(ブログ記事からの転載)
タイトルがいきなり何だ?という話ですが、
先日の記事でも言及した、創業記念で打ち出そうと考えているデータサイエンスコンペティションのアイデアをご紹介します。
この内容は、先日参加した技術アウトプットもくもく会でも発表させていただいたものです。
ちなみに、このもくもく会はとてもハイレベルなMLエンジニアの方が集まっており、そんな中もくもく中に突如思い立ってLT資料を作り、LTデビューでお話しするという暴挙に出ましたが、温かい雰囲気で見守っていただきました。皆さまも参加をオススメします。
[https://connpass.com/event/139640/]
さて、本題に戻ります。
データサイエンスコンペティションって何?という方向けに30文字くらいで説明すると、「データサイエンティストが自分のモデルを戦わせて、最も良い性能のモデルをクライアント企業が手に入れ、データサイエンティストは名誉と賞金を手に入れる」というものです…全然30文字は無理でしたね。伝わるかな…
Kaggleはじめ強力な競合もいる中で、差別化方針は目下検討中ですが、兎にも角にも、コンペの数と面白さがないと話にならないと思っています。
本当はコンペ主催企業が提供するデータが量的にも質的にも面白いわけですが、今まさに創業という段階なので、まずはパブリックデータで自社主催のコンペを行いたいと考えています。
その中の1つのアイデアが、AIは芥川龍之介を見分けられるか?です。青空文庫さんが提供されている著名な作家の過去作品データを使い、芥川龍之介が執筆した作品かどうかを機械学習で判定するモデルを作るというものです。
実際にコンペにかけるデータセットや評価指標はコンペ公開時に確認いただくとして、
今日はチュートリアル的な形で、モデル構築・評価・結果分析までの一連のプロセスを簡単に行ってみた結果を書きます。
生データ取得・内容確認
青空文庫の全データはGitHubから取得できます。
[https://github.com/aozorabunko/aozorabunko]
zipを解凍するとかなり多くのフォルダが確認できますが、cardsフォルダ以下に作品本文のデータがあります。
zipファイルを解凍するとtxtファイルが得られます。中身を見てみましょう。
蜘蛛の糸
芥川龍之介
-------------------------------------------------------
【テキスト中に現れる記号について】
《》:ルビ
(例)蓮池《はすいけ》のふち
|:ルビの付く文字列の始まりを特定する記号
(例)丁度|地獄《じごく》の底に
[#]:入力者注 主に外字の説明や、傍点の位置の指定
(数字は、JIS X 0213の面区点番号、または底本のページと行数)
(例)※[#「特のへん+廴+聿」、第3水準1-87-71]
-------------------------------------------------------
[#8字下げ]一[#「一」は中見出し]
ある日の事でございます。御釈迦様《おしゃかさま》は極楽の蓮池《はすいけ》のふちを、独りでぶらぶら御歩きになっていらっしゃいました。池の中に咲いている蓮《はす》の花は、みんな玉のようにまっ白で、そのまん中にある金色《きんいろ》の蕊《ずい》からは、何とも云えない好《よ》い匂《におい》が、絶間《たえま》なくあたりへ溢《あふ》れて居ります。極楽は丁度朝なのでございましょう。
やがて御釈迦様はその池のふちに御佇《おたたず》みになって、水の面《おもて》を蔽《おお》っている蓮の葉の間から、ふと下の容子《ようす》を御覧になりました。この極楽の蓮池の下は、丁度|地獄《じごく》の底に当って居りますから、水晶《すいしよう》のような水を透き徹して、三途《さんず》の河や針の山の景色が、丁度|覗《のぞ》き眼鏡《めがね》を見るように、はっきりと見えるのでございます。
(中略)
しかし極楽の蓮池の蓮は、少しもそんな事には頓着《とんじゃく》致しません。その玉のような白い花は、御釈迦様の御足《おみあし》のまわりに、ゆらゆら萼《うてな》を動かして、そのまん中にある金色の蕊《ずい》からは、何とも云えない好《よ》い匂が、絶間《たえま》なくあたりへ溢《あふ》れて居ります。極楽ももう午《ひる》に近くなったのでございましょう。
[#地から1字上げ](大正七年四月十六日)
底本:「芥川龍之介全集2」ちくま文庫、筑摩書房
1986(昭和61)年10月28日第1刷発行
1996(平成8)年7月15日第11刷発行
親本:筑摩全集類聚版芥川龍之介全集
1971(昭和46)年3月〜11月
入力:平山誠、野口英司
校正:もりみつじゅんじ
1997年11月10日公開
2011年1月28日修正
青空文庫作成ファイル:
このファイルは、インターネットの図書館、青空文庫(http://www.aozora.gr.jp/)で作られました。入力、校正、制作にあたったのは、ボランティアの皆さんです。
上記のように、著者名や作品名の後に青空文庫にて付した記号の説明があり、本文中にはルビや注記の記号が含まれています。
ちなみに得られたtxtファイルは15167ありました。これに対する記号付与がボランティアの方々によって行われたということなので、頭が下がりますね。
今回のタスク設定ですが、「芥川龍之介含む作品数上位10人の作家に絞った計4732作品に対する芥川作品か否か?の分類」としたいと思います。
本当はMulti-Classの分類タスクにしたかったのですが、敢えてそうしませんでした。理由はご想像ください(多分にビジネス的理由です)。
データ加工
説明変数となるデータを作品本文のみとしたいので、ヘッダーとフッターを削除します。
本文中の記号は普通は除去するものと思いますが、ルビの数(時代が古いほど増える?)など、特徴量として分類に効く可能性がないでもないので、残した方がコンペ的には面白いかもしれません。
今回は簡単のため、記号は全て削除します。
特徴量作成
説明変数となるデータは作品本文のみなので、この自然言語からどう特徴量を作るかが非常に重要となってきます。
通常のコンペではここがデータサイエンティストの腕の見せ所ですが、今回は考察を加えるため、解釈性の高い特徴量としてtf-idf値を採用します。
まず、形態素解析を行い、分かち書きします。形態素解析辞書として、mecab-ipadic-nelogd(mecabのversion=0.996)を使いました。
その上でtf-idf値を計算します。
簡単のため、tf-idf値の合計の大きい上位300単語のみを抽出した、300次元のベクトルでテキストを表します。
idf値を求める式は、tfidfvectorizerライブラリの定義に従っているので、総文書数$N$、単語$t$が出現する文書数$df(t)$に対して、以下の定義となります。
$idf(t)=log\frac{N}{df(t)+1}$
ここまでのコードをまとめて記載します。
import codecs
from tqdm import tqdm
import csv
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
DIR = './input/aozorabunko-master/cards/'
# データ加工
import re
import MeCab
def extractauthor(text):
"""
著者抽出
"""
text = re.sub('\n\n', '\n', text)
text = re.sub('\u3000', '', text)
text = re.sub('\r', '', text)
if re.search('-{5,}', text): # 記号の説明セクションがある場合
text = re.split('-{5,}',text)[0]
return text.split('\n')[-3]
else: # 記号の説明セクションがない場合
return text.split('\n')[1]
def extractbody(text):
"""
本文抽出
"""
# ヘッダーの除去
if re.search('-{5,}', text): # 記号の説明セクションがある場合
text = re.split('-{5,}',text)[2]
else: # 記号の説明セクションがない場合
text = '\n'.join(text.split('\n')[2:])
# フッターの除去
text = re.split('底本:',text)[0]
# | の除去
text = re.sub('[||]', '', text)
# ルビの削除
text = re.sub('《.+?》', '', text)
# 入力注の削除
text = re.sub('[#.+?]', '',text)
# 空行の削除
text = re.sub('\n\n', '\n', text)
text = re.sub('\u3000', '', text)
text = re.sub('\r', '', text)
return text
def parsetext(text):
"""
形態素解析
"""
node = tagger.parseToNode(text)
l = []
while node:
if node.feature.split(',')[6] != '*':
l.append(node.feature.split(',')[6])
else:
l.append(node.surface)
node = node.next
return ' '.join(l)
paths = glob(DIR + '*/files/unzip/*.txt')
tagger = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd -Owakati')
tagger.parse('')
dic = {}; dic_author = {}
for path in tqdm(paths):
try:
with codecs.open(path, 'r', 'cp932', 'ignore') as f:
text = f.read()
author = extractauthor(text)
text = parsetext(extractbody(text))
l_path = path.split('/')
if len(text) >= 10: # 本文がないファイルが含まれているため、10文字以上のみ抽出
if l_path[4] not in dic_author.keys():
dic_author[l_path[4]] = author
dic[l_path[4]] = {}
dic[l_path[4]][l_path[7].split('.')[0]] = text
else:
print('too few letters at {}'.format(path))
except:
print('read error at {}'.format(path))
continue
# 作品数上位10名のみ抽出
nkey = lambda x: len(dic[x].keys())
authors_top10 = [i[0] for i in sorted({x : nkey(x) for x in dic.keys()}.items(), key=lambda x: -x[1])[:10]]
dic_top10 = {i : dic[i] for i in authors_top10}
print('対象作家: {}'.format([dic_author[i] for i in authors_top10]))
# 特徴量作成:tf-idf値でテキストをベクトル化
from sklearn.model_selection import train_test_split
author = [1 if k == '000879' else 0 for k,v in dic_top10.items() for vv in v.values()]
body = [vv for k,v in dic_top10.items() for vv in v.values()]
df = pd.DataFrame({'author':author, 'body':body})
from sklearn.feature_extraction.text import TfidfVectorizer
X_text = list(df['body'].values)
y = df['author'].values
vec_tfidf = TfidfVectorizer(max_features=300, norm='l2')
X = vec_tfidf.fit_transform(X_text)
feature_names = vec_tfidf.get_feature_names()
# コンペデータ作成
df_vec = pd.concat([pd.DataFrame({'author':y}),pd.DataFrame(X.toarray())], axis=1)
df_train, df_test = train_test_split(df_vec, test_size=0.3, random_state=42, stratify=df_vec['author'])
X = df_train.loc[:, df_train.columns != 'author'].values
y = df_train['author'].values
今回の分析対象作家を確認しておきます。
知らない作家の方が結構いて、ドメイン知識の大きな不足を感じます…
対象作家: ['宮本百合子', '岸田國士', '小川未明', '坂口安吾', '野村胡堂', '芥川龍之介', '牧野信一', '豊島与志雄', '寺田寅彦', '太宰治']
モデル作成・評価
どのようなモデルを作るかもデータサイエンティストの活躍どころですが、ここも今回はシンプルに行います。決定木系の3つのアルゴリズムを採用します。
- 決定木
- ランダムフォレスト
- LightGBM
決定木系のアルゴリズムの中で、シンプルなもの(プレーンな決定木)から高度なもの(勾配ブースティング)までアルゴリズムを3つ選びました。
いずれもハイパーパラメータチューニングはせず、サクッと結果を確認します。
いずれもmetricはAUCとして学習を行います。
決定木
まず、決定木で分類を行います。
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import metrics
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=0)
clf = DecisionTreeClassifier(random_state=0)
clf = clf.fit(X_train, y_train)
pred = clf.predict(X_val)
fpr, tpr, thresholds = metrics.roc_curve(y_val, pred, pos_label=1)
print('AUC:{}'.format(metrics.auc(fpr, tpr)))
AUC:0.8057660410601587
AUCは0.81程度となりました。続いて木構造の可視化もしてみます。
import pydotplus
from IPython.display import Image
from graphviz import Digraph
from sklearn.externals.six import StringIO
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data, feature_names=feature_names, max_depth=3)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("output/dtree.pdf")
Image(graph.create_png())

「ふる」「こう」「といふ」といった語が分類に効くようです。
ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf = clf.fit(X_train, y_train)
pred = clf.predict(X_val)
fpr, tpr, thresholds = metrics.roc_curve(y_val, pred, pos_label=1)
print('AUC:{}'.format(metrics.auc(fpr, tpr)))
AUC:0.688807218218983
ランダムフォレストの方が決定木よりAUCが悪いですね。ハイパラのチューニングをしていないからか…
LightGBM
import lightgbm as lgb
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=0)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_val, y_val, reference=lgb_train)
params = {
'objective': 'binary',
'metric':'auc'
}
model = lgb.train(params, lgb_train, valid_sets=lgb_eval, verbose_eval=50, early_stopping_rounds=100, feature_name=feature_names)
y_val_pred = model.predict(X_val, num_iteration=model.best_iteration)
fpr, tpr, thresholds = metrics.roc_curve(y_val, y_val_pred)
print('AUC:{}'.format(metrics.auc(fpr, tpr)))
Training until validation scores don't improve for 100 rounds.
[50] valid_0's auc: 0.986553
[100] valid_0's auc: 0.986747
Did not meet early stopping. Best iteration is:
[44] valid_0's auc: 0.987273
AUC:0.9872726015079201
本命のLightGBMでは、AUCが0.987まで到達し学習がストップしました。おや…?
テストデータについても推論を行ってみます。
# テストデータでAUC確認
X_test = df_test.loc[:, df_train.columns != 'author'].values
y_test = df_test['author'].values
y_test_pred = model.predict(X_test, num_iteration=model.best_iteration)
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_test_pred)
print('AUC:{}'.format(metrics.auc(fpr, tpr)))
# ROC曲線を描画
plt.figure(figsize=(12,8))
plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc)
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.savefig('output/roc_curve_lgb.png')
plt.show()
plt.close()
AUC:0.9836128048780488
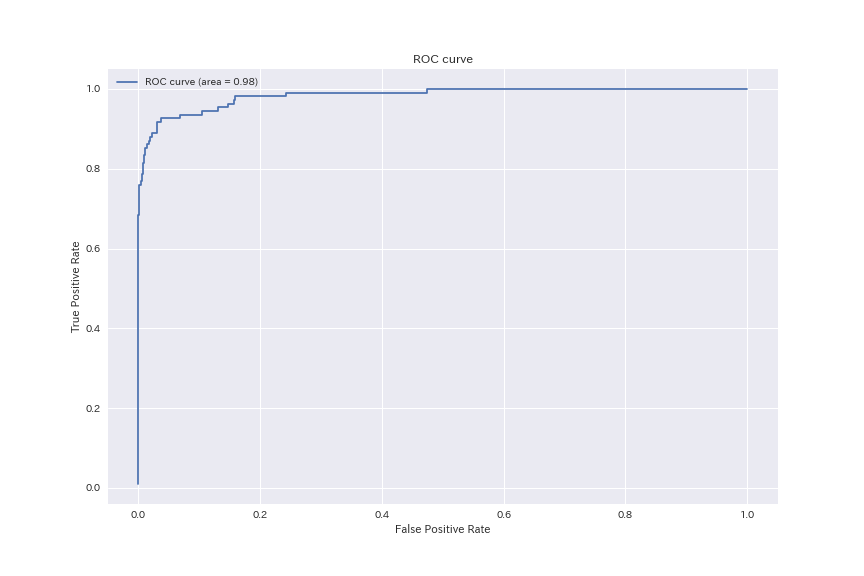
AUCはほぼ変わらず0.984という高い値。
ROC曲線も上図の通り、天井に張り付いています。
うわっ…、私のタスク簡単すぎ…?
タスク設計が悩ましいところですが、先に進みます。
正(芥川の作品である)と判定する閾値を、バリデーションデータを使って探索的に決定します。
この閾値を適用して、テストデータについてConfusion Matrixを得ます。
# f1値が最大になる閾値を探索
th = 0
th_bst = 0
f1_bst = 0
while th <= 1:
tn, fp, fn, tp = metrics.confusion_matrix(y_val, (y_val_pred >= th)*1).ravel()
precision = tp/(fp+tp)
recall = tp/(fn+tp)
f1 = 2*precision*recall/(precision+recall)
if f1_bst < f1:
th_bst = th
f1_bst = f1
th += 0.1
print('f1値が最大になる閾値: {}'.format(th_bst))
# 混同行列
tn, fp, fn, tp = metrics.confusion_matrix(y_test, (y_pred >= th_bst)*1).ravel()
print('正解率: {}'.format((tn+tp)/(tn+fp+fn+tp)))
precision = tp/(fp+tp)
recall = tp/(fn+tp)
print('F1値: {}'.format(2*precision*recall/(precision+recall)))
# Confusion Matrix描画
df_cm = pd.DataFrame(np.array([[tp,fn],[fp,tn]]), index=['actual_positive','actual_negative'], columns=['predict_positive', 'predict_negative'])
plt.figure(figsize=(9,6))
sns.set(font_scale=1.2)
sns.heatmap(df_cm, cmap="Blues", annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.savefig('output/confusion_matrix_lgb.png')
plt.show()
plt.close()
f1値が最大になる閾値: 0.1
正解率: 0.973943661971831
F1値: 0.8355555555555555
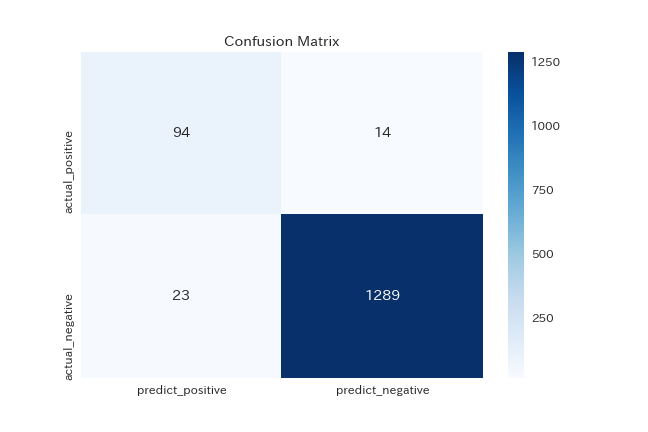
今回は無対策のまま突き進んでいますが、改めてかなりの不均衡データになっていることが確認できます。
F1値は0.836。この値の良し悪しは判断難しいところ。もくもく会でも、F値は閾値によって大きく変わるので絶対的な評価は難しいですよね、という意見をいただきました。
結果分析
ランダムフォレストやLightGBMでは、特徴量の重要度を算出することができます。
今回はLightGBMで特徴量の重要度上位30語を抽出してみます。
# 特徴量の重要度をプロット
lgb.plot_importance(model, figsize=(12,8), max_num_features=30)
plt.savefig('output/feature_importance_lgb.png')
plt.show()
plt.close()
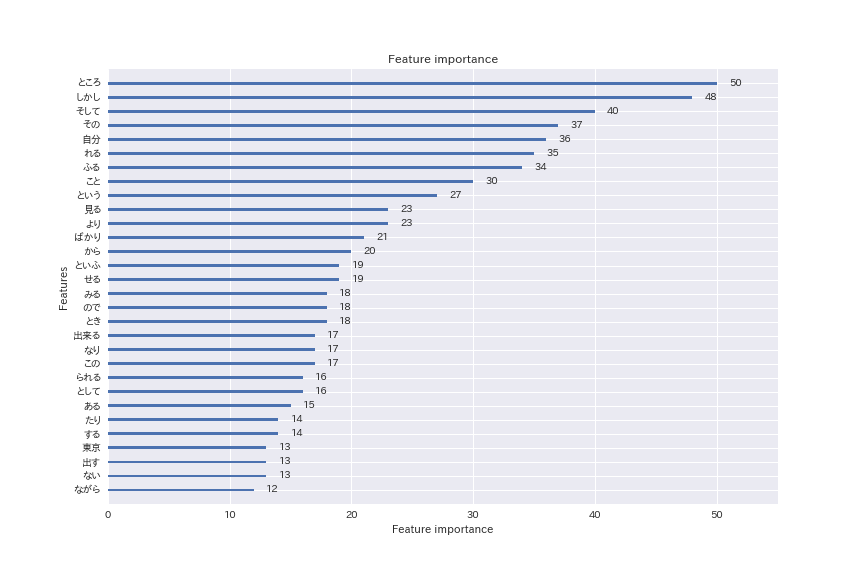
本当はここから何か言いたかったのですが…「ところ」「しかし」「そして」など、上位に出てくる単語は一般的な語ばかり。
当たり前ですが、芥川作品を一発で見分けるような特徴的な語というのは存在しないようです。
もう少し深掘りしてみます。特徴量の重要度上位30語について、クラス(芥川/芥川以外)ごとのtf-idf値の平均値を比較します。
# クラスごとの特徴量の平均値プロット
d_feature = {}
for fn, fi in zip(feature_names, model.feature_importance()):
d_feature[fn] = fi
sorted_feature_names = [i[0] for i in sorted(d_feature.items(), key=lambda x:-x[1])][:30]
X_feature = []
for fn in sorted_feature_names:
X_feature.append([np.mean(X[(y == 1), feature_names.index(fn)]), np.mean(X[(y == 0),feature_names.index(fn)])])
df_feature = pd.DataFrame(X_feature, index=sorted_feature_names, columns=['芥川', '芥川以外'])
df_feature.plot.bar(figsize=(12, 8))
plt.title('クラスごとの特徴量の平均値(重要度トップ30)')
plt.savefig('output/mean_feature_value_lgb.png')
plt.show()
plt.close()
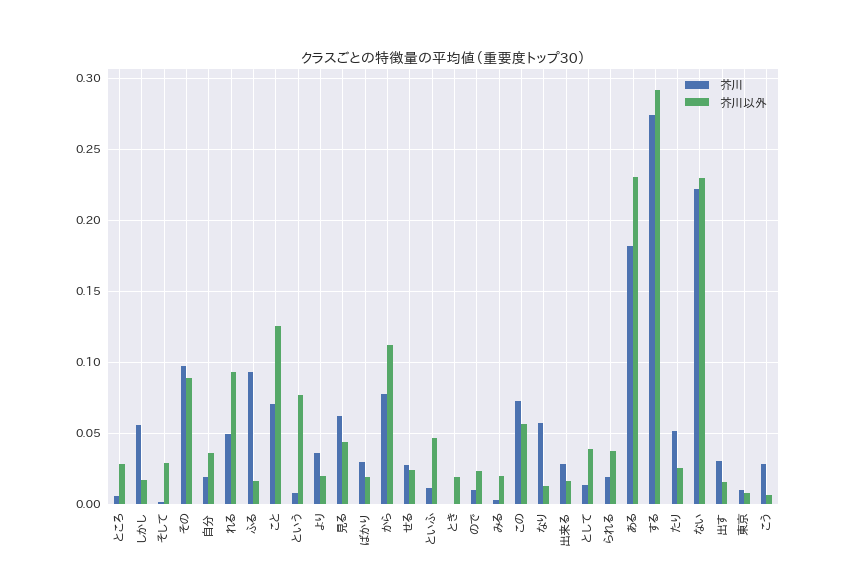
多少特徴が見えてきます。
芥川の方が目立ってスコアが大きい語として、「しかし」「ふる」「なり」などがあります。
こういった語は芥川作品において出現頻度も高く、かつ分類器の特徴量としても重要である、ということが分かります。
「しかし」が多いというのは、作品の転調が多いのが芥川の作風なのかもしれません。
ただ、「しかし」は分かるが、「ふる」「なり」って何?と初見では思います。
原文を見てみましょう。
(原文) -> (形態素解析後)
それは諺《ことわざ》に云ふ群盲《ぐんもう》の象を撫《な》でるやうなもの -> それ は 諺 に 云 ふる 群盲 の 象 を 撫でる やう だ も
それも笑ふばかりならよろしうございますが -> それ も 笑 ふる ばかり だ よろしい う ござる ます
何でかばふ。その猿は柑子盗人だぞ -> 何で かば ふる 。 その 猿 は 柑子 盗人 だ ぞ
綿綿《めんめん》と不幸なる僕等に教《おしへ》を垂《た》れる -> 綿綿 と 不幸 なり 僕 等 に 教 を 垂れる
少くとも善良なる僕等には甚だ迷惑 -> 少い とも 善良 なり 僕 等 に は 甚だ 迷惑
僕等に同情して横暴なる歌人や俳人の上に敢然と -> 僕 等 に 同情 する て 横暴 なり 歌人 や 俳人 の 上 に
まず「ふる」については、「云ふ」「笑ふ」などの「ふ」が形態素解析で基本形に変換した結果「ふる」になっているものが多いようです。
形態素解析辞書が現代語を対象としたものなので(かつneologdもSNSで使われる語などを取り入れているものなので)、時代を遡るほどこのように解析が難しくなってくるのは致し方ないところかと思います。
一方で「なり」は分かりやすく、形容動詞の語尾で「不幸なる」「善良なる」などの「なる」を変換したものが多いようです。
まとめると、「○ふ」「○なり」といった表現が芥川作品においては多いという特徴があるようです。
まとめ
文学作品についてのドメイン知識が私にないのであっさりした分析になってしまいましたが、時代背景や作風を踏まえた特徴量を定義できると、より分類器の性能が上がり、より深い考察ができると思います。
ドメイン知識との融合で精度が上がる瞬間がコンペの1つの醍醐味ではないかと思うので、この辺りの知識の補完がコンペで起こって行ったら良いな…と思います。
基本的な内容ながら、思いのほか長文になってしまいました。
読みづらい箇所も多かったと思いますが、ここまで読んでいただきありがとうございました!
P.S.
上記コンペ開催時には、プレ会員登録いただければサービスローンチ時にいち早くお知らせしますし、私のTwitterやブログ上でも告知しますので、楽しみにお待ちいただければと思います!
(19/7/2 追記)
杏仁まぜそばさんから2点ご指摘いただきました。
- 判別問題ならidfはいらなくてtfだけを特徴量にしても結果は変わらない。その時、決定木の可視化は「どの単語が何回以上何回以下なら芥川」という非常にわかりやすいものになる(精度は変わらない)
TfidfVectorizerの呼び出しでuse_idf=Falseと引数を指定すると、純粋なtf値でベクトルが計算されます。
from sklearn.feature_extraction.text import TfidfVectorizer
X_text = list(df['body'].values)
y = df['author'].values
vec_tfidf = TfidfVectorizer(max_features=300, norm='l2', use_idf=False) # idfを使わない場合
X = vec_tfidf.fit_transform(X_text)
feature_names = vec_tfidf.get_feature_names()
決定木を描画してみます。

- LightGBMの重要度についてsplitになってる気がしますが、gainと指定してあげたほうがより意味のある重要度が出てくる
LightGBMのdocumentによると、splitとgainの定義は以下の通り。確かにgainの方が良さそうです。
importance_type (string, optional (default="split")) – How the importance is calculated. If “split”, result contains numbers of times the feature is used in a model. If “gain”, result contains total gains of splits which use the feature.
引数をgainに変えて、重要度を描画してみます。
# 特徴量の重要度をプロット
lgb.plot_importance(model, figsize=(12,8), max_num_features=30, importance_type='gain')
plt.savefig('output/feature_importance_lgb.png')
plt.show()
plt.close()
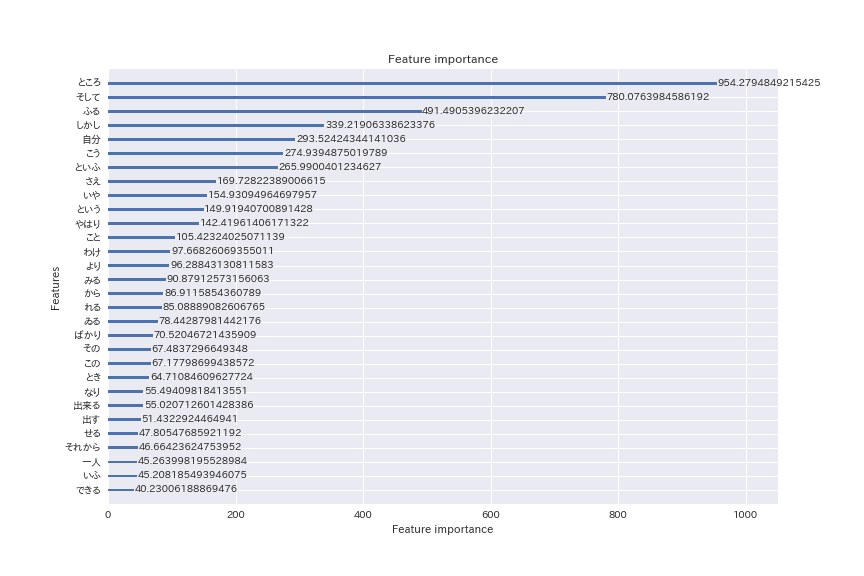
上位に出てくる特徴量が変わりました。
「ところ」「そして」などの重要度が抜けて高いようです。先の分析によれば、いずれも芥川作品ではあまり登場しないという意味で、特徴的なようです。