まずはじめに、本記事では以下のように言葉を定義して話を進めます。
同人オタク = 1次創作や2次創作で同人誌を作ったりしながら過ごしているオタク
この言葉がわからないようであれば本記事はちんぷんかんぷんだと思われます。
Python知見を探して迷い込んでしまった人はもっと良い記事を探すことをお勧めします。
同人オタクはいつだって好意的な感想がほしい(諸説有)
創作しているとやっぱり誰かの反応が欲しくなってくるときがあります。
そんな欲求に応えようとTwitterのフォロワーさんが、感想を届ける敷居を下げよう!ということで可愛らしい感想用カードを用意して、リアルイベントでポストに投函すると作者さんいお届けしてくれる企画をされていました。
さらに現地にこれない方向けに……とGoogleFormsを開放したのですが、
みんな張り切って愛のこもった感想を送ったため、集まったのがなんと3桁件。
フォロワーさんは手書きによる写経を諦め、Formsの回答をcsv出力してなんとかしようとしたが……
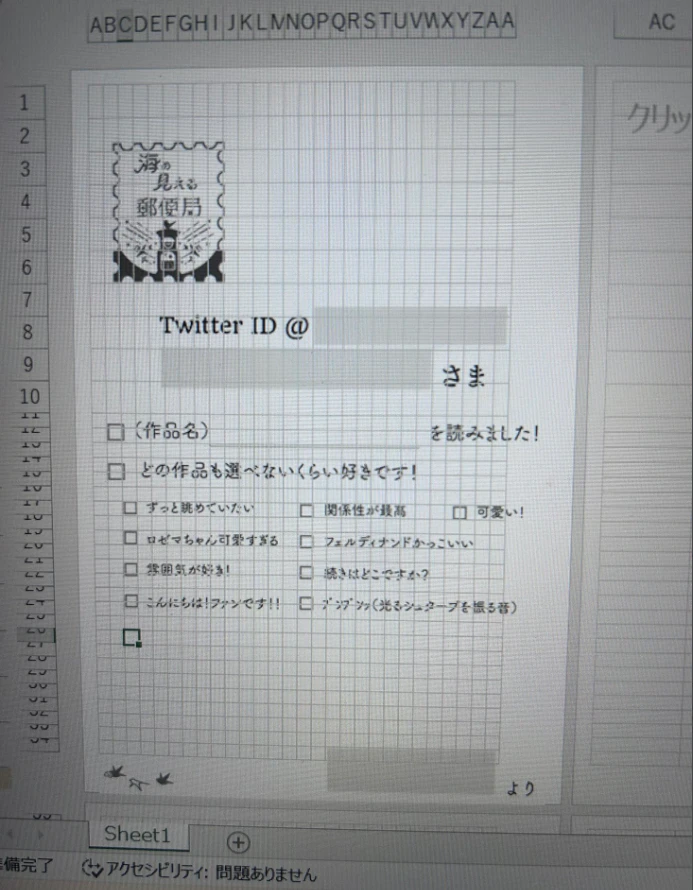
んふふふふふふwwwwwwwwwwwwwww
大変愉快なことになっていたので「てきとう仕事になるかもしれませんが手伝わせてください」と手を挙げたのでした。
やりたいこと
- CSVの内容に応じて、画像にチェックマークや文字を重ねたい
- 主催さん(非エンジニア)のPC環境で実行したい
- 印刷をしやすい形にしたい
本当は2つ目の条件を考えると、GASなどを利用してブラウザ上で簡単に実行できるようにしたかった。
ですがそうなると私の知識では
GASでFormsの結果出力スプレッドシートの内容を取得
→ GAS上で画像と文字を重ねる
→ GoogleドライブにPNGかPDFあたりで出力
ということになるが、GAS上で画像と文字を重ねようと思うとするとWordPressのAPI挟むとか結構大変。
また主催さんにスプレッドシートのIDを取得させたり、GASのセキュリティ許可をさせる方が難易度が高い。
というわけで、申し訳ないがPythonを主催さんには入れていただくことにして、こちらで書いたコードを送付することにしました。
とりあえず実装
csvファイルに存在するデータ列を確認させてもらいます。
| 列名 | 内容 |
|---|---|
| タイムスタンプ | Formに回答が送信された時刻 |
| ID | 宛先の人のTwitterID |
| 宛先 | 宛先の名前 |
| 名前 | 回答者の名前 |
| 特定の作品への感想はその他を選択し…(略 | 「どの作品も選べないくらい好きです!」か作品名のどちらかが入力されている |
| 該当箇所にチェックをして下さい。(複数可) | 画像上のチェックマークに対応する選択肢がカンマ区切りで複数入力されている |
| フリースペースです。ご自由にご記入ください。(空欄も可能) | 日本語で感想が自由に入力されている |
とりあえずそんな突飛なものはなさそうなので例文ファイルを作成して組んでみました。
画像に文字を重ねるのはPillowを使用しています。
コード
import sys
import tkinter
from tkinter import filedialog
import pandas as pd
import PIL # pillow
from PIL import Image, ImageDraw, ImageFont
# 読み込むcsvファイルを選択する
def SelectFile():
FileType = [('CSVファイル', '*.csv')]
fPath = filedialog.askopenfilename( filetypes=FileType )
if fPath == '':
sys.exit()
return fPath
# csvファイルの読み込み
def DataRead(fName):
#Dataframeとして読み込み
df = pd.read_csv(fName, encoding='shift-jis')
header = df.columns.values.tolist()
# インデックスや名前等でソートしたいときはこんな感じ
# df = df.sort_values(header[indexcol])
return df, header
# 画像に文字を重ねる
def layer_up(imgpath, df):
img = Image.open(imgpath)
# PCローカルのフォントへのパスと、フォントサイズを指定
large_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 130)
medium_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 90)
small_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 60)
for index, row in df.iterrows():
imgcopy = img.copy()
draw = ImageDraw.Draw(imgcopy)
print('index ' + str(index))
if str(row[0]) == 'nan':
break
# 送り先のTwitterID
if str(row[1]) != 'nan':
draw.text((1200,970), row[1], 'black', font=large_font)
# 送り先の名前
if str(row[2]) != 'nan':
draw.text((600,1170), row[2], 'black', font=large_font)
# 名前
if str(row[3]) != 'nan':
draw.text((1220,3150), row[3], 'black', font=medium_font)
# 回答の分類
if str(row[4]) != 'nan':
if ('どの作品も選べないくらい好きです!'in row[4]) == False:
draw.text((150,1460), '✓', 'black', font=large_font)
# 作品名
draw.text((700,1520), row[4], 'black', font=medium_font)
else:
draw.text((150,1650), '✓', 'black', font=large_font)
# チェックマーク
if str(row[5]) != 'nan':
if ('ずっと眺めていたい' in row[5]) == True:
draw.text((210,1860), '✓', 'black', font=medium_font)
if ('関係性が最高' in row[5]) == True:
draw.text((1070,1860), '✓', 'black', font=medium_font)
if ('可愛い!' in row[5]) == True:
draw.text((1820,1860), '✓', 'black', font=medium_font)
if ('ロゼマちゃん可愛すぎる' in row[5]) == True:
draw.text((210,2010), '✓', 'black', font=medium_font)
if ('フェルディナンドかっこいい' in row[5]) == True:
draw.text((1070,2010), '✓', 'black', font=medium_font)
if ('雰囲気が好き!' in row[5]) == True:
draw.text((210,2160), '✓', 'black', font=medium_font)
if ('続きはどこですか?' in row[5]) == True:
draw.text((1070,2160), '✓', 'black', font=medium_font)
if ('こんにちは!ファンです!!' in row[5]) == True:
draw.text((210,2310), '✓', 'black', font=medium_font)
if ('ブンブンッ(光るシュタープを振る音)' in row[5]) == True:
draw.text((1070,2310), '✓', 'black', font=medium_font)
# コメント
if str(row[6]) != 'nan':
draw.text((250,2600), row[6], 'black', font=small_font)
# 画像を保存する
imgcopy.save('C:/Users/********/Downloads/umino_mieru_img/' + str(index) + '.png')
if __name__ == "__main__":
strFilePath = SelectFile()
mainDataFrame, mainHeader = DataRead(strFilePath)
layer_up('C:/Users/**********/Downloads/kansoucard.jpg', mainDataFrame)
実行結果

うむ、いいかんじ。
まあそんなにすんなり上手くいくわけもなく
だいたい想定外……というか想定不足のパターンがあるもので、当然のごとくこういうことが起きます。

あーーーーーーーーwwwwwwwww
みんなの愛が…………………………………………………………………………
というわけで、以下の機能を実装しました。
- 指定の文字数毎に改行
- 文字数に応じてフォントサイズを変更
- 。などの1文字だけが1行使ったりしないように1文字の場合は前の行に追加
オタクの愛に応えるにはこれくらいの機能は必要だったみたいです。
コード
import sys
import tkinter
from tkinter import filedialog
import pandas as pd
import PIL # pillow
from PIL import Image, ImageDraw, ImageFont
import textwrap
# 読み込むcsvファイルを選択する
def SelectFile():
FileType = [('CSVファイル', '*.csv')]
fPath = filedialog.askopenfilename( filetypes=FileType )
if fPath == '':
sys.exit()
return fPath
# csvファイルの読み込み
def DataRead(fName):
#Dataframeとして読み込み
df = pd.read_csv(fName, encoding='shift-jis')
header = df.columns.values.tolist()
# インデックスや名前等でソートしたいときはこんな感じ
# df = df.sort_values(header[indexcol])
return df, header
# 画像に文字を重ねる
def layer_up(imgpath, df):
img = Image.open(imgpath)
# PCローカルのフォントへのパスと、フォントサイズを指定
large_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 130)
medium_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 90)
small_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 60)
exsmall_font = ImageFont.truetype('C:/Windows/Fonts/meiryob.ttc', 40)
for index, row in df.iterrows():
imgcopy = img.copy()
draw = ImageDraw.Draw(imgcopy)
print('index ' + str(index))
if str(row[0]) == 'nan':
break
# 送り先のTwitterID
if str(row[1]) != 'nan':
if len(row[1])>10:
draw.text((1200,1000), row[1], 'black', font=medium_font)
else:
draw.text((1200,970), row[1], 'black', font=large_font)
# 送り先の名前
if str(row[2]) != 'nan':
draw.text((600,1170), row[2], 'black', font=large_font)
# 名前
if str(row[3]) != 'nan':
if len(row[3])<=8:
draw.text((1240,3120), row[3], 'black', font=large_font)
elif len(row[3])<=12:
draw.text((1220,3150), row[3], 'black', font=medium_font)
else:
draw.text((1220,3200), row[3], 'black', font=small_font)
# チェックマークの位置
if str(row[4]) != 'nan':
if ('どの作品も選べないくらい好きです!'in row[4]) == False:
draw.text((150,1460), '✓', 'black', font=large_font)
# 作品名
if len(row[4]) < 10:
draw.text((700,1500), row[4], 'black', font=medium_font)
elif len(row[4]) < 15:
draw.text((700,1520), row[4], 'black', font=small_font)
else:
title_list=[]
title_list.extend(textwrap.wrap(row[4], 15))
for i, txt in enumerate(title_list):
draw.text((680,1435+i*65), txt, 'black', font=small_font)
else:
draw.text((150,1650), '✓', 'black', font=large_font)
# 作品チェックマーク
if str(row[5]) != 'nan':
if ('ずっと眺めていたい' in row[5]) == True:
draw.text((210,1860), '✓', 'black', font=medium_font)
if ('関係性が最高' in row[5]) == True:
draw.text((1070,1860), '✓', 'black', font=medium_font)
if ('可愛い!' in row[5]) == True:
draw.text((1820,1860), '✓', 'black', font=medium_font)
if ('ロゼマちゃん可愛すぎる' in row[5]) == True:
draw.text((210,2010), '✓', 'black', font=medium_font)
if ('フェルディナンドかっこいい' in row[5]) == True:
draw.text((1070,2010), '✓', 'black', font=medium_font)
if ('雰囲気が好き!' in row[5]) == True:
draw.text((210,2160), '✓', 'black', font=medium_font)
if ('続きはどこですか?' in row[5]) == True:
draw.text((1070,2160), '✓', 'black', font=medium_font)
if ('こんにちは!ファンです!!' in row[5]) == True:
draw.text((210,2310), '✓', 'black', font=medium_font)
if ('ブンブンッ(光るシュタープを振る音)' in row[5]) == True:
draw.text((1070,2310), '✓', 'black', font=medium_font)
# コメント
if str(row[6]) != 'nan':
if len(row[6]) < 32:
draw.text((250,2600), row[6], 'black', font=small_font)
elif len(row[6]) < 161:
text_list1 = row[6].splitlines() # 改行で分割
text_list2 = []
for txt in text_list1:
text_list2.extend(textwrap.wrap(txt, 32))
# 1文字チェック
text_list3 = []
for i, txt in enumerate(text_list2):
if i == 0:
text_list3.append(txt)
continue
if len(txt) == 1:
text_list3[-1] = text_list3[-1] + txt
else:
text_list3.append(txt)
for i, txt in enumerate(text_list3):
draw.text((230,2500 + i*100), txt, 'black', font=small_font)
else:
text_list1 = row[6].splitlines() # 改行で分割
text_list2 = []
for txt in text_list1:
text_list2.extend(textwrap.wrap(txt, 52))
# 1文字チェック
text_list3 = []
for i, txt in enumerate(text_list2):
if i == 0:
text_list3.append(txt)
continue
if len(txt) == 1:
text_list3[-1] = text_list3[-1] + txt
else:
text_list3.append(txt)
for i, txt in enumerate(text_list3):
draw.text((120,2500 + i*65), txt, 'black', font=exsmall_font)
imgcopy.save('C:/Users/*******/Downloads/umino_mieru_img/' + str(index) + '.png')
if __name__ == "__main__":
strFilePath = SelectFile()
mainDataFrame, mainHeader = DataRead(strFilePath)
layer_up('C:/Users/*******/Downloads/kansoucard.jpg', mainDataFrame)
実行結果

やった~!はいった~~!!!!完!!!!!!!!!!!!
おわりに
というわけでPythonで同人オタクの感想カードを一斉出力する取り組みでした。
Pythonなんて何も分からないながらに、我慢して最後まで読んでみたけどよくわからなかった……という方で、
同様の企画をどうしてもやりたいかたは、私のTwitterまでお気軽にお問い合わせください。