はじめに:世界と日本のギャップ
2026年1月、ダボス会議(世界経済フォーラム)でMicrosoftのCEO、サティア・ナデラ氏は「AIはスペクタクル(見世物)からサブスタンス(実質)へ」と語り、生成AIがPoC段階を通過して実用化フェーズに入ったことを明確にしました。一方で、Gartnerの調査によると、生成AIプロジェクトの30%がPoC後に放棄され、AI-ready dataがないプロジェクトは2026年までに60%が放棄されると予測されています。
日本ではこの傾向がより顕著です。IPAの分析では、DX推進の成熟度がレベル0〜レベル2未満に偏り、全社戦略に基づく実施が少なく、「一部での散発的実施」にとどまる傾向が示されています。多くの開発者が「PoCは動いたのに、本番化に進めない」という壁に直面しているのではないでしょうか。
本記事では、開発者が実際に手を動かしてPoCを本番化に導くための、具体的で実現可能な手順を解説します。技術的な実装方法から、組織的な課題の解決まで、段階的に進められる実践的なガイドとしてまとめました。
動作環境と前提条件
本記事のコード例は、以下の環境で動作確認済みです。
- Pythonバージョン: Python 3.8以上
-
必要な標準ライブラリ:
logging,datetime,typing,enum,dataclasses,json,hashlib,statistics,traceback,time(すべてPython標準ライブラリ) - 外部依存: なし(コード例は標準ライブラリのみで動作します)
注意事項:
- 一部のコード例には「実際の実装に置き換える」というコメントがあります。これらは実際のAI API(OpenAI、Anthropic、Googleなど)を呼び出す実装に置き換える必要があります。
- ファイル操作を行うコード(監査ログなど)は、適切な書き込み権限が必要です。
- コード例は教育目的のため、エラーハンドリングを簡略化している場合があります。本番環境では、より詳細なエラーハンドリングとログ出力を実装してください。
PoCで終わる根本原因:開発者視点での分析
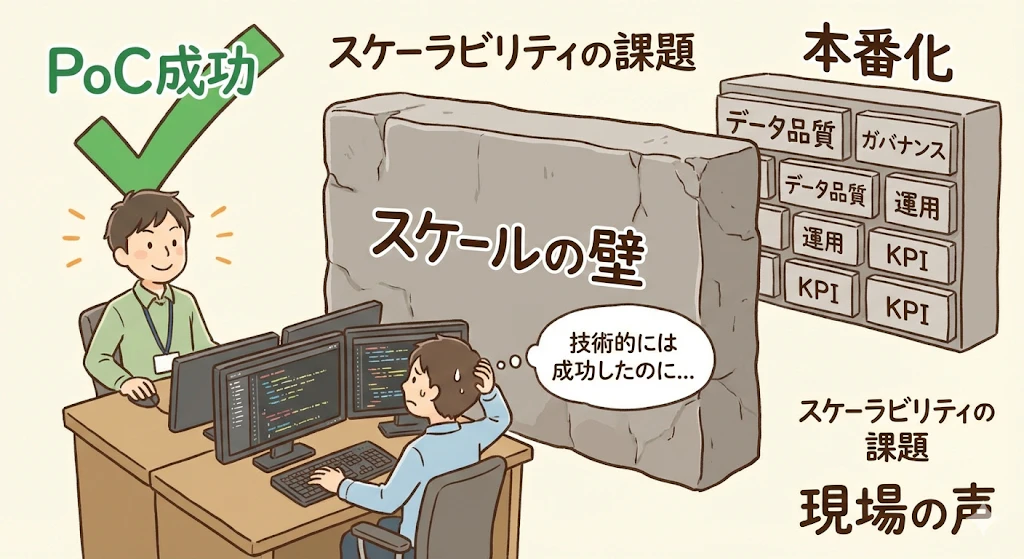
PoCが成功しやすい理由
PoCは通常、次の条件で実施されます。
- 対象部署やデータが限定されている
- 少数精鋭のチームで短期間に完結できる
- 例外処理や監査が軽い
- 「まず動けばOK」という緩い基準で評価される
このため、技術的には成功しても、本番環境では通用しないことが多々あります。
本番化で直面する現実
全社展開では、次のような制約が一気に増えます。
- データが汚い、分散している、権限が複雑
- 例外処理が大量に必要(部門差・顧客差・契約差)
- 誤回答が許されない(品質責任・説明責任)
- 監査・ログ・セキュリティが必須
- 継続的な運用と改善が必要
つまり、AIの賢さの問題ではなく、組織の運用能力(データ・統制・業務設計)の問題なのです。
実践ステップ1:PoC設計段階で本番化を見据える

価値仮説を明確にする
PoCを始める前に、次の3点を明確にしましょう。
- 誰のどんな困りごとを、どれだけ改善するのか
- どのKPIが何%改善すれば成功なのか
- 本番化の判断条件(Go/No-Go)
例えば、顧客サポートの問い合わせ対応を自動化する場合:
動作条件: このコードは標準ライブラリのみで動作します。Python 3.8以上が必要です。
# PoCの成功基準を定義する例
SUCCESS_CRITERIA = {
"response_time": {
"current": 30, # 現在の平均応答時間(分)
"target": 5, # 目標応答時間(分)
"improvement_rate": 83 # 改善率(%)
},
"first_contact_resolution": {
"current": 0.4, # 現在の一次解決率
"target": 0.7, # 目標一次解決率
"improvement_rate": 75 # 改善率(%)
},
"cost_per_ticket": {
"current": 500, # 現在の1件あたりコスト(円)
"target": 200, # 目標コスト(円)
"improvement_rate": 60 # 改善率(%)
}
}
# Go/No-Go判定関数
def evaluate_poc_success(actual_results):
"""PoC結果を評価し、本番化可否を判定する"""
go_criteria_met = True
for metric, criteria in SUCCESS_CRITERIA.items():
actual_value = actual_results.get(metric)
target_value = criteria["target"]
if metric in ["response_time", "cost_per_ticket"]:
# 時間・コストは低い方が良い
if actual_value > target_value:
go_criteria_met = False
print(f"❌ {metric}: {actual_value} > {target_value}")
else:
# 解決率などは高い方が良い
if actual_value < target_value:
go_criteria_met = False
print(f"❌ {metric}: {actual_value} < {target_value}")
return go_criteria_met
このコード例では、PoCの成功基準を数値化し、自動判定できるようにしています。これにより、「良かった気がする」ではなく、明確な判断基準に基づいて本番化を決定できます。
本番運用の要件をPoC段階から組み込む
PoC段階でも、最低限以下の要件を組み込みましょう。
セキュリティと監査ログ
動作条件:
- Python 3.8以上
- 標準ライブラリのみで動作(外部依存なし)
- ログファイルを書き込む権限が必要
-
audit_log.jsonlファイルが作成されます
import logging
from datetime import datetime
from typing import Dict, Any
import json
class AuditLogger:
"""監査ログを記録するクラス"""
def __init__(self, log_file_path: str):
self.logger = logging.getLogger('audit')
self.logger.setLevel(logging.INFO)
handler = logging.FileHandler(log_file_path)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
handler.setFormatter(formatter)
self.logger.addHandler(handler)
def log_ai_interaction(
self,
user_id: str,
prompt: str,
response: str,
model_used: str,
tokens_used: int,
response_time: float,
metadata: Dict[str, Any] = None
):
"""AIとの対話を監査ログに記録"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"user_id": user_id,
"prompt": prompt[:200], # プライバシー保護のため先頭200文字のみ
"response_length": len(response),
"model_used": model_used,
"tokens_used": tokens_used,
"response_time_seconds": response_time,
"metadata": metadata or {}
}
self.logger.info(json.dumps(log_entry, ensure_ascii=False))
# 機密情報の検出(簡易版)
sensitive_keywords = ["パスワード", "クレジットカード", "個人番号"]
if any(keyword in prompt for keyword in sensitive_keywords):
self.logger.warning(
f"⚠️ 機密情報の可能性がある入力を検出: user_id={user_id}"
)
# 使用例
audit_logger = AuditLogger("audit_log.jsonl")
def call_ai_with_audit(user_id: str, prompt: str, model: str):
"""監査ログ付きでAIを呼び出す"""
import time
start_time = time.time()
# AI呼び出し(実際の実装に置き換える)
response = "AIの応答" # 実際のAPI呼び出し
tokens_used = 100 # 実際のトークン数
response_time = time.time() - start_time
# 監査ログに記録
audit_logger.log_ai_interaction(
user_id=user_id,
prompt=prompt,
response=response,
model_used=model,
tokens_used=tokens_used,
response_time=response_time
)
return response
このコード例では、AIとの対話を監査ログに記録し、機密情報の検出も行っています。PoC段階からこの仕組みを組み込むことで、本番化時のセキュリティ審査をスムーズに通過できます。
例外処理とエラーハンドリング
動作条件:
- Python 3.8以上
- 標準ライブラリのみで動作(外部依存なし)
-
safe_ai_call()関数内のcall_ai_api()は実際のAI API呼び出しに置き換える必要があります
from enum import Enum
from typing import Optional, Dict, Any
import traceback
class ErrorType(Enum):
"""エラーの種類を定義"""
API_ERROR = "api_error"
TIMEOUT = "timeout"
RATE_LIMIT = "rate_limit"
INVALID_INPUT = "invalid_input"
DATA_QUALITY = "data_quality"
class AIErrorHandler:
"""AI呼び出しのエラーハンドリング"""
def __init__(self, fallback_response: str = "申し訳ございません。現在処理できません。"):
self.fallback_response = fallback_response
self.error_log = []
def handle_error(
self,
error: Exception,
error_type: ErrorType,
context: Dict[str, Any]
) -> str:
"""エラーを処理し、適切な応答を返す"""
error_info = {
"type": error_type.value,
"message": str(error),
"context": context,
"traceback": traceback.format_exc()
}
self.error_log.append(error_info)
# エラータイプに応じた処理
if error_type == ErrorType.RATE_LIMIT:
return "現在アクセスが集中しています。しばらくお待ちください。"
elif error_type == ErrorType.TIMEOUT:
return "処理に時間がかかっています。もう一度お試しください。"
elif error_type == ErrorType.INVALID_INPUT:
return "入力内容を確認してください。"
else:
return self.fallback_response
def get_error_statistics(self) -> Dict[str, int]:
"""エラー統計を取得"""
error_counts = {}
for error in self.error_log:
error_type = error["type"]
error_counts[error_type] = error_counts.get(error_type, 0) + 1
return error_counts
# カスタム例外クラスの定義
class RateLimitError(Exception):
"""レート制限エラー"""
pass
# 使用例
error_handler = AIErrorHandler()
def safe_ai_call(prompt: str):
"""安全なAI呼び出し(エラーハンドリング付き)"""
try:
# 実際のAI呼び出し(実際の実装に置き換える)
# 例: response = openai.ChatCompletion.create(...)
response = "AIの応答" # プレースホルダー
return response
except RateLimitError as e:
return error_handler.handle_error(
e, ErrorType.RATE_LIMIT, {"prompt": prompt[:100]}
)
except TimeoutError as e:
return error_handler.handle_error(
e, ErrorType.TIMEOUT, {"prompt": prompt[:100]}
)
except Exception as e:
return error_handler.handle_error(
e, ErrorType.API_ERROR, {"prompt": prompt[:100]}
)
このコード例では、様々なエラーパターンに対応し、ユーザーに適切なメッセージを返す仕組みを実装しています。本番環境では予期しないエラーが発生するため、PoC段階からこのような例外処理を組み込むことが重要です。
実践ステップ2:AI-ready dataを整備する

データ品質の重要性
Gartnerは「AI-ready dataがないAIプロジェクトは、2026年までに60%放棄される」と警告しています。データの整備は、技術的な実装以上に重要です。
データ整備のチェックリスト
動作条件:
- Python 3.8以上(
dataclassesを使用) - 標準ライブラリのみで動作(外部依存なし)
- サンプルデータは実際のデータに置き換えて使用してください
from typing import List, Dict, Any
from dataclasses import dataclass
from datetime import datetime
@dataclass
class DataQualityCheck:
"""データ品質チェックの結果"""
field_name: str
completeness: float # 完全性(0.0-1.0)
consistency: float # 一貫性(0.0-1.0)
accuracy: float # 正確性(0.0-1.0)
issues: List[str] # 発見された問題
class DataQualityValidator:
"""データ品質を検証するクラス"""
def __init__(self):
self.checks: List[DataQualityCheck] = []
def validate_data_source(
self,
data: List[Dict[str, Any]],
required_fields: List[str],
reference_data: Dict[str, Any] = None
) -> DataQualityCheck:
"""データソースの品質を検証"""
issues = []
# 必須フィールドの存在確認
missing_fields = []
for field in required_fields:
if not any(field in record for record in data):
missing_fields.append(field)
if missing_fields:
issues.append(f"必須フィールドが不足: {missing_fields}")
# 完全性チェック
total_records = len(data)
complete_records = sum(
1 for record in data
if all(field in record and record[field] for field in required_fields)
)
completeness = complete_records / total_records if total_records > 0 else 0.0
if completeness < 0.8:
issues.append(f"完全性が低い: {completeness:.2%}")
# 一貫性チェック(参照データがある場合)
consistency = 1.0
if reference_data:
# 用語の統一性をチェック
inconsistent_terms = []
for record in data[:10]: # サンプルチェック
for field in required_fields:
if field in record and field in reference_data:
if record[field] != reference_data[field]:
inconsistent_terms.append(f"{field}: {record[field]}")
if inconsistent_terms:
consistency = 0.5
issues.append(f"一貫性の問題: {len(inconsistent_terms)}件")
check_result = DataQualityCheck(
field_name="data_source",
completeness=completeness,
consistency=consistency,
accuracy=1.0, # 実際の実装では、より詳細な検証が必要
issues=issues
)
self.checks.append(check_result)
return check_result
def generate_report(self) -> str:
"""データ品質レポートを生成"""
report = ["=== データ品質レポート ===\n"]
for check in self.checks:
report.append(f"フィールド: {check.field_name}")
report.append(f" 完全性: {check.completeness:.2%}")
report.append(f" 一貫性: {check.consistency:.2%}")
report.append(f" 正確性: {check.accuracy:.2%}")
if check.issues:
report.append(" 問題:")
for issue in check.issues:
report.append(f" - {issue}")
report.append("")
return "\n".join(report)
# 使用例
validator = DataQualityValidator()
# サンプルデータ(実際の個人情報は使用しない)
sample_data = [
{"id": "001", "name": "サンプル顧客A", "email": "sample_a@example.com"},
{"id": "002", "name": "サンプル顧客B", "email": ""}, # 不完全なデータ
{"id": "003", "name": "サンプル顧客C", "email": "sample_c@example.com"},
]
required_fields = ["id", "name", "email"]
check_result = validator.validate_data_source(sample_data, required_fields)
print(validator.generate_report())
このコード例では、データの品質を自動的に検証し、問題を特定する仕組みを実装しています。PoC段階でこのような検証を組み込むことで、本番環境でのデータ品質問題を事前に発見できます。
RAG用の文書整備
RAG(Retrieval-Augmented Generation)を活用する場合、参照文書の整備が重要です。
動作条件:
- Python 3.8以上
- 標準ライブラリのみで動作(外部依存なし)
- メモリ内で文書を管理します(本番環境ではデータベースやベクトルDBへの統合を推奨)
from typing import List, Dict
import hashlib
from datetime import datetime
class DocumentManager:
"""RAG用の文書管理クラス"""
def __init__(self):
self.documents: Dict[str, Dict] = {}
self.metadata_index: Dict[str, List[str]] = {}
def register_document(
self,
content: str,
title: str,
category: str,
last_updated: datetime,
owner: str,
tags: List[str] = None
) -> str:
"""文書を登録し、IDを返す"""
# 文書IDを生成(内容のハッシュ)
doc_id = hashlib.md5(content.encode()).hexdigest()
document = {
"id": doc_id,
"content": content,
"title": title,
"category": category,
"last_updated": last_updated.isoformat(),
"owner": owner,
"tags": tags or [],
"registered_at": datetime.now().isoformat()
}
self.documents[doc_id] = document
# メタデータインデックスを更新
for tag in tags or []:
if tag not in self.metadata_index:
self.metadata_index[tag] = []
self.metadata_index[tag].append(doc_id)
return doc_id
def find_outdated_documents(self, threshold_days: int = 365) -> List[str]:
"""古い文書を特定"""
outdated = []
threshold_date = datetime.now().timestamp() - (threshold_days * 24 * 60 * 60)
for doc_id, doc in self.documents.items():
last_updated = datetime.fromisoformat(doc["last_updated"]).timestamp()
if last_updated < threshold_date:
outdated.append(doc_id)
return outdated
def get_documents_by_category(self, category: str) -> List[Dict]:
"""カテゴリで文書を検索"""
return [
doc for doc in self.documents.values()
if doc["category"] == category
]
def validate_document_quality(self, doc_id: str) -> Dict[str, Any]:
"""文書の品質を検証"""
if doc_id not in self.documents:
return {"error": "文書が見つかりません"}
doc = self.documents[doc_id]
issues = []
# 内容の長さチェック
if len(doc["content"]) < 100:
issues.append("内容が短すぎます(100文字未満)")
# タイトルの存在確認
if not doc["title"]:
issues.append("タイトルが設定されていません")
# タグの存在確認
if not doc["tags"]:
issues.append("タグが設定されていません")
return {
"doc_id": doc_id,
"has_issues": len(issues) > 0,
"issues": issues
}
# 使用例
doc_manager = DocumentManager()
# 文書を登録
doc_id = doc_manager.register_document(
content="これはサンプル文書です。RAGシステムで参照されます。",
title="サンプル文書",
category="FAQ",
last_updated=datetime.now(),
owner="admin",
tags=["FAQ", "サポート"]
)
# 古い文書を特定
outdated = doc_manager.find_outdated_documents(threshold_days=180)
print(f"古い文書: {len(outdated)}件")
# 品質検証
quality_check = doc_manager.validate_document_quality(doc_id)
print(quality_check)
このコード例では、RAG用の文書を管理し、品質を検証する仕組みを実装しています。古い文書の特定や、カテゴリ別の検索も可能です。
実践ステップ3:業務プロセスに埋め込む

チャットツール止まりにしない
PoCでの典型は「チャットで便利」ですが、全社展開では定着しません。既存の業務ツールに統合することが重要です。
業務フロー統合の例
動作条件:
- Python 3.8以上
- 標準ライブラリのみで動作(外部依存なし)
-
_generate_ai_content()メソッドは実際のAI API呼び出しに置き換える必要があります - メモリ内でワークフローを管理します(本番環境ではデータベースへの永続化を推奨)
from typing import Optional, Dict, Any
from enum import Enum
from datetime import datetime
class WorkflowStage(Enum):
"""ワークフローのステージ"""
DRAFT = "draft"
REVIEW = "review"
APPROVED = "approved"
REJECTED = "rejected"
class BusinessWorkflowIntegration:
"""業務フローへの統合クラス"""
def __init__(self):
self.workflows: Dict[str, Dict] = {}
def create_ai_assisted_workflow(
self,
workflow_id: str,
initial_prompt: str,
human_review_required: bool = True
) -> Dict[str, Any]:
"""AI支援ワークフローを作成"""
workflow = {
"id": workflow_id,
"current_stage": WorkflowStage.DRAFT.value,
"ai_generated_content": None,
"human_reviewed": False,
"human_review_required": human_review_required,
"created_at": datetime.now().isoformat(),
"history": []
}
# AIで初期コンテンツを生成
ai_content = self._generate_ai_content(initial_prompt)
workflow["ai_generated_content"] = ai_content
workflow["history"].append({
"stage": WorkflowStage.DRAFT.value,
"action": "ai_generated",
"timestamp": datetime.now().isoformat()
})
# 人間のレビューが必要な場合
if human_review_required:
workflow["current_stage"] = WorkflowStage.REVIEW.value
self.workflows[workflow_id] = workflow
return workflow
def human_review(
self,
workflow_id: str,
approved: bool,
feedback: Optional[str] = None
) -> Dict[str, Any]:
"""人間によるレビュー"""
if workflow_id not in self.workflows:
return {"error": "ワークフローが見つかりません"}
workflow = self.workflows[workflow_id]
if workflow["current_stage"] != WorkflowStage.REVIEW.value:
return {"error": "レビューステージではありません"}
workflow["human_reviewed"] = True
workflow["review_feedback"] = feedback
if approved:
workflow["current_stage"] = WorkflowStage.APPROVED.value
else:
workflow["current_stage"] = WorkflowStage.REJECTED.value
workflow["history"].append({
"stage": workflow["current_stage"],
"action": "human_reviewed",
"approved": approved,
"feedback": feedback,
"timestamp": datetime.now().isoformat()
})
return workflow
def _generate_ai_content(self, prompt: str) -> str:
"""AIコンテンツを生成(実際の実装に置き換える)"""
# 実際のAI API呼び出し
return f"AI生成コンテンツ: {prompt}"
def get_workflow_status(self, workflow_id: str) -> Optional[Dict[str, Any]]:
"""ワークフローの状態を取得"""
return self.workflows.get(workflow_id)
# 使用例:営業提案書の作成ワークフロー
workflow_manager = BusinessWorkflowIntegration()
# AIで提案書ドラフトを作成
workflow = workflow_manager.create_ai_assisted_workflow(
workflow_id="proposal_001",
initial_prompt="顧客A向けの新規提案書を作成してください",
human_review_required=True
)
print(f"ワークフロー作成: {workflow['id']}")
print(f"現在のステージ: {workflow['current_stage']}")
# 人間がレビュー
reviewed = workflow_manager.human_review(
workflow_id="proposal_001",
approved=True,
feedback="価格設定を確認済み"
)
print(f"レビュー後ステージ: {reviewed['current_stage']}")
このコード例では、AI生成コンテンツに人間のレビューを組み込むワークフローを実装しています。これにより、AIの出力をそのまま使うのではなく、業務プロセスに統合できます。
実践ステップ4:KPIを測定し、継続的に改善する
KPIの自動測定
PoC開始前にKPIを固定し、自動測定できるようにしましょう。
動作条件:
- Python 3.8以上(
dataclassesを使用) - 標準ライブラリのみで動作(外部依存なし)
- メモリ内でメトリクスを管理します(本番環境では時系列データベースへの統合を推奨)
from dataclasses import dataclass, field
from typing import List, Dict
from datetime import datetime, timedelta
import statistics
@dataclass
class KPIMetric:
"""KPIメトリクス"""
name: str
value: float
target: float
unit: str
timestamp: datetime = field(default_factory=datetime.now)
class KPITracker:
"""KPIを追跡するクラス"""
def __init__(self):
self.metrics: List[KPIMetric] = []
def record_metric(
self,
name: str,
value: float,
target: float,
unit: str = ""
):
"""メトリクスを記録"""
metric = KPIMetric(
name=name,
value=value,
target=target,
unit=unit
)
self.metrics.append(metric)
def calculate_improvement_rate(self, metric_name: str) -> float:
"""改善率を計算"""
relevant_metrics = [
m for m in self.metrics
if m.name == metric_name
]
if len(relevant_metrics) < 2:
return 0.0
# 最初と最後の値を比較
first_value = relevant_metrics[0].value
last_value = relevant_metrics[-1].value
target = relevant_metrics[0].target
if first_value == 0:
return 0.0
# 改善率を計算(目標に向かってどれだけ改善したか)
improvement = ((target - first_value) - (target - last_value)) / abs(target - first_value) * 100
return improvement
def generate_kpi_report(
self,
start_date: datetime = None,
end_date: datetime = None
) -> Dict[str, Any]:
"""KPIレポートを生成"""
if start_date is None:
start_date = datetime.now() - timedelta(days=30)
if end_date is None:
end_date = datetime.now()
filtered_metrics = [
m for m in self.metrics
if start_date <= m.timestamp <= end_date
]
# メトリクスごとに集計
metric_groups: Dict[str, List[KPIMetric]] = {}
for metric in filtered_metrics:
if metric.name not in metric_groups:
metric_groups[metric.name] = []
metric_groups[metric.name].append(metric)
report = {
"period": {
"start": start_date.isoformat(),
"end": end_date.isoformat()
},
"metrics": {}
}
for metric_name, metrics_list in metric_groups.items():
values = [m.value for m in metrics_list]
target = metrics_list[0].target
unit = metrics_list[0].unit
report["metrics"][metric_name] = {
"average": statistics.mean(values),
"min": min(values),
"max": max(values),
"target": target,
"unit": unit,
"achievement_rate": (statistics.mean(values) / target * 100) if target > 0 else 0,
"improvement_rate": self.calculate_improvement_rate(metric_name)
}
return report
# 使用例
kpi_tracker = KPITracker()
# メトリクスを記録
kpi_tracker.record_metric("response_time", 25, 5, "分")
kpi_tracker.record_metric("response_time", 20, 5, "分")
kpi_tracker.record_metric("response_time", 10, 5, "分")
kpi_tracker.record_metric("response_time", 6, 5, "分")
kpi_tracker.record_metric("first_contact_resolution", 0.4, 0.7)
kpi_tracker.record_metric("first_contact_resolution", 0.5, 0.7)
kpi_tracker.record_metric("first_contact_resolution", 0.6, 0.7)
kpi_tracker.record_metric("first_contact_resolution", 0.65, 0.7)
# レポートを生成
report = kpi_tracker.generate_kpi_report()
print("=== KPIレポート ===")
for metric_name, data in report["metrics"].items():
print(f"\n{metric_name}:")
print(f" 平均値: {data['average']:.2f} {data['unit']}")
print(f" 目標値: {data['target']} {data['unit']}")
print(f" 達成率: {data['achievement_rate']:.1f}%")
print(f" 改善率: {data['improvement_rate']:.1f}%")
このコード例では、KPIを自動的に追跡し、改善率を計算する仕組みを実装しています。これにより、PoCの成果を定量的に評価できます。
実践ステップ5:90日ロードマップで段階的に進める

フェーズ0(0〜2週):スコープ固定
1つの業務に絞り、全社展開の候補になりやすい業務を選びます。
推奨業務の特徴
- 横断的(複数部門で利用)
- 反復的(定期的に発生)
- 定型的(ルールが明確)
フェーズ1(2〜6週):ガバナンスとデータ整備
最小単位でガバナンスとデータを整備します。
動作条件:
- Python 3.8以上
- 標準ライブラリのみで動作(外部依存なし)
- チェックリストはメモリ内で管理されます(本番環境ではデータベースや設定ファイルへの永続化を推奨)
from typing import Dict
class Phase1Checklist:
"""フェーズ1のチェックリスト"""
def __init__(self):
self.items = {
"governance": {
"用途別ポリシー": False,
"入力禁止情報ルール": False,
"監査ログ設計": False,
"誤回答時の是正フロー": False
},
"data": {
"一次情報の特定": False,
"用語の統一": False,
"権限設計": False,
"RAG用文書整備": False
}
}
def check_completion(self) -> Dict[str, float]:
"""完了率を計算"""
completion_rates = {}
for category, items in self.items.items():
completed = sum(1 for v in items.values() if v)
total = len(items)
completion_rates[category] = completed / total * 100
return completion_rates
def mark_complete(self, category: str, item: str):
"""項目を完了としてマーク"""
if category in self.items and item in self.items[category]:
self.items[category][item] = True
# 使用例
checklist = Phase1Checklist()
# 進捗を記録
checklist.mark_complete("governance", "用途別ポリシー")
checklist.mark_complete("governance", "監査ログ設計")
checklist.mark_complete("data", "一次情報の特定")
# 完了率を確認
completion = checklist.check_completion()
print(f"ガバナンス完了率: {completion['governance']:.1f}%")
print(f"データ整備完了率: {completion['data']:.1f}%")
フェーズ2(6〜12週):業務に埋め込んで運用
既存ツールに導線を作り、Human-in-the-loopを組み込みます。
フェーズ3(12〜24週):横展開
テンプレ化し、共通部品化して横展開します。
まとめ:PoCは技術の試運転、本番化は組織の実力試験
ダボス会議2026で示されたように、生成AIは実用化フェーズに入りました。しかし、日本では多くのPoCが本番化に至っていません。その原因は、AIの技術力ではなく、組織の運用能力(データ・統制・業務設計)にあることが明らかになりました。
本記事で紹介した実践的な手順を実行することで、PoCを本番化に導くことができます。重要なのは、PoC設計段階から本番化を見据え、以下の4点を先に整えることです。
- AI-ready data(使えるデータ)を先に整える
- ガバナンス(責任・権限・監査)を先に設計する
- 業務プロセスに埋め込む(チャットツール止まりにしない)
- KPI設計(便利で終わらせない)
これらの実装を段階的に進めることで、PoCで終わらず、本番環境で価値を生み出す生成AIシステムを構築できます。
作成日:2026-01-26
参考リンク
- Gartner: 生成AIプロジェクトの30%がPoC後に放棄される予測(2024-07-29)
https://www.gartner.com/en/newsroom/press-releases/2024-07-29-gartner-predicts-30-percent-of-generative-ai-projects-will-be-abandoned-after-proof-of-concept-by-end-of-2025 - Gartner: AI-ready data不足で2026年までに60%放棄(2025-02-26)
https://www.gartner.com/en/newsroom/press-releases/2025-02-26-lack-of-ai-ready-data-puts-ai-projects-at-risk - IPA: DX推進指標 自己診断結果の分析(2024年版)
https://www.ipa.go.jp/pressrelease/2025/press20250507.html - IPA: DX推進指標とそのガイダンス
https://www.ipa.go.jp/digital/dx-suishin/ug65p90000001j8i-att/dx-suishin-guidance.pdf