Here, we are going to build a very simple text classification model using the TensorFlow framework.
Text classification.
Text classification is a fundamental task in natural language processing. It is a process of assigning labels (tags) to the text according to the content. Sentiment analysis, spam detections, and topic labeling are some of its applications.
We can mainly divide text classification into two groups considering the number of output classes;
1. Binary Classification.
2. Multiclass Classification.
Here we are going to build a binary text classification model for sentiment analysis
The first thing is to setup the development environment. First install Numpy, Matplotlib andTensorflow 2.0 libraries.
!pip install tensorflow
!pip install numpy
!pip install matplotlib
Prepare Data.
Let’s start preparing the data.
First, let’s import all necessary libraries.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
Then let’s prepare some dummy texts for this model. I included 10 positive and 10 negative texts. And used label 1 for positive and label 0 for negative.
text_data = [
# positive sents
'It is really nice.',
'That was awesome.',
'It is a good movie.',
'He is excellent sportsman',
'I love that music',
'Amazing customer service.',
'Great Job',
'It is really cool.',
'My experience so far has been fantastic.',
'Best product so far.',
# negative sents
'It is Bad',
'I hate it.' ,
'Support team is useless.',
'A piece of shit.',
'Movie sucks.',
'User guide is so confusing.',
'He was frustrated.',
'Food is stinking.',
'It is horrible.',
'Horrible experience.'
]
y = np.array([1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0])
The next task is to convert text data into numerical representation, since this is a simple model I will use One hot encoding here.
(In the real world, we have to deal with removing stop words and etc.)
X = [tf.keras.preprocessing.text.one_hot(text, 50) for text in text_data]
print(X )
# Output
'''
[[7, 20, 5, 40],
[2, 28, 35],
[7, 20, 43, 5, 6],
[10, 20, 45, 3],
[26, 44, 2, 10],
[45, 27, 31],
[15, 42],
[7, 20, 5, 47],
[29, 41, 34, 32, 25, 19, 5],
[6, 46, 34, 32],
[7, 20, 42],
[26, 49, 7],
[35, 42, 20, 19],
[43, 42, 20, 33],
[6, 4],
[22, 4, 20, 34, 35],
[10, 28, 24],
[22, 20, 47],
[7, 20, 17],
[17, 41]]
'''
We can see that the array size of the text data is different, the next step is to make the length of the arrays similar in size. To do that we can use pad_sequences.
X_padded = tf.keras.preprocessing.sequence.pad_sequences(X, maxlen=7, padding = 'post')
print(X_padded)
# Output
'''
[[ 7 20 5 40 0 0 0]
[ 2 28 35 0 0 0 0]
[ 7 20 43 5 6 0 0]
[10 20 45 3 0 0 0]
[26 44 2 10 0 0 0]
[45 27 31 0 0 0 0]
[15 42 0 0 0 0 0]
[ 7 20 5 47 0 0 0]
[29 41 34 32 25 19 5]
[ 6 46 34 32 0 0 0]
[ 7 20 42 0 0 0 0]
[26 49 7 0 0 0 0]
[35 42 20 19 0 0 0]
[43 42 20 33 0 0 0]
[ 6 4 0 0 0 0 0]
[22 4 20 34 35 0 0]
[10 28 24 0 0 0 0]
[22 20 47 0 0 0 0]
[ 7 20 17 0 0 0 0]
[17 41 0 0 0 0 0]]
'''
We can see that we got the same size arrays, length is corrected by adding 0 s to post position.
We just finished preprocessing our data. The next part is to create the model to fit our data.
Model building and Training.
We can easily define our model using Keras Sequential model API. It provides easy configuration for the shape of our input data and the type of layers that make up our model.
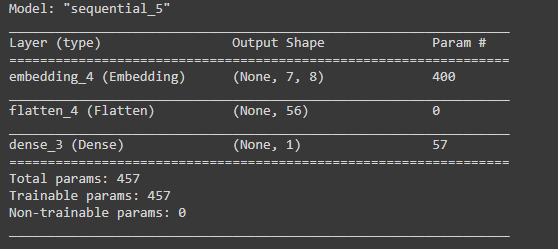
model = tf.keras.models.Sequential()
model.add((tf.keras.layers.Embedding(50, 8, input_length=7)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
In the code above, we created a Sequential model, then added the Embedding layer to the model as the first layer. The dimension of each word vector is 8. I used 7 as input_length. Normally this value is the length of the longest sentence. Then, the Embedding layer is flattened so that it can be directly used with the densely connected layer. Since it is a binary classification problem, we use the sigmoid function as the loss function at the dense layer.
Now we can compile the model and check its summary.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
The next step is training.
history = model.fit(X_padded, labels, epochs=600, batch_size=2, verbose=0)
plt.plot(history.history['loss'])

Model Testing.
Now we can test how our model responds to some text. Since this is a very simple model and trained on a small number of data, I believe it’s not going to perform so well.
def predict(sent):
X_test = [tf.keras.preprocessing.text.one_hot(sent, 50)]
X_test_padded = tf.keras.preprocessing.sequence.pad_sequences(X_test, maxlen=7, padding='post')
result = model.predict(X_test_padded)
if result[0][0]>0.5:
print('Its Positive')
else:
print('Its Negative')
predict('It is useless')
# Output
# >> Its Negative
predict('Book is so good')
# Output
# >> Its Positive
We can see that it’s working for simple text patterns.
Cheers ![]()
![]()
*本記事は @qualitia_cdevの中の一人、@nuwanさんが書いてくれました。
*This article is written by @nuwan a member of @qualitia_cdev.