この記事は リクルートライフスタイル Advent Calendar 2017 、9日目の記事です。
CETというプロジェクトでABテストの起案や分析や開発などをちょっとずつ担当している @mihirat です。こんばんは。
AWSでもマネージドサービスが出るなどkubernetesの機運が高まっていますね。余談ですが自分が去年書いた入門記事がそろそろ200いいねということで驚いております、今読み返すとちょっと怪しい説明が多いですね…
今回は、チームで運用しているk8sの暫定ベストプラクティスをまとめてみたいと思います。
前提
- GKEでの話
- 弊社の某サービスの一部ページのwebサーバーをk8sで運用してます
構成
構成図
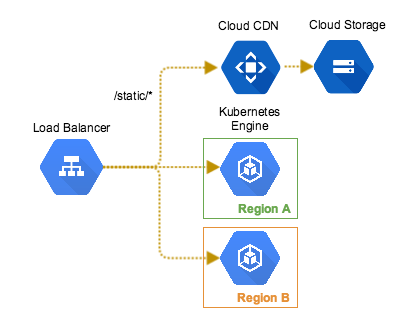
構成について
k8sにはIngressがあるのに、なぜGCPのLoad Balancerを利用しているかというと、いくつか理由があります。
静的コンテンツの配信用に、GCSを利用したい
CDNを使える静的コンテンツ配信サービスを利用したいなと考えた時、GCSをLoad Balancerにぶら下げられるbackend bucketという機能があります。
Ingressを使うことにするとこれが使えなくなってしまうため、LBを利用しています。(代替案は後述)
- マルチリージョンで冗長化
サービスの可用性を担保するため、複数リージョンにクラスタを設置したいのですが、k8sのFederationを検証したところ、まだ本番運用は早そうだという結論に。
代替案として、k8sのクラスタをLoad Balancerの後ろにぶら下げています。
開発周りのあれこれ
LB, GCS, global address, firewall ruleなどのk8sリソース以外のGCPリソースについてはTerraformによって管理しています。それ以外のk8s関連リソース:Docker系やyaml系は一つのレポジトリにまとめてます。
宣伝で恐縮ですがSolution Architect達に聞いたGKEのベストプラクティスを参考に設定しています。
デプロイ
デプロイにおいては、基本的にkubectlで全てCIから行っています。CIはDroneを利用しています。
流れとしては
- docker build
- docker imageに対してserverspecや単体テスト
- テスト通ったらGoogle Container Registry(GCR)にpush
- GCRのimageを指定して
kubectl apply -f
となります。
デプロイした後は、関係者のいるslackチャンネルにデプロイの成否が通知されます。
なお、緊急切り戻し用にrollback.shなども用意し、Tの誰でも対応ができるように準備しています。
各種yamlの設定
kubectl apply -fでdeploymentを更新しますが、このときにrolling updateの設定を一工夫します。
利用できるpod数が極端に減少するタイミングがあると、サービスのレスポンスに影響が出る恐れがあるため、それを防ぐ設定をします。
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 10% # maximum number of Pods that can be created above the desired number of Pods
maxUnavailable: 0% # maximum number of Pods that can be unavailable during the update process.
strategy の部分でこのように設定しておくと、まず新しいdocker imageを持ったpodが作成され、それが利用できる状態になってから既存のpodが消されるようになります。
新しく作成したdocker imageに問題があった場合やpodの作成になんらかの支障があった場合、既存のpodの数は減ることなく、既存のpodにトラフィックが流れるので、安心です。
(テストに穴があると意味ないんですけどね。自戒を込めて…)
maxSurgeを小さめにしておくことで、一回の入れ替えの単位をコントロールできます。ここを過剰にしてしまうと、例えばnodesの計算資源がギリギリのところでpodのやりくりをしていたとき、新しいpodを作成できない状況になります。
クラスタ作成時に --enable-autoscaling を指定すると、nodesの台数も増減可能になるので回避できます。ちょっと時間かかりますが。
テスト
k8sのテストについては良き情報が見つからなかったので、必要に応じて対策をしていきました。
まず、dockerspecを利用すると、作成したimageに対してserverspecを走らせることができます。これで各imageに対してのテストを行います。
さらに疎通テストとして、dockerspecではdocker-composeを内部的に利用できるので、複数のcontainerが立ち上がった状態でテストを走らせることが可能です。
例えばこんなnginxがあったとしますと
# pseudo code
upstream backend1 {
server backend1:80;
}
upstream backend2 {
server backend2:80;
}
server {
location /be1/ {
proxy_pass http://backend1/;
}
location /be2/ {
proxy_pass http://backend2/;
}
}
こんなdocker-composeを用意して
version: '2'
services:
frontend:
image: asia.gcr.io/__GOOGLE_PROJECT__/frontend:latest
volumes:
- /var/run/docker.sock:/var/run/docker.sock
links:
- backend1
- backend2
ports:
- 38080:80
backend1:
image: backend1:latest
expose:
- 80
backend2:
image: backend2:latest
expose:
- 80
こんなテストができます。
describe docker_compose("#{ENV['COMPOSE_FILE']}", wait: 5) do
its_container(:frontend) do
describe 'access to backend 1' do
subject do
command("curl http://127.0.0.1/be1/ -v")
end
its(:stderr) { should match /HTTP\/1.1 200 OK/ }
end
describe 'access to backend 2' do
subject do
command("curl http://127.0.0.1/be2/ -v")
end
its(:stderr) { should match /HTTP\/1.1 200 OK/ }
end
end
end
これはあくまでも擬似的な疎通テストになるため、本来はk8sのクラスタ上でテストすべきかなと思ってます。CI上でminikube使うなど、よりよいテストを模索中。
監視
基本的にはprometheusが王道らしいですね。公式にk8s用のyamlもあり、導入事例も多いです。pod単位でのリソース監視などもでき、詳細な情報が必要な場合はよさそうですね。
現在はTではprometheusは使っておらず、ログは全てstdoutに流してstackdriverに連携し、BigQueryにそのまま流しています。
BigQueryに接続するRedashを立てて、Redashから定期的にnginxのアクセスログなどにクエリを投げて、サーバーのレスポンスタイムなどのダッシュボードを作成しています。
また、500などを検知したらアラートがslackに連携され、開発者にすぐ通知できるようにしています。
将来(検討中)
以上のような形で開発を進めていますが、いくつか構成において改善案を話し合っています。現在の構成はterraformとk8sの分解点が難しく、k8sの可変性が活用できていない部分があります。
-
fuseでGCSをマウント
上の構成ではbackend bucketとcloud CDNを使いたかったのですが、cloud storageをk8sのボリュームとしてマウントする機能があります。
https://karlstoney.com/2017/03/01/fuse-mount-in-kubernetes/ -
Ingressの活用
L7 LBをterraformで作成するよりも、k8sならではのIngressをやはり使いたいですね。マルチリージョンを諦めるか、Federationがナイスに仕上がってFederated Ingressを使うのか。
おわりに
k8sのベストプラクティス、とくにテスト周りや構成・運用などの情報はなかなか見つからず、手探りでこのような状況になりました。
Istioなど新しいものがたくさんでて盛り上がっておりますが、どんどん取り入れてベストプラクティスを追い求めていきたいですね。
もっとよい構成があるよ、みたいなお話をコメントにてお待ちしております!