早いもので ラクス Advent Calendar 2018 も13日目です。
(気にしてなかったけど不吉な順番ですね・・・)
年を重ねる毎に若いメンバーが増え、おじさん勢の出番も少なくなってきました。
勢いがあるということで嬉しい限りです。
はじめに
先日「PostgreSQL Conference Japan 2018」に参加してきました。
話題は殆どPostgreSQL11の内容で、気になったのはこの辺りです。
- パーティショニングの機能拡張
- パラレルクエリの機能拡張
- 論理レプリケーションの導入
この中で以前より導入したいな・・・と思っていたパーティショニングの機能について書いてみたいと思います。
※PostgreSQLは11以前からパーティショニングには対応していますが・・・その辺りも記載してみたいと思います
パーティショニングとは
データを複数に分割して格納することです。
データを分割することで性能や運用性が向上し、特に大きなテーブルには有効な手段となります。
テーブルを親子構造に分割し、データ操作は親テーブルに対して実施しますが、実際にデータが格納されるのは子テーブルとなります。
子テーブルは1つの親テーブルに対して複数登録でき、テーブル追加時に決定したルールによってどの子テーブルに格納されるかQuery発行時に判断されます。
例えば、historyというテーブルに対して、年度単位でデータを別けて格納すると、親テーブルはhistory、子テーブルはhistory_yyyyの様な形となり、以下の様になります。
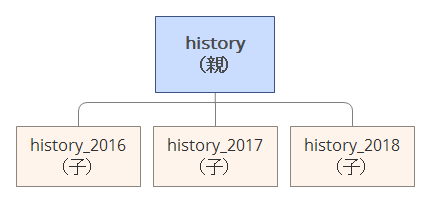
historyに対してINSERTを行うと投入されたデータの年度から格納先の子テーブルが自動的に判断されます。
パーティショニングのメリット
実際にパーティショニングを利用した場合に考えられるメリットを挙げてみます。
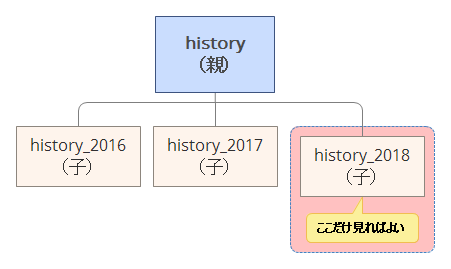
検索範囲が限定される
先の例ですとhistoryというテーブルの中で、直近の2018年度のデータのみを検索対象としたい といったケースは実運用でも多いと思います。
こういった場合に2018年度のデータを調べる場合に対象範囲が狭くなるので性能面での速度向上、メモリに展開する際の使用量の軽減、キャッシュヒット率の向上が期待できます。
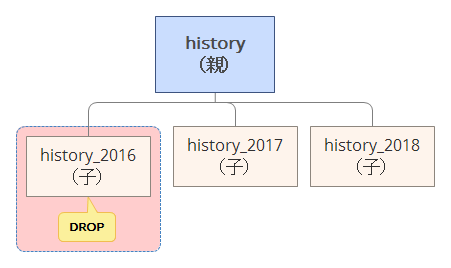
データ削除が高速
パーティショニングしていない場合は、データの削除はDELETEにて実施しますが、パーティショニングしている場合、子テーブルをDROPすることでデータを削除することが出来ます。
説明も不要かとは思いますが、、、DELETEとDROPでは速度が段違いです。
実際の運用でもデータ保持期間を定め、古くなったデータは削除することは多いと思いますので、一定期間を過ぎたデータをテーブル毎DROPできるというのは運用上非常に魅力的です。
パーティショニングのデメリット
もちろん良いこともあれば悪いこともあります。
悪いというか成約といった方が正しいかもしれませんのでさらーっと記載します。
- テーブルの分割数は100件程度が限界のようです。分割するテーブルが100を超えた辺りから急激に性能劣化が見られるようです。(PostgreSQL11ではこの状態です)
- PostgreSQL9系まではINSERT性能が低下する問題がありましたが、PostgreSQL10より改善されています。
パーティショニングの種類
PostgreSQL10まではレンジ・パーティショニング、リスト・パーティショニングがサポートされていましたが、PostgreSQL11よりハッシュ・パーティショニングがサポートされるようになりました。
それぞれの特徴は以下のようになっています。
レンジ・パーティショニング
値の範囲(RANGE)ごとに分割する方法です。各子テーブルごとに範囲を定め、その範囲の収まるデータを格納します。
利用例ですと日々、増加していく履歴のようなデータを扱うのに適しています。
※2018/04/01~2019/03/31の値はxxxxテーブルに格納 といったイメージ
リスト・パーティショニング
一定の選択肢(LIST)を用意しておき、その条件で分割する方式です。
利用例だと各地域毎のデータ(都道府県ごと)の用に一定の選択肢で分類できるデータを扱うのに適しています。
※東京、神奈川、千葉・・・をそれぞれのテーブルに格納 といったイメージ
ハッシュ・パーティショニング
ハッシュ値(HASH)に基づいて各子テーブルに均等にデータを分割する方式です。
先の2つとは少し用途が違い、表領域を複数に分割することでアクセスを分散させるような用途で利用します。
PostgreSQL11で何が変わったのか
PostgreSQL9系のころから継承とトリガーを利用することでパーティショニングを実現することは可能でした。
その場合、親テーブルを継承した子テーブルを複製して親テーブルに配置したトリガーで子テーブルにデータを格納することになります。
この手段は非常に複雑になりがちで、職人間となってしまいメンテナンス性が非常に悪いです。
また、トリガーを利用するため、INSERTの性能が著しく低下します。(内部的に複数回INSERTしているのでそりゃ遅くなります)
PostgreSQL10から正式にパーティショニング機能(宣言的パーティションと言います)が取り入れられましたがそれでも多数の制限があり、PostgreSQL11では機能が拡張され、以下が実現できるようになっています。(逆に10では出来なかったことです)
親テーブルにプライマリキーが設定できるようになった
既存テーブルをパーティショニングしようと思った場合に困るな・・・と思っていたのでありがたい改善です。
ただ、プライマリキーにはパーティショニングキー(分割の際に参照する項目)を含める必要があります。
パーティショニングキーの更新に対応
パーティショニングキーを更新した場合、自動であるべきテーブルにデータが移動されるようになりました。
実際に試してみる
先に書いたサンプルのhisotryとその子テーブル達を実際に作ってみます。
環境は以下の通り。
- OS:CentOS 7.4
- DB:PostgreSQL 11.1
パーティショニングテーブルの作成
historyテーブルを作成し、2016~2018のパーティション(子テーブルのこと)を追加。
パーティショニングの方式はレンジ・パーティショニングで、パーティショニングキー(分割時に参照する項目)はlogdateで設定。
プライマリキーはidとパーティショニングキーで設定。
# CREATE TABLE history (id int, logdate date, memo text) partition BY RANGE (logdate);
# CREATE TABLE history_2016 partition OF history FOR VALUES FROM ('2016-04-01') TO ('2017-04-01');
# CREATE TABLE history_2017 partition OF history FOR VALUES FROM ('2017-04-01') TO ('2018-04-01');
# CREATE TABLE history_2018 partition OF history FOR VALUES FROM ('2018-04-01') TO ('2019-04-01');
# ALTER TABLE history ADD PRIMARY KEY(id, logdate);
作成した結果を確認する。
パーティショニングテーブルを確認する場合、\d+ を利用する。
# \d+ history
テーブル "public.history"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト | ストレージ | 統計の対象 | 説明
---------+---------+----------+---------------+------------+------------+------------+------
id | integer | | not null | | plain | |
logdate | date | | not null | | plain | |
memo | text | | | | extended | |
パーティションキー: RANGE (logdate)
インデックス:
"history_pkey" PRIMARY KEY, btree (id, logdate)
パーティション: history_2016 FOR VALUES FROM ('2016-04-01') TO ('2017-04-01'),
history_2017 FOR VALUES FROM ('2017-04-01') TO ('2018-04-01'),
history_2018 FOR VALUES FROM ('2018-04-01') TO ('2019-04-01')
データ投入
2016~2018年度のデータをそれぞれ100,0000件ずつ投入します。
余談ですが、こういう時にgenerate_seriesが便利です。
# INSERT INTO history VALUES (generate_series(1, 1000000), '2016-10-01', 'test 2016');
# INSERT INTO history VALUES (generate_series(1000001, 2000000), '2017-11-01', 'test 2017');
# INSERT INTO history VALUES (generate_series(2000001, 3000000), '2018-12-01', 'test 2018');
# SELECT relname, reltuples as rows FROM pg_class WHERE relname IN ('history', 'history_2016', 'history_2017', 'history_2018') ORDER BY relname;
relname | rows
--------------+-------
history | 0
history_2016 | 1e+06
history_2017 | 1e+06
history_2018 | 1e+06
データは全てパーティション側に投入されているのが分かります。
ちなみに、RANGEに収まらないデータを投入するとエラーとなります。
PostgreSQL11からはデフォルトパーティションを設定することでこれを回避可能となっていますが、今回はこの辺りは割愛します。
# INSERT INTO history VALUES (3000001, '2019-10-01', 'test 2019');
ERROR: no partition of relation "history" found for row
DETAIL: Partition key of the failing row contains (logdate) = (2019-10-01).
検索時の挙動
パーティショニングした場合の検索を確認してみます。
パラレルクエリが動作すると見づらいので停止した状態で確認します。
# SET max_parallel_workers_per_gather = 0;
全検索
全検索した場合、はもちろん全パーティションのマージ結果になります。
# SELECT COUNT(*) FROM history;
count
---------
3000000
(1 行)
実行計画は各パーティションを検索して、Appendしています。
# EXPLAIN ANALYZE SELECT COUNT(*) FROM history;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=71610.00..71610.01 rows=1 width=8) (actual time=725.178..725.178 rows=1 loops=1)
-> Append (cost=0.00..64110.00 rows=3000000 width=0) (actual time=0.013..544.612 rows=3000000 loops=1)
-> Seq Scan on history_2016 (cost=0.00..16370.00 rows=1000000 width=0) (actual time=0.012..102.076 rows=1000000 loops=1)
-> Seq Scan on history_2017 (cost=0.00..16370.00 rows=1000000 width=0) (actual time=0.015..103.789 rows=1000000 loops=1)
-> Seq Scan on history_2018 (cost=0.00..16370.00 rows=1000000 width=0) (actual time=0.013..97.614 rows=1000000 loops=1)
Planning Time: 0.137 ms
Execution Time: 725.213 ms
(7 行)
パーティションキーを指定した場合
パーティションキーをしてして検索すればその分だけ検索されます。
SELECT COUNT(*) FROM history WHERE logdate BETWEEN '2018-04-01' AND '2019-04-01';
count
---------
1000000
(1 行)
この時の実行計画は2018年度のテーブルのみを対象としています。
# EXPLAIN ANALYZE SELECT COUNT(*) FROM history WHERE logdate BETWEEN '2018-04-01' AND '2019-04-01';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=28870.00..28870.01 rows=1 width=8) (actual time=271.466..271.466 rows=1 loops=1)
-> Append (cost=0.00..26370.00 rows=1000000 width=0) (actual time=0.014..209.606 rows=1000000 loops=1)
-> Seq Scan on history_2018 (cost=0.00..21370.00 rows=1000000 width=0) (actual time=0.014..129.079 rows=1000000 loops=1)
Filter: ((logdate >= '2018-04-01'::date) AND (logdate <= '2019-04-01'::date))
Planning Time: 0.169 ms
Execution Time: 271.495 ms
(6 行)
パーティションの追加/削除、パーティション間の移動
パーティションの追加
今回のサンプルですと、2019年度が近づいてきたので2019年度分のテーブルを作って追加するイメージです。
操作はパーティショニングテーブル作成時と同様にパーティションを作るだけです。
# CREATE TABLE history_2019 partition OF history FOR VALUES FROM ('2019-04-01') TO ('2020-04-01');
# \d+ history
テーブル "public.history"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト | ストレージ | 統計の対象 | 説明
---------+---------+----------+---------------+------------+------------+------------+------
id | integer | | not null | | plain | |
logdate | date | | not null | | plain | |
memo | text | | | | extended | |
パーティションキー: RANGE (logdate)
インデックス:
"history_pkey" PRIMARY KEY, btree (id, logdate)
パーティション: history_2016 FOR VALUES FROM ('2016-04-01') TO ('2017-04-01'),
history_2017 FOR VALUES FROM ('2017-04-01') TO ('2018-04-01'),
history_2018 FOR VALUES FROM ('2018-04-01') TO ('2019-04-01'),
history_2019 FOR VALUES FROM ('2019-04-01') TO ('2020-04-01')
パーティションの削除
不要になったパーティションを削除する場合は、対象のパーティションに対してDROP TABLEを行うだけです。
# DROP TABLE history_2019;
# \d+ history
テーブル "public.history"
列 | 型 | 照合順序 | Null 値を許容 | デフォルト | ストレージ | 統計の対象 | 説明
---------+---------+----------+---------------+------------+------------+------------+------
id | integer | | not null | | plain | |
logdate | date | | not null | | plain | |
memo | text | | | | extended | |
パーティションキー: RANGE (logdate)
インデックス:
"history_pkey" PRIMARY KEY, btree (id, logdate)
パーティション: history_2016 FOR VALUES FROM ('2016-04-01') TO ('2017-04-01'),
history_2017 FOR VALUES FROM ('2017-04-01') TO ('2018-04-01'),
history_2018 FOR VALUES FROM ('2018-04-01') TO ('2019-04-01')
パーティション間のデータ移動
パーティションキーが更新された場合、自動的にあるべきパーティションにデータが移動されます。
新たにパーティションを作成して動作を確認します。
# CREATE TABLE history_2019 partition OF history FOR VALUES FROM ('2019-04-01') TO ('2020-04-01');
# INSERT INTO history VALUES(9999999, '2018-10-01', 'dummy');
# SELECT COUNT(*) FROM history_2019;
count
-------
0
(1 行)
# SELECT COUNT(*) FROM history_2018;
count
---------
1000001
(1 行)
# UPDATE history SET logdate = '2019-10-01' WHERE id = 9999999;
# SELECT COUNT(*) FROM history_2018;
count
---------
1000000
(1 行)
# SELECT * FROM history_2019;
id | logdate | memo
---------+------------+-------
9999999 | 2019-10-01 | dummy
(1 行)
格納先が変更されていることが分かります。
まとめ
すごく端的に言うと「PostgreSQL11よさそうだから9系から移行するなら、10じゃなくて11にしようぜ!」と言いたくてこの記事を書きました。
本当はもう少しPostgreSQL11で試したこともあって、パラレルクエリの性能改善等も書きたかったのですが、、、体力の限界です。
その辺りはまた別の機会に書きたいと思います。
PostgreSQL11になってパーティショニングが実用レベル(10の制約ちょっと困り物でしたので)になり、某RDBと比べても遜色無いくらいまで来ているのではないかな と感じました。