動機
AIを使って異常検知(製品の良品・不良品を見分ける等)を行いたいと考えたことがある人は多いのではないでしょうか?実際にAIが得意とする分野ではありますが、実際に取り組んでみると、不良画像のデータが十分に収集できない、異常判定の可視化が難しいなど、躓くポイントが多かったりします。
今回は、シンプルな実装かつ最小のリソースで異常検知を実現するための手法の一つとして「オートエンコーダ」と呼ばれるAIモデルを、実際のコードサンプルや動作例と共に紹介したいと思います。
オートエンコーダ(自己符号化器)1
オートエンコーダはニューラルネットワーク構造のパターンの一つで、入力データを一度低次元データに変換するパート(エンコーダ)と低次元データから画像を復元するパート(デコーダ)で構成されます。モデル全体の目的としては、入力データをなるべくそのままに出力することです。
入力データがそのまま出力データとして出てくることに何の意味があるねん、と思われるかもしれません。このAIモデルのミソは「途中で縮小されたデータに変換される」という部分です。これにより、モデルは元データ復元のために限られた情報しか利用できないため、なるべく画像の主要な特徴のみを復元できるように学習されるようになります。復元されたデータからは元データの細部の情報が抜け落ちた状態になります。
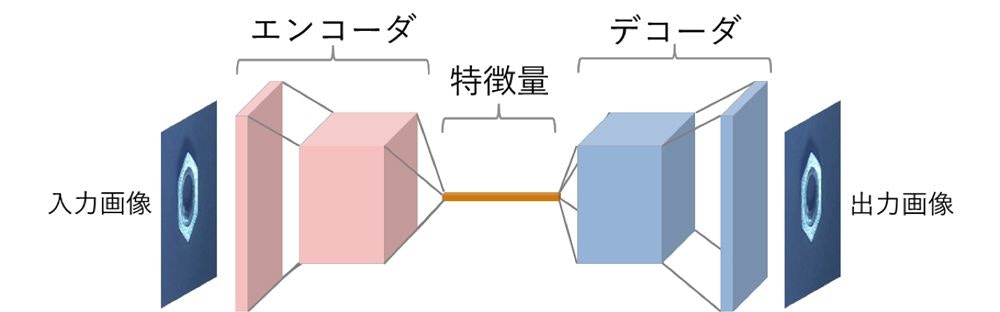
このオートエンコーダの特徴を利用して、データの圧縮やノイズ処理を行うことが可能です。
今回実践する異常検知手法も、オートエンコーダの特徴をうまく利用することによって実現できるものとなっています。
使用ソフトウェアとバージョン
※2022/9/5 Google Colaboratory上実装時点
- Python 3.7.13
- Tensorflow 2.8.2
- その他OpenCV等のライブラリ
データセット作成
今回の記事用AIモデル作成のために、市販のクッキー(形は1種類)を近所のスーパーで買ってきて撮影に使用しました。見ての通り、何の変哲もないクッキーです。

AIモデルの学習用に、割れや欠けのないクッキーを、距離や位置・明るさを少しずつ変化させた画像を100枚撮影しました。

また、異常検知の評価用に、同じ種類のクッキーで正常なものと、割れや欠けのあるものをそれぞれ10枚ほど撮影しました。読者は再現のためにわざわざポケットに入れる必要はありません2。

ソースコード
以下、今回のAIモデル学習に使用したソースコードです。
Tensorflow KerasのFunctional APIによる実装となっています。
注目すべきは、画像からベクトルを出力するエンコーダ部分と、ベクトルから再度画像を生成するデコーダ部分のパラメータが対称的になるように構築する部分です。
※ソースコードは以下の書籍を参考にしました。
生成 Deep Learning3
from tensorflow.keras.layers import Input, Conv2D, Flatten, Dense, Conv2DTranspose, Reshape, Activation, LeakyReLU
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import Adam
import numpy as np
import cv2
import glob
# 学習データの読み込み&前処理
train_images = glob.glob('training_images/*')
train = []
for i in train_images:
image = cv2.imread(i)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
train.append(image)
train = np.array(train)
train = train.astype('float32') / 255
# 学習用ハイパーパラメータ
LEARNING_RATE = 0.0005
BATCH_SIZE = 8
Z_DIM = 100
EPOCHS = 50
# エンコーダ
encoder_input = Input(shape=(300,300,3), name='encoder_input')
x = encoder_input
x = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', name='encoder_conv_0')(x)
x = LeakyReLU()(x)
x = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', name='encoder_conv_0_1')(x)
x = LeakyReLU()(x)
x = Conv2D(filters=64, kernel_size=3, strides=2, padding='same', name='encoder_conv_1')(x)
x = LeakyReLU()(x)
x = Conv2D(filters=64, kernel_size=3, strides=2, padding='same', name='encoder_conv_2')(x)
x = LeakyReLU()(x)
x = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', name='encoder_conv_3')(x)
x = LeakyReLU()(x)
shape_before_flattening = K.int_shape(x)[1:]
x = Flatten()(x)
encoder_output = Dense(Z_DIM, name='encoder_output')(x)
encoder = Model(encoder_input, encoder_output)
# デコーダ
decoder_input = Input(shape=(Z_DIM,), name='decoder_input')
x = Dense(np.prod(shape_before_flattening))(decoder_input)
x = Reshape(shape_before_flattening)(x)
x = Conv2DTranspose(filters=64, kernel_size=3, strides=1, padding='same', name='decoder_conv_t_0')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(filters=64, kernel_size=3, strides=2, padding='same', name='decoder_conv_t_1')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(filters=32, kernel_size=3, strides=2, padding='same', name='decoder_conv_t_2')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(filters=32, kernel_size=3, strides=1, padding='same', name='decoder_conv_t_2_5')(x)
x = LeakyReLU()(x)
x = Conv2DTranspose(filters=3, kernel_size=3, strides=1, padding='same', name='decoder_conv_t_3')(x)
x = Activation('sigmoid')(x)
decoder_output = x
decoder = Model(decoder_input, decoder_output)
# エンコーダ/デコーダ連結
model_input = encoder_input
model_output = decoder(encoder_output)
model = Model(model_input, model_output)
# 学習用設定設定(最適化関数、損失関数)
optimizer = Adam(learning_rate=LEARNING_RATE)
def r_loss(y_true, y_pred):
return K.mean(K.square(y_true - y_pred), axis=[1,2,3])
model.compile(optimizer=optimizer, loss=r_loss)
# 学習実行
model.fit(
train,
train,
batch_size=BATCH_SIZE,
epochs=EPOCHS
)
AIモデルを使用して異常箇所を特定する
学習したAIモデルにクッキーの画像を入力すると、AIモデルが一度低次元ベクトルに変換した後同じ画像を復元しようとするため、大まかな情報(色、大きさ、位置等)はそのままに、細部の情報(穴、ヒビ等)が抜け落ちたような画像が出力されます。
モデル実行方法は非常に簡単で、エンコーダに画像を入力し、得られたデータをデコーダに入力して再構築画像を取得、2枚の画像の差分を取得するには元画像と生成画像を引き算するだけです。以下サンプルコードです。
# 画像の復元
z_points = encoder.predict(original_images)
reconst_images = decoder.predict(z_points)
# 元画像との差分を計算
diff_images = np.absolute(reconst_images - original_images)
以下は正常画像を使用した場合の①入力、②出力、③入力-出力の差分となります。学習時に使用した画像と同じタイプの画像なので、ほぼ差分がなく、AIモデルが元画像を正確に復元できているのがわかります。

対して、異常画像も同様にAIモデルにかけてみた結果が以下となります。クッキーのヒビ、欠け部分というものを学習時に取り込まなかったことにより、不良の情報を学習できなかったため、不良個所の復元がうまくできていないことがわかります。

差分情報を元画像上に赤色で反映すると、以下のようなヒートマップ画像が得られます。AIが不良判定した際、どの部分が不良判定に起因したかが一目でわかってとても便利ですね。

異常検知にオートエンコーダを使うメリット
AIを学びたての方が、異常検知をAIで行う場合に最初に思いつくであろう方法は、画像に正常・異常のラベルを付与して分類タスクにするという方法だと思います。この方法について一般的によく挙げられる問題点として、異常データの収集が難しく、正常データとの数が不均衡なデータ4となってしまうことがあります。また、学習に必要なデータ数、時間も多く、出力形式が「正常」「異常」のラベルのみでその根拠を特定することが難しいという点も挙げられます。オートエンコーダを使った手法では、これらの問題点がすべて解決されているということが、ここまでの記事内容からわかるかと思います。
| 一般的な分類モデルによる手法 | オートエンコーダによる手法 | |
|---|---|---|
| 学習に必要なデータ数 | 数千~数万枚(正常・異常データ両方必要) | ~数百枚(正常データのみ) |
| 学習時間 | 数時間~数日 | 数分~1時間 |
| 異常判定箇所の可視化 | × | 〇 |
まとめ
今回の記事は、AIを使って異常検知をまずは簡単に試してみたい方の参考のために作成しました。
AI Dynamics Japanでは今回紹介したオートエンコーダの他にも、異常検知や差分検知の手法を複数取り揃えています。将来記事ではより性能の高い異常検知モデルについても取り上げたいと考えています。
異常検知AIは工夫次第で様々な現場に応用することができるソリューションです。今回の記事を読んで興味を持っていただけた方、ご自身のビジネスにも取り入れたいと思った方は、是非AI Dynamics Japanにお問い合わせください。
読んでいただきありがとうございました!

(出演:みきをさん @michelle0915(左)、@tech_lady731(右))