「AIでSQLが書けるようになった」という話は、もう珍しくありません。では、その先に何があるのか。OpenAIが2026年1月に公開した「自社データエージェント」の記事は、単なる社内事例紹介にとどまらず、これから多くの企業が目指す社内AIエージェントの本命像を、かなり具体的に見せてくれています。
本記事では、OpenAI公式ブログ「OpenAI の自社データエージェントの内部」の内容を、IT技術者が明日の設計に活かせる形で整理します。元記事は日本語で読めるため、概要を把握したうえで必要に応じて直接参照できるよう、ポイントと出典を明記していきます。
関連記事: エージェントの任せ方や社内システムへの組み込みは、AIエージェントを使うとき、どこまで任せてどこで止める?やAIを使うから任せるへ——社内システム設計とエージェントアーキテクチャ、賢いモデルを探す競争は終わった——次世代AIで勝つ設計と運用で深掘りできます。筆者の記事一覧もあわせてどうぞ。
なぜ「SQLが書ける」だけでは足りないのか
OpenAIの記事が面白いのは、「AIでSQLを書けるようになった」というよくある話で終わっていない点です。焦点はそこではなく、大規模組織のデータ環境で、本当に使える分析エージェントをどう成立させるかにあります。
3,500人・70,000データセット・600PB超——規模が変わると難所も変わる
OpenAI社内では、3,500人以上が利用するデータ基盤上に、70,000のデータセット、600PB超のデータがあるとされています(元記事「カスタムツールが必要だった理由」)。この規模になると、もはや問題は「SQLを書けるか」ではありません。
本当の難所は、次のような文脈・慣習・運用知識を含んだ推論です。
- どのテーブルを使うべきか
- 似た名前のテーブルの違いは何か
- どの結合が正しいか
- その指標定義は社内でどう解釈されているか
- 過去の失敗パターンをどう避けるか
元記事では、180行を超えるSQLの例が示されており、「正しいテーブルを結合し、正しいカラムに対してクエリを実行しているかを判断するのは容易ではない」と述べられています。つまり、スキーマやメタデータだけでは、正しい分析には届かないという現実が、はっきりと書かれているのです。
単なるRAGや自然言語SQL変換では届かない
OpenAIはこの問題に対して、単なるRAG(文書検索)や自然言語SQL変換ではなく、データ探索+コード理解+組織知識+メモリ+自己修正を統合したエージェントを構築しています。この設計思想が、IT技術者にとって最も刺さる部分です。
IT技術者が読む価値がある理由——6層のコンテキスト設計
この話は、データ基盤担当者だけの話ではありません。社内向けAIエージェントを設計している人、LLMを業務システムや分析基盤に接続しようとしている人、RAGだけでは精度が足りないと感じている人ほど、刺さる内容です。
なぜなら、「社内文書を埋め込んで検索させれば何とかなる」という発想の限界を、OpenAIが明確に示しているからです。
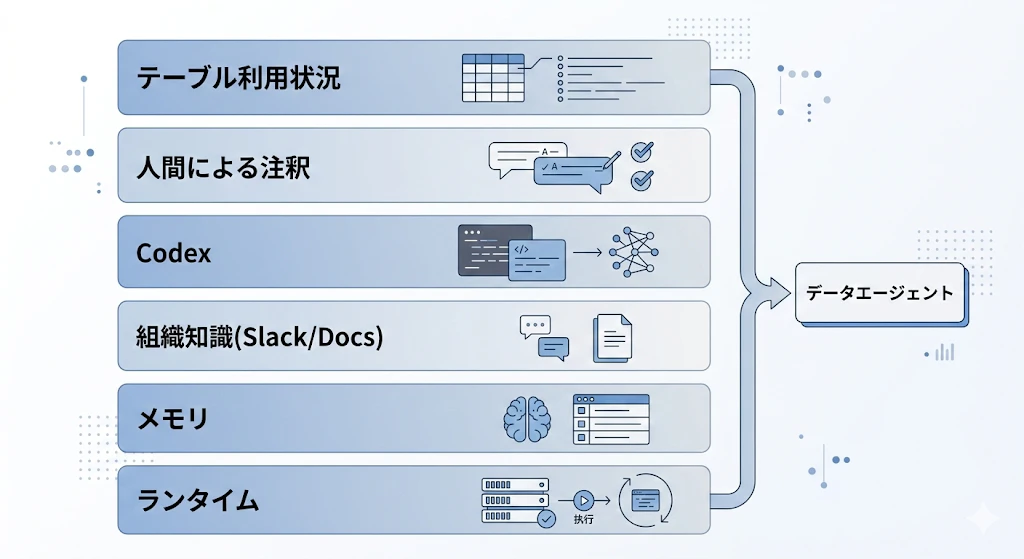
6層のコンテキスト——構造化・非構造化・コード・運用を全部つなぐ
OpenAIのエージェントは、少なくとも次の6層のコンテキストを使っています(元記事「コンテキストがすべて」)。
| レイヤー | 内容 |
|---|---|
| #1 テーブル利用状況 | 過去のクエリ、スキーマメタデータ、テーブル系統(上流・下流の関係) |
| #2 人間による注釈 | ドメイン専門家によるテーブル・列の説明、意図・セマンティクス・既知の注意事項 |
| #3 Codexエンリッチメント | コードベースから導出したテーブル定義、値の一意性・更新頻度・データ範囲 |
| #4 インスティテューショナルナレッジ | Slack・Google Docs・Notionなど、組織の文書・権限・キャッシュ |
| #5 メモリ | ユーザーが修正した内容、発見された微妙な差異を次回以降に再利用 |
| #6 ランタイムコンテキスト | メタデータサービス・Airflow・Sparkとの通信、必要時のライブクエリ |
ここが重要です。「正しい答え」を出すために、構造化データ・非構造化文書・コード・運用知識・対話履歴・その場の追加確認を全部つないでいるのです。本番運用で困るのは、モデルの賢さより、文脈不足と運用知識の欠落である——という視点が、具体的なアーキテクチャとして示されています。
元記事では、これらのコンテキストを日次オフラインパイプラインで集約し、Embeddings APIでベクトル化してRAGで取得する構成が説明されています。つまり、意味はコードと運用に宿るという実務感覚が、設計に反映されているわけです。
面白いのは「AIが賢い」ことではなく、「失敗前提で設計している」こと
この記事でもう一つ注目すべきなのは、OpenAIがエージェントを最初から間違うものとして設計していることです。
クローズドループの自己修正——途中でズレたら戻せるかが本質
エージェントは一発で正解する前提ではなく、途中結果を見て、
- 行数がゼロになった
- 結合がおかしい
- フィルタ条件が怪しい
- 期待した分布にならない
といった異常を見つけると、自分で原因を探り、やり方を修正して再試行します(元記事「仕組み」)。このクローズドループの自己学習プロセスにより、ユーザーの代わりにエージェント自体が反復作業を行うため、手動のワークフローよりも迅速で一貫した高品質の分析が可能になっている、と説明されています。
実運用では、最初の生成結果そのものよりも、途中でズレた時に戻せるかのほうが重要です。この「失敗前提の設計」は、今後の業務エージェントでかなり本質的なポイントになります。
メモリで組織の暗黙知を蓄積する
さらに興味深いのは、ユーザーが修正した内容をメモリとして保存し、次回以降に再利用できる点です。元記事では、実験ゲートで定義された特定の文字列との照合に依存するフィルタリングを、メモリによって正しく行えるようになった事例が紹介されています。
つまりこのエージェントは、単なる問い合わせツールではなく、組織の暗黙知を少しずつ取り込んでいく学習インターフェースになっています。業務AIの価値は、モデル単体の性能だけではなく、その会社固有の知識を、どれだけ再利用可能な形で蓄積できるかで決まる——という示唆が得られます。
AIエージェントの評価——ソフトウェアテストの発想で継続評価
AIエージェントの議論では、しばしば「すごいデモ」は見えても、どう品質保証しているのかが曖昧なまま終わることがあります。この記事はそこも逃げていません。
Evals APIによる継続的な回帰検知
OpenAIは、自然言語の質問に対して期待されるgolden SQLを人手で用意し、生成されたSQLの文字列一致ではなく、
- SQLの妥当性
- 実行結果の一致度
- 許容できる差分の有無
を含めて評価していると説明しています(元記事「Moving fast without breaking trust」)。つまり、エージェントをソフトウェアテストの発想で継続評価しているわけです。Evalsは開発中に継続的に実行され、本番ではカナリアとして回帰を検知する役割を担っています。
LLMアプリをPoC止まりにしたくない技術者にとって、この部分は特に重要です。AIエージェントは、動けばよいのではなく、回帰をどう検知するかが本番運用の核心になります。
セキュリティ設計——pass-through型と検証可能性
セキュリティの扱いも、かなり現実的です。
既存のアクセス制御をそのまま継承する
エージェントは新しい強権的な権限を持つのではなく、既存のアクセス制御をそのまま継承するpass-through型として動作します(元記事「Agent security」)。ユーザーが見られる範囲しか問い合わせできず、権限がなければ代替データセットにフォールバックする設計です。
可観測性と検証可能性で信頼を支える
さらに、推論内容や実行内容、クエリ結果へのリンクを示して、ユーザーが検証可能な形にしています。業務エージェントの信頼性は「正答率」だけではなく、可観測性と検証可能性でも支えられる——という設計思想が読み取れます。
元記事から学べる3つの教訓
OpenAIは、エージェント構築の過程で得た実践的な教訓を3つ挙げています(元記事「Lessons learned」)。IT技術者が設計に落とし込む際のヒントになります。
RAGだけでは足りない——意味はコードと運用に宿る
文書検索だけでは、テーブルの意味、コード由来の制約、組織独自の定義までは拾えません。スキーマやクエリ履歴はテーブルの形と使い方を説明するが、真の意味はそれを生成するコードに宿る——という教訓が、Codexによるコードベースのクロールとして具体化されています。
ツールは多ければよいわけではない
初期にはツールをたくさん見せすぎて、かえってエージェントが混乱したと述べられています。機能の重複は人間には分かりやすくても、エージェントには曖昧さを生む。責務分離と選択のしやすさが、ツールの豊富さより重要だという教訓です。
ゴールを導け、パスは任せる
細かく手順を指定するプロンプト(highly prescriptive)は、かえって結果を悪化させたそうです。多くの質問は似た分析の形を持つが、詳細は十分に異なるため、厳格な指示はエージェントを誤った経路に押しやってしまう。高レベルのガイダンスに切り替え、GPTの推論に適切な実行パスを選ばせることで、ロバストさと結果の質が向上した、と説明されています。
こんな人は特に元記事を読む価値がある
この元記事は、次のテーマに関心がある人ならかなり面白く読めます。
- 社内データ基盤にAIを載せたい
- AIエージェントを業務導線に組み込みたい
- LLMの精度向上を「プロンプト改善」以上のレイヤーで考えたい
- AIをソフトウェア工学としてどう評価・改善するか知りたい
- 「文脈」「権限」「メモリ」「検証」を含めた実装論を見たい
派手な未来像よりも、実際に動くエージェントをどう設計したかに興味があるIT技術者にとっては、密度の高い内容です。元記事では、Slack・Web・IDE・MCP経由のCodex CLI・内部ChatGPTアプリなど、複数の導線から利用できることや、週次レポートやテーブル検証といったワークフロー化の事例も紹介されています。
まとめ——「AIが組織の文脈を背負って分析業務をやりきる」時代へ
この記事の読みどころは、「OpenAIがすごいものを作った」という話ではありません。むしろ本質は、AIエージェントを現場で使えるものにするには、何が足りないのかをかなり具体的に見せてくれる点にあります。
一言でいうと、この記事は 「AIがSQLを書く時代」の先にある、「AIが組織の文脈を背負って分析業務をやりきる時代」 を、夢物語ではなく、
- データ基盤
- 権限管理
- コード理解
- メモリ
- Evals
- セキュリティ
- ワークフロー化
という、極めてエンジニアリング寄りの視点で語っています。だからこそ、IT技術者が読む価値があります。
詳細はOpenAI公式ブログ「OpenAI の自社データエージェントの内部」で確認できます。日本語で読めるため、本記事で概要を掴んだうえで、必要に応じて元記事を参照してみてください。
作成日:2026年3月19日