなる。
- SOI マーカー:JPEG データの始点を表す
- APP0 セグメント:汎用、今回は JPEG の中でも相互運用性の高い JFIF 形式であることを示すデータを入れる
- DQT セグメント:圧縮データのデコード時に掛ける係数を格納する
- SOF0 セグメント:画像の幅・高さ・チャンネル情報を格納する
- DHT セグメント:圧縮データを記述する符号を定義する
- SOS セグメント:圧縮データの格納開始を表す
- 圧縮データ:画像の中身を表す
- EOI マーカー:JPEG データの終端を表す
JPEG 形式の詳細は、こちらを参照してほしい。
JPEG (JFIF) ファイルの読み方まとめ #画像処理 - Qiita
JPEG 形式の色データは、画像をブロックに分割して、そのブロックごとに格納する。
このブロックの基本の大きさは、8×8ピクセルである。
(クロマ・サブサンプリングを用いる場合、8×8ピクセルより大きいブロックを用いることがある。今回は用いないので、ブロックの大きさは8×8ピクセルである)
ブロック内の情報は、大きく分けて、ブロック全体の値を表す DC 成分と、ブロック内での値の動きを表す AC 成分からなる。
観察を行った結果、0 (黒) を表すには DC 成分を -1024、255 (白) を表すには DC 成分を 1016 にすればよいようだった。
実際の DC 成分は、画像内の前のブロックの DC 成分 (画像で最初のブロックでは 0) に足す値 (差分) で格納する。
今回は白と黒しか使わないので、2ブロック目以降に格納する差分は -2040 (白→黒)、0 (同じ色)、2040 (黒→白) のいずれかになる。
今回は、8×8ピクセルのブロックをそれぞれ同じ色にしたいので、AC 成分は全て 0 とする。
これは、最初に「これ以降の AC 成分は全て 0」を表すデータ (EOB) を置くことで実現できる。
また、このことにより DQT セグメントに格納する係数テーブルの 2 要素目以降は実質参照しなくなるので、適当なデータを入れておいてよいことになる。(0x00 は除く)
今回は、この部分に適当な文字列を入れておいた。
おわりに
文字列を入力すると、それをもとにQRコード風の (QRコードではない) 画像を作成するアプリケーションを作成した。
本物のQRコードを作りたい場合は、既に世間には山ほどQRコード作成アプリケーションがあるので、それらを使えばよいだろう。
今回のアプリケーションの用途としては……たとえば、映像作品中で「QRコード風の何か」を出したいときに使えるかな?
ただ、QRコードっぽいのに読めないという余計なストレスを与えないため、作品に関係するWebページのURLなどの当たり障りのないデータを入れたQRコードを使ったほうがいいかもしれない。
他の用途としては、偽QRコードの中に1個だけ本物のQRコードを置いておき、本物を探させる……なんていう遊びもできるかも?