生成AIが現場に入ってきたこの数年で、私たちの仕事はたしかに変わりました。ドキュメントの初稿は速くなり、コード補助は当たり前になり、調査や要約の立ち上がりも軽くなりました。けれど、ここで一度立ち止まって見ると、いま起きている変化の多くは「個人の作業速度を上げる」段階に集中しています。便利さは十分に実感できる一方で、部門をまたぐ業務全体の流れは、まだ人間の調整力に大きく依存したままです。
このギャップこそが、これから3〜5年の主戦場になります。AIの進化は、単体ツールの高性能化ではなく、仕事の単位そのものを「タスク」から「ワークフロー」へ、さらに「組織横断の意思決定ループ」へ広げる方向で進んでいます。言い換えると、AI活用は「どう上手に聞くか」から「どこまで任せ、どこで人が責任を持つか」を設計する競争に移りつつあります。
この記事では、その進化を3つのステップで整理します。いずれも机上の未来予想ではなく、すでに始まっている技術潮流を土台にした現実的な見取り図です。マルチエージェントシステム、API連携、運用監視、リスク管理まで含めて、IT技術者が明日から設計に落とせる形でつなげていきます。
ステップ1は「個人最適」の完成度を上げる段階
最初の段階で起きるのは、個々の担当者がAIアシスタントを使って作業時間を短縮する変化です。提案書の叩き台、仕様の言い換え、テストケースの草案、問い合わせ返信の文面候補など、単発タスクに対する生産性は目に見えて向上します。ここで重要なのは、AIが人間の判断を置き換えるのではなく、人間が判断しやすい素材を高速で用意する点です。
ただし、この段階には構造的な限界があります。AIがどれだけ優秀でも、次のアクションを決めるのが毎回人間である限り、処理全体のスループットは人間の速度で頭打ちになります。たとえば問い合わせ対応を考えると、返信文の生成は速くなっても、在庫確認、返品可否判定、配送手配、履歴登録といった後続処理は担当者の手でつないでいく必要があります。結果として、ボトルネックは「書く作業」から「つなぐ作業」へ移るだけで、業務の待ち時間そのものは思ったほど減りません。
ここで見えてくるのは、AI活用の本質がプロンプトの巧拙だけでは決まらないという事実です。次の段階に進むには、AIに回答させる設計から、AIに実行させる設計へ切り替える必要があります。この転換点がステップ2です。
ステップ2は「部門ワークフロー」をAIに任せる段階
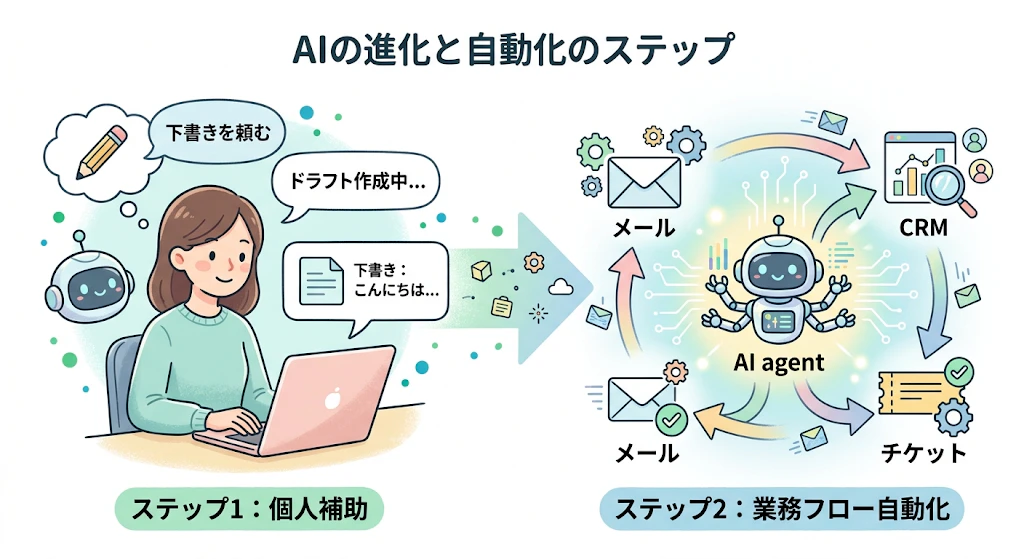
ステップ2では、AIは会話の相手から、業務処理の実行主体へ変わります。ここで鍵になるのが、ツール接続と状態管理です。AIが自律的に仕事を進めるには、メール、CRM、在庫、課金、チケット管理、ナレッジベースなど複数システムを横断して操作できなければいけません。つまり、単体モデルの賢さより、API連携の設計品質が成果を左右します。
実装イメージを具体化するために、カスタマーサポートの流れを見てみます。顧客から破損返品の連絡が入ると、AIエージェントは文面を理解するだけでなく、注文情報を照会し、保証条件を確認し、交換在庫を引き当て、顧客への一次返信を生成し、必要なら倉庫への依頼チケットまで起票します。ここまでを一つの流れとして処理できれば、担当者は例外案件の判断に集中でき、平均応答時間と一次解決率の両方を改善しやすくなります。
この段階でつまずきやすいのは、連携先システムが想定以上に不揃いなことです。古い基幹系はAPIが弱く、SaaSごとに認可方式が異なり、監査ログの粒度も統一されていないことが珍しくありません。だからこそ、先に「何を自動化するか」を決めるのではなく、「どの連携が安定して再実行可能か」を起点に対象業務を選ぶほうが成功率が上がります。設計の現場では、きれいな理想より、失敗時に巻き戻せる現実解が強いです。
さらに、エージェント運用には可観測性が必須です。どの判断でどのAPIを呼び、どこで失敗し、なぜ再試行したのかを追跡できないと、障害時の説明責任を果たせません。ここで効いてくるのが、従来のDevSecOpsと同じ発想です。実行ログ、ポリシー違反検知、権限境界、デプロイ前検証を最初から組み込むことで、AIは「便利だけど怖い存在」から「管理可能な実行基盤」へ変わります。
ステップ3は「エージェント同士の協業」で全体最適を狙う段階
ステップ3では、単一エージェントの自動化を超えて、複数の専門エージェントが役割分担しながら協業します。ここでいうマルチエージェントシステムの価値は、単なる並列実行ではありません。ある部門で起きた変化が別部門の意思決定に即座に反映される、いわば組織の神経網を高速化する点にあります。
製造業の調達を例にすると、この違いがはっきり見えます。外部リスクを監視するエージェントが供給停止リスクを検知した瞬間、調達エージェントは代替ベンダーを探索し、物流エージェントは輸送経路とコストを再計算し、財務エージェントは利益見通しを更新し、営業エージェントは顧客説明の文面を準備します。人間は最後に承認・差し戻しを判断するだけで、部門横断の調整に要する時間を大幅に圧縮できます。

この段階で重要なのは、エージェントを増やすこと自体ではありません。全体最適の鍵は、責務の分離と合意プロトコルです。どのエージェントが何を決め、どこから先は人間承認が必須か、衝突した提案をどう解決するかを明文化しておかないと、システムは賢くなるほど不安定になります。組織設計の言葉でいえば、権限移譲のルールが曖昧なまま優秀な人材を増やしても、会議が増えるだけなのと同じです。
ここで近年の標準化動向が効いてきます。モデルと外部ツールの接続を共通化しようとする取り組みは、実装の属人化を減らし、ベンダーロックインの圧力を下げるうえで有効です。代表的な参照点として、Model Context Protocolの仕様公開があり、ツール連携の共通土台として議論が進んでいます(Model Context Protocol Specification)。また、リスク管理の枠組みではNISTのAI RMFが、役割分担と統制の設計に実務的な軸を提供しています(NIST AI Risk Management Framework)。
ここで混同しやすい「MCP」と「Agent」の違い

実務でよく出る質問が、「MCPとAgentは何が違うのか」です。結論から言うと、Agentは仕事を進める主体で、MCPはその主体が外部ツールを安全に使うための接続ルールです。役割が違うので、どちらか一方だけでは業務自動化は完成しません。
少しかみ砕くと、Agentは「目標から行動計画を作り、実行し、結果を見て次を決める」存在です。一方のMCPは「どのツールに、どんな形式で、どんな権限でアクセスするか」をそろえるインターフェースです。つまり、Agentは意思決定のレイヤー、MCPは接続と実行のレイヤーだと捉えると整理しやすくなります。
たとえばサポート業務なら、Agentは「返品可否を判定し、一次返信を作る」という流れを担当しますが、在庫照会APIやチケット起票APIにアクセスする手段を統一してくれるのがMCPです。MCPがあることで、ツールごとの接続実装を何度も書き直す負担が減り、監査や権限管理の設計も共通化しやすくなります。逆に言えば、MCPだけ導入しても自律実行は始まりませんし、Agentだけ作っても接続のばらつきで運用が壊れやすくなります。
この関係は、アプリケーションとネットワークの関係に近いです。アプリが業務ロジックを担い、ネットワークが通信を支えるように、Agentが業務判断を担い、MCPがツール連携の土台を担います。設計の現場では、両者をセットで考えることで、拡張性と統制を同時に取りやすくなります。
先に進める企業が少ない本当の理由は「技術不足」ではない
ステップ2とステップ3へ進む企業が限られる理由は、モデル精度の不足より、企業側の準備不足にあります。現場で特に大きいのは、データ、接続性、ガバナンスの三つです。
第一に、データが機械可読な単位で整っていない問題です。規程、手順、過去対応履歴がファイル単位で散在していると、AIは文面生成はできても、業務判断に必要な根拠を安定して引けません。第二に、API接続の不均一です。認証方式や更新頻度がバラバラだと、エージェントは環境差分に振り回され、運用コストが急増します。第三に、権限委譲のルール不足です。どこまで自動実行を許容するかが曖昧なままでは、事故を恐れて本番投入できず、PoCで止まり続けます。
この三つは別々に見えて、実際は一つの問題です。つまり「AIを使う準備」ではなく、「AIが働ける職場設計」が不足しているということです。人間にとって自然な曖昧さは、エージェント運用では障害要因になります。逆にいえば、業務ルールを明確化し、接続を標準化し、監査可能性を担保できれば、モデルを少し入れ替えても運用は崩れにくくなります。
これからの進め方は「小さく任せて、大きく統治する」
では、IT技術者はどこから着手すればよいのでしょうか。答えは、全社展開を急ぐことではなく、業務フローを小さく切って委任単位を設計することです。たとえば「問い合わせ受信から一次返信まで」「請求差異検知から確認依頼まで」のように、成功条件と失敗時の巻き戻しを定義しやすい単位で始めます。ここで大切なのは、精度100%を待たないことです。再試行戦略、人的承認ポイント、ログ監査を先に置けば、70点の自動化でも十分に価値を出せます。
そのうえで、次の段階ではエージェント間連携を増やします。単体最適を積み上げるだけでは、組織全体の待ち時間は消えません。部門境界をまたぐ地点に優先順位を置き、引き継ぎロスを減らす設計へ移すと、ROIが見えやすくなります。最終的には、技術力の差より「統治しながら任せられる設計習慣」が競争力になります。
この視点は、これまでの公開記事で触れてきた論点ともつながります。AIエージェントの状態管理を扱った話題や、運用観測を軸にしたロードマップ設計の話題と組み合わせると、導入と運用を分断せずに進めやすくなります(筆者のQiita公開記事一覧)。
AI活用の次の勝負は、モデルの比較表では決まりません。誰がどこで判断し、どこから先を機械に委任し、何をもって安全とみなすか。その設計を組織として言語化できるかどうかで差がつきます。だからこそ、いま必要なのは「より賢いAIを探すこと」よりも、「AIが確実に働ける業務構造を先に作ること」です。指示する仕事から委任する仕事へ。この移行を設計できるチームが、3〜5年後の標準を先に取りにいくはずです。
作成日: 2026年3月31日