はじめに
おはです!
Logstashのフィルタの中でもGrokが好きなぼくが、Advent Calendar11日目を書かせていただきますー
あ、でも今回は、Grokについては書かないですよ!
じゃあ、何書くの?Grokしか脳のないお前が何を書くのさー
そりゃ、あれだよ!Logstash 6.0がGAされたので、待ちに待ったMultiple Pipelinesについて書くしかないでしょ!
てことで、LogstashのMultiple Pipelinesについて、ゆるーく書いていきます( ゚Д゚)ゞビシッ
構成について
今回テストするにあたって使用した構成は以下です。
- Amazon Linux AMI 2017.09.1 (HVM)
- Logstash 6.0
- logstash-input-s3
- Elasticsearch 6.0
- Kibana 6.0
- X-Pack 6.0
ちなみに、もろもろインストールされている前提で記載しています。
もし、インストールする場合は、以下のインストール手順を参考にして頂ければと思います。
Logstashについて
Logstashは、Elasticsearch社が提供するオープンソースのデータ収集管理ツールです。
LogstashのPipelineは、以下のような流れで処理されます。
例として、インプットデータをApacheのログファイルで、ログファイルに対してフィルタをかけ、Elasticsearchにストアするといった流れにしてます。1
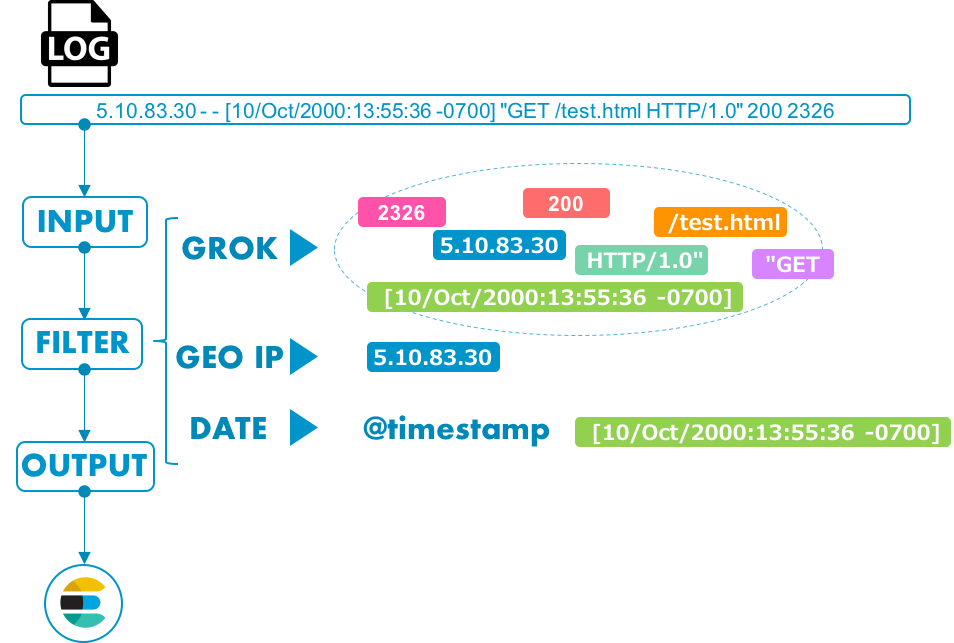
INPUT
様々なデータソースを取り込みたい!そんな要望に応えるべく用意されたのがLogstash。
Logstashは、様々なデータ形式に対応しています。
例えば、ソフトウェアのログ、サーバのメトリクス、Webアプリケーションのデータや、クラウドサービスなど。
FILTER
INPUTしたデータソースをフィルタで解析し、構造化します。
データソースの変換には、正規表現でデータをパースするためのGrokフィルタや、IPアドレスから地理情報を得るためのGeoIPフィルタなど様々なフィルタライブラリが用意されています。
OUTPUT
データを構造化したのち、任意の出力先にデータをストアします。
Elasticsearch以外の出力先も多数提供されているので、環境に合わせてデータをストアします。
Logastashのディレクトリ構成
上記までが処理の流れで、これらの処理を定義するファイルをLogstashでは準備する必要があります。
以下のようにLogstashのディレクトリは構成されており、conf.d配下に定義ファイル(hoge.confと記載)を配置します。
/etc/logstash
├ conf.d
│ └ hoge.conf
├ jvm.options
├ log4j2.properties
└ logstash.yml
hoge.confに様々なデータソースに対して定義します。
例えば、AWSのALBのアクセスログとApacheのアクセスログを定義すると以下のようになります。2
input {
s3 {
tags => "alb"
bucket => "hoge"
region => "ap-northeast-1"
prefix => "hoge/"
interval => "60"
sincedb_path => "/var/lib/logstash/sincedb_alb"
}
file {
path => "/etc/logstash/log/httpd_access.log"
tags => "httpd"
start_position => "beginning"
sincedb_path => "/var/lib/logstash/sincedb_httpd"
}
}
filter {
if "alb" in [tags] {
grok {
patterns_dir => ["/etc/logstash/patterns/cloudfront_patterns"]
match => { "message" => "%{ALB_ACCESS}" }
add_field => { "date" => "%{date01} %{time}" }
}
date {
match => [ "date", "yy-MM-dd HH:mm:ss" ]
locale => "en"
target => "@timestamp"
}
geoip {
source => "c_ip"
}
useragent {
source => "User_Agent"
target => "useragent"
}
mutate {
convert => [ "time_taken", "float" ]
remove_field => [ "message" ]
}
else if "httpd" in [tags] {
grok {
patterns_dir => ["/etc/logstash/patterns/httpd_patterns"]
match => { "message" => "%{HTTPD_COMMON_LOG}" }
}
geoip {
source => "clientip"
}
date {
match => [ "date", "dd/MMM/YYYY:HH:mm:ss Z" ]
locale => "en"
target => "timestamp"
}
mutate {
remove_field => [ "message", "path", "host", "date" ]
}
}
}
output {
if "alb" in [tags] {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "elb-logs-%{+YYYYMMdd}"
}
}
else if "httpd" in [tags] {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "httpd-logs-%{+YYYYMMdd}"
}
}
}
このようにデータソース毎にタグを付与し、if文で判定させるといったかたちになってます。
今回は、データソースが少ないからいいですが、更に増やしていくとなると可読性も悪くなるのと、リソースのハンドリングも難しくなってきます。
また、データソースが増えたり、フィルタ変更などの際には、一つの定義ファイルを更新するため、全体に影響を及ぼす可能性があります。。
なんてこった(´□`;)
Multiple Pipelinesになると何がいいのさ
そこで!Multiple Pipelinesの出番なのです!
hoge.confに対して複数のデータソースを組み込んでいたものを、分割することができちゃうのですー
また、リソースの割り当てとして、Worker数などもPipeline毎に割り当てることができるのです!歓喜!!
ここからは、Multiple Pipelinesをどのように使うのかを書いてきます。
Multiple Pipelinesを試してみる。
Logstashのディレクトリ構成は変わらないのですが、新しくpipelines.ymlという定義ファイルを作成します。
また、先ほどのhoge.confをデータソース毎にファイルを以下のように分けます。
- alb.cfg
- httpd.cfg
alb.cfgの定義は以下です。
input {
s3 {
bucket => "hoge"
region => "ap-northeast-1"
prefix => "hoge/"
interval => "60"
sincedb_path => "/var/lib/logstash/sincedb_alb"
}
}
filter {
grok {
patterns_dir => ["/etc/logstash/patterns/cloudfront_patterns"]
match => { "message" => "%{ALB_ACCESS}" }
add_field => { "date" => "%{date01} %{time}" }
}
date {
match => [ "date", "yy-MM-dd HH:mm:ss" ]
locale => "en"
target => "@timestamp"
}
geoip {
source => "c_ip"
}
useragent {
source => "User_Agent"
target => "useragent"
}
mutate {
convert => [ "time_taken", "float" ]
remove_field => [ "message" ]
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "elb-logs-%{+YYYYMMdd}"
}
}
httpd.cfgの定義は以下です。
input {
file {
path => "/etc/logstash/log/httpd_access.log"
start_position => "beginning"
sincedb_path => "/var/lib/logstash/sincedb_httpd"
}
}
filter {
grok {
patterns_dir => ["/etc/logstash/patterns/httpd_patterns"]
match => { "message" => "%{HTTPD_COMMON_LOG}" }
}
geoip {
source => "clientip"
}
date {
match => [ "date", "dd/MMM/YYYY:HH:mm:ss Z" ]
locale => "en"
target => "timestamp"
}
mutate {
remove_field => [ "message", "path", "host", "date" ]
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "httpd-%{+YYYYMMdd}"
}
}
ディレクトリ構成は以下になります。
/etc/logstash
├ logstash.yml
├ conf.d
│ └ alb.cfg
│ └ httpd.cfg
├ jvm.options
├ log4j2.properties
└ pipelines.yml
ここでやっと登場するpipelines.ymlの定義は以下です。
- pipeline.id: alb
pipeline.batch.size: 125
path.config: "/etc/logstash/conf.d/alb.cfg"
pipeline.workers: 1
- pipeline.id: httpd
pipeline.batch.size: 125
path.config: "/etc/logstash/conf.d/httpd.cfg"
pipeline.workers: 1
めっちゃシンプルですね。
呼び出すファイルパスの指定とパラメータの定義を記載するだけです。
データソース単位でpipeline.workersを割り当てられることになったので、柔軟にコアの配分ができるようになりました。
詳細の設定については、settings fileを確認してもらえればと思います。
動かすよ!
今回、サービス起動を前提としているため、pipelines.ymlを読み込ませるには、logstash.ymlのpath.configをコメントアウトする必要があります。
(ここでハマりました。。公式サイトにサービス起動について書かれているところがみつからず。。)
# path.config: /etc/logstash/conf.d/*.conf
てことで、起動しますー
これでデータソース単位で動かすことができます。
$ initctl start logstash
logstash start/running, process 3121
おまけ
今回説明していないですが、X-Packを導入することで、MonitoringでPipelineの状況をみることができます。
データの流れを把握したり、分岐などのロジックが有効に働いてるかなども確認することが可能です。
先ほど、alb.cfgを取り込んだ際のPipelineは以下の様に表示されます。

さいごに
いかがでしたか?
Multiple Pipelinesは、常にデータを取り込んでいるLogstashを支えるための根幹たる機能ではないでしょうか?
ぜひぜひ、みなさんもMultiple Pipelinesを使って、よりよいLogstsah Lifeを送って頂ければとヽ(*゚д゚)ノ
それでは、Advent Calendar11日目を終わりますー
明日の12日目は、"Elasticsearch v1.7 -> v2.4 -> v5.5 と段階的にバージョンアップした話し"ですね!
楽しみだすー