はじめに
久しぶりの投稿です。最近のAI関連の進化が早すぎて、情報を追うだけでも一苦労です。
さて、以前からAIエージェントによる自動コーディングをやってみたいと考えていました。ようやく構想が少し形になってきたので、記事にしてみることにしました。
いざ自分の環境でAIエージェントを動かそうとすると、APIの課金が気になります。かといって、ローカルでコーディングができるLLM(大規模言語モデル)を動かせるほどのVRAMを積んだGPUも手元にありません。
手詰まりに感じていたのですが、オンラインで無料のGPU環境を活用して自分用のAPIサーバーを作る方法に辿り着いたので、備忘録として手順を残します。
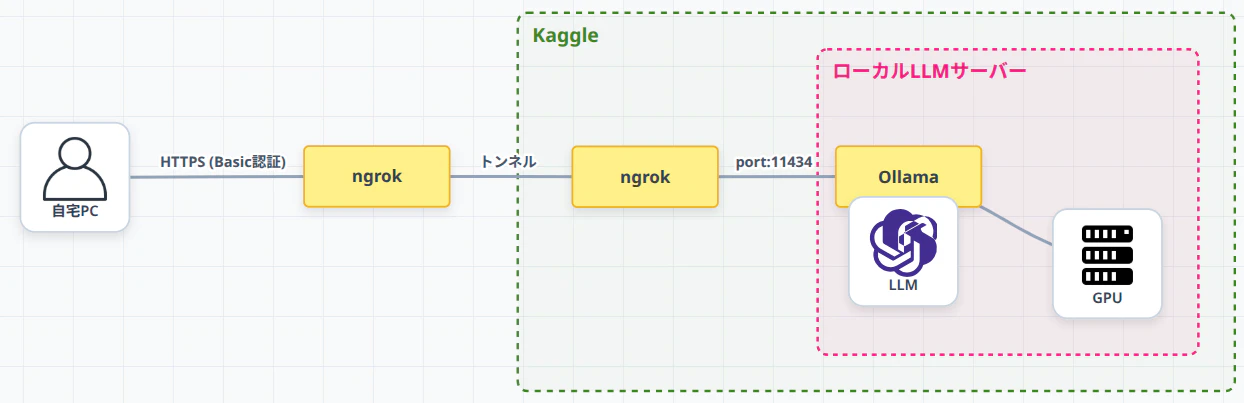
本記事では、Kaggleの無料GPU(16GB VRAM × 2枚)を利用して自分専用のLLM APIサーバーを構築し、ngrok経由で自PCから利用する方法 を説明します。
構成
- Kaggle(クラウド): 実行環境。無料でもT4 GPUが1週間で30時間まで利用可能です。ここでLLMを稼働させます。
- ngrok(トンネル): API公開サービス。Kaggle上で動くローカルサーバーのポート(11434)を、インターネット越しにアクセスできるようにトンネリングします。
- Ollama(オラマ): ローカル環境でLLMを簡単にダウンロード・実行できるプラットフォーム。今回はKaggleのGPU環境にインストールし、コーディング用APIサーバーとして機能させます。
- クライアント(自PCなど): ngrokが発行したURLをエンドポイントとして設定し、手元のPCからAPI経由でLLMを利用します。
 |
手順1. ngrokのAuthtokenを取得
Kaggleのローカル環境を外部公開するために、ngrokのアカウントを作成します。
- ngrokの公式サイトにアクセスし、無料アカウントを作成してログインします。
- ダッシュボード左側のメニューから
Authtoken>Add Authtokenからトークンを追加します。

- 追加したトークンのトークン文字列をコピーしておきます。
手順2. Kaggleでの事前準備
Kaggle Notebook(ブラウザ上でPythonコードなどを実行できる環境)を作成し、環境を整えます。
-
Kaggleの公式サイトにアクセスし、無料アカウントを作成してログインします。
-
Kaggleで新しいNotebookを作成します。
-
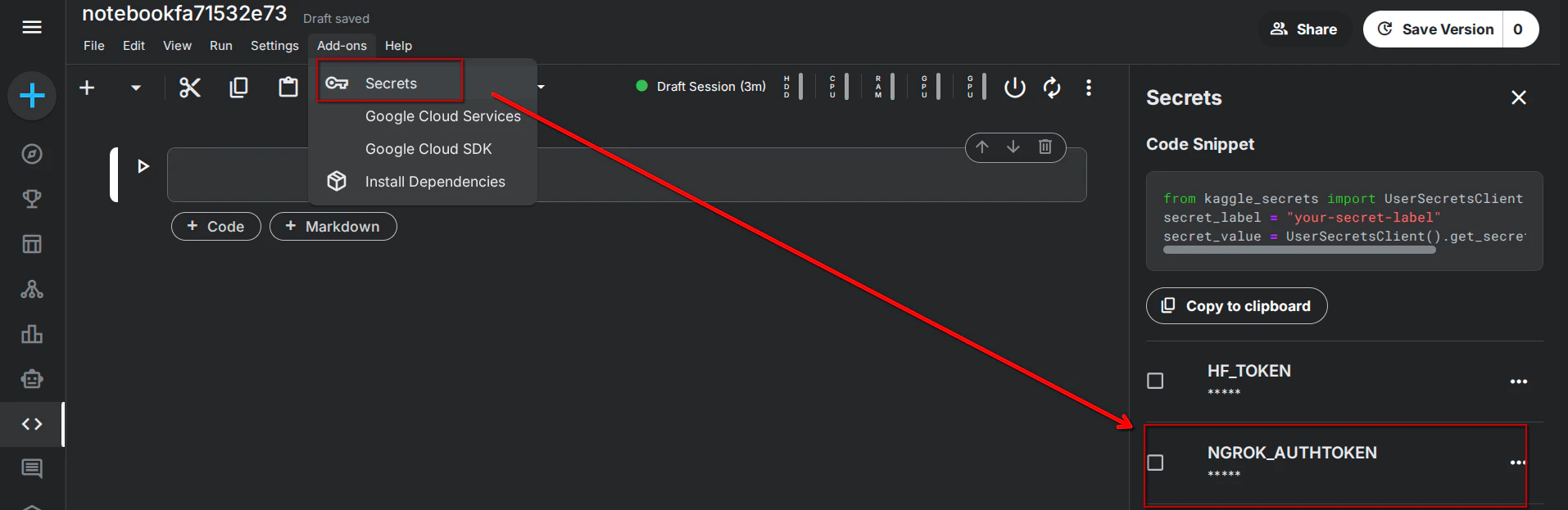
トークンの保存: 画面上部の
Add-ons->Secretsを開き、LabelにNGROK_AUTHTOKEN、Valueに先ほどコピーしたトークンを入力して保存します。
-
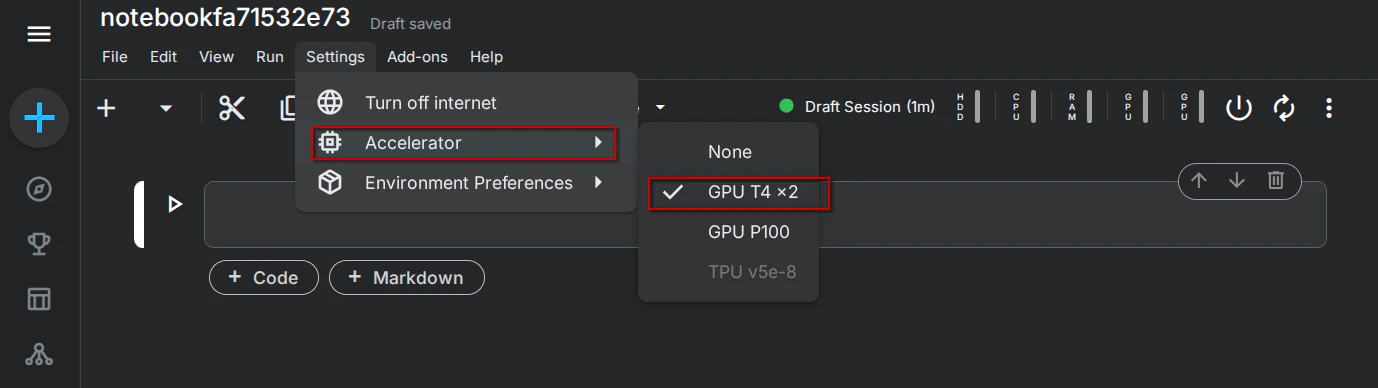
GPUの有効化: 画面右側の設定パネル(Notebook options)を開き、「Accelerator」を「GPU T4 x2」に変更します。
(※GPUを利用するには、Kaggleアカウントに携帯電話番号を登録してSMS認証(Verification)を完了させておく必要があります)
-
インターネット接続: 同じ設定パネル内の「Internet」が「On」になっていることを確認します。

手順3. Kaggle上でAPIサーバーを構築・公開する
KaggleのNotebookには「セル」と呼ばれるコードの入力・実行ブロックがあります。以下のコードを別々のセルに貼り付け、上から順に実行(再生ボタンをクリック)するだけで、APIサーバーが立ち上がります。
セル1:OS依存ツールのインストールとGPU確認
KaggleはLinuxベースのPython実行環境です。先頭に ! をつけることでOSコマンドを実行できます。
# 依存ツールとハードウェア認識ツールのインストール
!apt-get update && apt-get install -y zstd pciutils
# GPUの状態確認
!nvidia-smi
実行後、T4 GPUが2枚認識されている表が出力されれば成功です。

セル2:Ollamaのインストールと外部公開設定
Ollamaはデフォルトでローカルホスト(Kaggle内部)以外からの接続を拒否するため、環境変数でCORSポリシーを緩和し、ngrokからのアクセスを許可します。
import os
import subprocess
import time
# 1. Ollamaのインストール
!curl -fsSL https://ollama.com/install.sh | sh
# 2. サーバー起動設定
OLLAMA_PATH = "/usr/local/bin/ollama"
custom_env = os.environ.copy()
custom_env["OLLAMA_HOST"] = "[::]:11434" # 外部アクセスを許可
custom_env["OLLAMA_ORIGINS"] = "*" # CORSポリシーの緩和
custom_env["OLLAMA_KEEP_ALIVE"] = "-1" # モデルをメモリに常駐させる
# バックグラウンドでOllamaサーバーを起動
with open("ollama.log", "w") as log_file:
# 既存プロセスを掃除
subprocess.run(["pkill", "-9", "ollama"], check=False)
# 外部アクセスを許可した状態で起動
subprocess.Popen([OLLAMA_PATH, "serve"], env=custom_env, stdout=log_file, stderr=log_file)
print("Waiting for Ollama server to start...")
time.sleep(12)
# 起動確認
!/usr/local/bin/ollama --version

セル3:モデルのダウンロードとngrokでの公開
LLMモデルをプルし、Basic認証をかけてngrokで公開します。
※モデルはお好みで。gemma4:26b は、おすすめです。
# モデルのダウンロード
!/usr/local/bin/ollama pull gemma4:26b
!pip install -q pyngrok
from pyngrok import ngrok
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
NGROK_TOKEN = user_secrets.get_secret("NGROK_AUTHTOKEN")
# セキュリティのためのBasic認証設定(必ず任意のものに変更してください)
BASIC_AUTH_USER = "your_username"
BASIC_AUTH_PASS = "your_password"
ngrok.set_auth_token(NGROK_TOKEN)
try:
# 既存のトンネルがあれば切断
tunnels = ngrok.get_tunnels()
for t in tunnels:
ngrok.disconnect(t.public_url)
# 11434ポートをBasic認証付きで公開
public_url = ngrok.connect(11434, auth=f"{BASIC_AUTH_USER}:{BASIC_AUTH_PASS}")
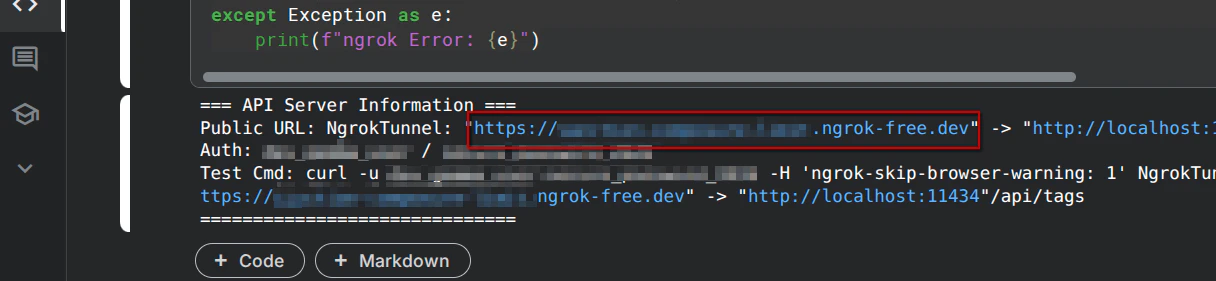
print("=== API Server Information ===")
print(f"Public URL: {public_url}")
print(f"Auth: {BASIC_AUTH_USER} / {BASIC_AUTH_PASS}")
print(f"Test Cmd: curl -u {BASIC_AUTH_USER}:{BASIC_AUTH_PASS} -H 'ngrok-skip-browser-warning: 1' {public_url}/api/tags")
print("==============================")
except Exception as e:
print(f"ngrok Error: {e}")

出力された Public URL: のURL(例: https://xxxx-xx-xx-xx.ngrok-free.app)をメモしておきます。
手順4. 自PCからインターネット越しにAPIを利用する
サーバーが立ち上がったら、ローカルのターミナルやプログラムから呼び出してみます。
curlを使ったテスト実行
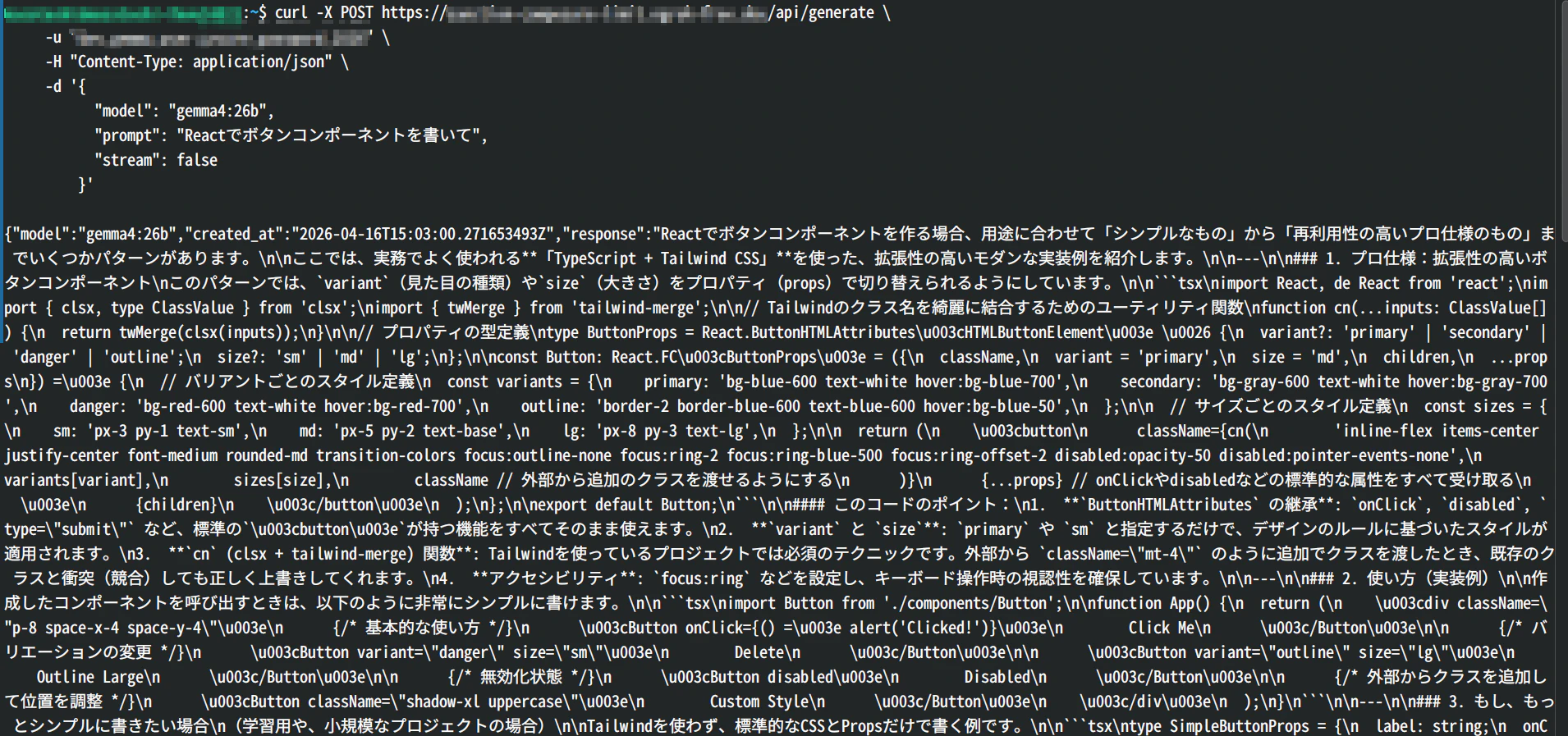
ターミナルから以下のコマンドを実行します。(URL、ユーザー名、パスワードはご自身のものに置き換えてください)
curl -X POST https://<取得したngrokのURL>/api/generate \
-u "your_username:your_password" \
-H "Content-Type: application/json" \
-d '{
"model": "gemma4:26b",
"prompt": "Reactでボタンコンポーネントを書いて",
"stream": false
}'
 |
※初回のアクセスは、モデルがVRAMにロードするために応答が返ってくるまで数分かかります。
⚠運用上の注意点(セッション切れ)
Kaggle Notebookは、ブラウザでの操作がない状態(アイドル状態)が約40分続くとインスタンスが停止してしまいます。セッションが切れてしまった場合は、1つめのセルから順番に動かしてください。
APIサーバーとして長時間稼働させたい場合は、Kaggleの画面右上にある「Save Version」から「Save & Run All(バックグラウンド実行)」を選択することで、最大12時間連続稼働させることができるようですが、うまく継続させるためには何かコツが必要そうです。まずはインタラクティブモード(ブラウザを開きっぱなし)での検証をおすすめします。
おわりに
Kaggleとngrokで、実質無料でそこそこ実用的(個人の趣味レベルです(汗))なAIバックエンドを構築できました。
次はこのAPI環境を利用して、ほったらかしでコーディングとテストをするような、自動開発を試す予定です。形になってきたら、また記事にしようと思います。下記は作成中のスクショの一部です。


