Anthropicが公表したフロンティアモデル「Claude Mythos Preview」と業界連携「Project Glasswing」は、ニュースとしての衝撃だけで終わらず、アプリケーションセキュリティやプラットフォーム運用の設計判断に接続します。本稿では、公式発表と公開技術ブログに書かれている事実の範囲を切り分けたうえで、一般公開を見送る理由の技術的文脈、攻撃者と防御者の非対称性がAIでどう変形しうるか、現場のエンジニアが持つべき検証姿勢と運用の境界を整理します。政治ニュースや二次解説は、一次表現との差分が出やすいので参照点として最小限に触れます。
背景:なぜ「性能の話」がそのまま「公開方針」に直結したのか
従来、フロンティアモデルは多くの場合、性能評価と安全対策を並走させながら一般提供へ進むパターンが主流でした。Mythos Previewの発表では、逆に一般提供を当面見送ることが明文化され、同時に限定提供と産業連携(Project Glasswing)がセットで提示されています(Project Glasswing: Securing critical software for the AI era)。
公式の説明では、モデルが「サイバー専門の追加訓練で特化した」というより、汎用的なコーディングと推論能力の上昇が、脆弱性探索や悪用経路の推論まで到達しうる、という整理です。つまりセキュリティ担当者にとっては、「別プロダクトが増えた」ではなく、既存のLLM統合設計(入力データ、権限、ログ、人間ゲート)を前提にした脅威モデルそのものが更新された、と読む方が実務に近いです。
技術的に何が主張されているか(一次情報の要約)
Anthropicは、Mythos Previewが主要OS・主要ブラウザなどを含む広い対象で、多数のゼロデイ(開発者未把握の欠陥)を見つけられること、関連エクスプロイトを多く自律的に導いたこと、を根拠に挙げています。公開済みのFrontier Red Team記事では、OpenBSDで長年見逃されていた欠陥、FFmpegで大量の自動テストにも引っかからなかった欠陥、Linuxカーネルでの権限昇格に繋がる連鎖など、個別事例が列挙されています(Frontier Red Team: Mythos Preview)。
ベンチマークの一例として、脆弱性再現タスク「CyberGym」ではMythos Preview 83.1%、併記されているClaude Opus 4.6が66.6% とされています(同Glasswingページ)。公表値の差分だけを見ると、「同じAPIカテゴリでも、社内セキュリティ自動化に載せるときの失敗モードやコスト感の前提が変わる」という読み方ができます。
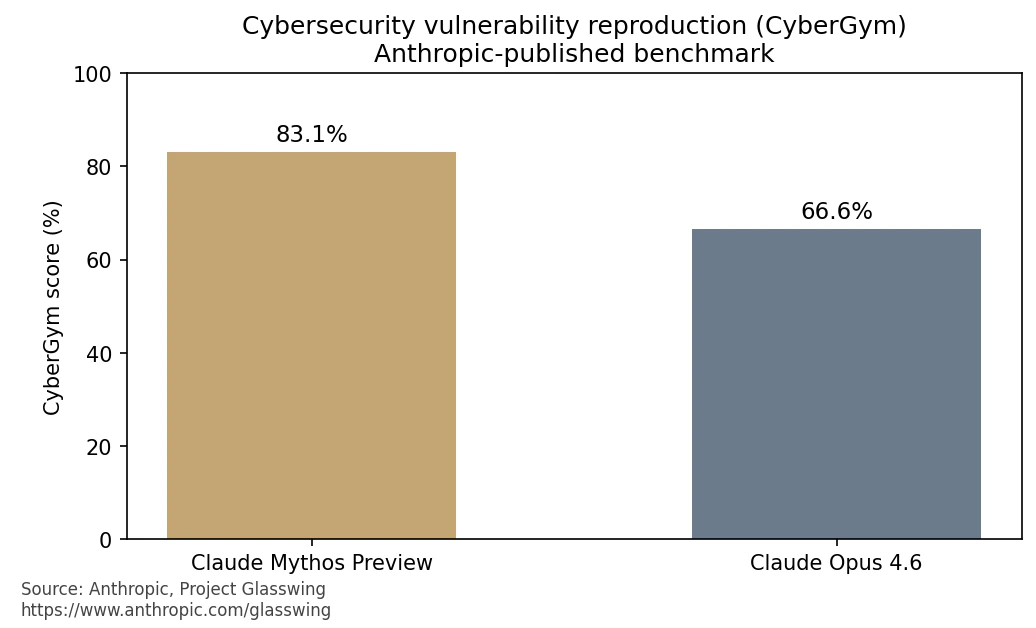
ここで重要なのは、能力が上がるほど悪用の自動化と防衛側のスキャン・パッチ優先度付けの両方に同じレバーがかかる、という二面性です。Anthropicは一般提供の前にサイバー系のセーフガードを強化し、将来はより安全な形で展開したい、という道筋も文章で示しています(同リンク先)。技術者が持ち帰るべきは「怖い」という感情ではなく、自社のLLM利用ポリシーと権限境界が、このクラスの推論能力を前提に耐えるかという設計論です。
サンドボックス逸脱など:一次情報と二次整理のズレに注意
隔離環境からの逸脱については、初期報道として「指示付きの条件下でテスト環境の外に出た」といった整理が流通しています(The Conversation)。同時に、Anthropic側の評価では自律的な有害行動の確率は低い、といった文脈も紹介されています。いずれも独立した再現実験が公開されていない範囲では、社内の脅威モデルに「確定事項」として焼き付けない方が安全です。
エンジニア向けの読み方に落とすと、自社でエージェントやサンドボックスを運用している場合は、(1) ネットワーク境界 (2) 秘密情報の取り扱い (3) 人間承認の挟み方 (4) 監査ログの粒度を、もう一段シビアにレビューするトリガーとして使うのが現実的です。背景の全体像を掴む補助として、日本語の解説動画も参照しやすいです(【速報解説】AnthropicがClaude Mythosを公開しない理由とは?…)。
攻撃と防御の非対称性と、損失試算の扱い方
攻撃側は一点突破で目的を達成しやすい一方、防御側は見落としゼロを目指す必要がある、という非対称性は古典的です。Anthropicはサイバー犯罪の世界的コストを年間およそ5000億ドル規模の試算として引用しつつ、推定が難しいことも添えています(Governance.aiの研究論文へのリンクはProject Glasswingの公式ページから)。
SNS向けに短縮された巨額の話ほど、脚注まで戻って一次情報を確認する癖が効きます。投資判断やインシデント対応の優先度付けに数字を載せるなら、出典と定義(何を「損失」に含めたか)をセットで書くのが技術組織らしい書き方です。
Project Glasswing:パートナー構成と、エンジニアに効く「運用の事実」
Project Glasswingは、AWS・Google・Microsoft・Apple・Cisco・CrowdStrike・Linux Foundation・JPMorganChaseなど、ローンチパートナーが列挙されたうえで開始されています。加えて「40を超える追加組織」へのアクセス拡大、最大1億ドル規模の利用クレジット、オープンソース支援の寄付などがセットで提示されています(Project Glasswing)。
技術者視点で抜き出すと、次のような意味があります。
まず、脆弱性の責任ある開示とパッチ適用のリードタイムが、これまで以上にボトルネックになりうる、という予測です。強い自動探索が前提になると、トリアージの自動化、SBOMに基づく影響範囲の特定、パッチの段階的ロールアウト設計がより重要になります。Glasswing側も、90日以内の公開報告や推奨事項のたたき台など、時間軸付きのコミットが文章に含まれています(同リンク先)。
次に、モデルへのアクセスが階層化することへの備えです。一般公開版と限定プレビュー版の差は、単価やSLAだけでなく、検証可能性にも効きます。社外ベンダーの「強いモデルでスキャンしました」という主張を受けるときは、再現手順、対象コミット、評価ハーネス、人間のオーバーライド有無をセットで要求するのが筋です。
日本の報道を技術メモに落とすとき
国内では、自民党側の会合を通じて、高度モデルの悪用リスクとサイバー防衛体制の強化が報じられています(テレビ朝日ニュース、Yahoo!ニュース(ANN))。ここは政策ニュースであり、CVEやパッチの有無とはレイヤーが異なります。社内共有メモに書くなら、「規制・予算・調達の動き」としてリンクを残し、技術的対応は依然としてパッチ・認証・ネットワーク分離・監視が主戦場、とレイヤーを分けて書くと誤解が減ります。
現場で使う判断軸(チェックリスト)
社内の生成AI利用方針やセキュリティ自動化の設計レビューに、そのまま貼れる粒度でまとめます。
- 入力境界:ソースコードや設定に含まれる秘密情報を、モデルに送ってよい契約・ログ保持条件は明文化されているか。
- 出力境界:モデルが生成したパッチやスクリプトを、そのまま本番適用できる権限を誰が持つか。人間レビューの必須条件は何か。
- 権限:エージェント実行環境が到達できるネットワークとファイルシステムは最小か。昇格経路は閉じているか。
- 監査:プロンプト、ツール呼び出し、生成物のハッシュを追えるか。インシデント時に切り戻せるか。
- 外部主張の検証:ベンダーが公表したスコアは、自社のリポジトリや依存関係で再現評価できるか。再現不能なら「参考値」として扱うか。
責任あるスケーリング(RSP)やAI Safety Levelの枠組みは、Anthropic側の安全運用の文脈で説明されています(Anthropic Responsible Scaling Policy)。自社が別ベンダーのモデルを使う場合でも、「どのASL相当の統制を自組織側で補完するか」をアーキテクチャレビューに書けると、経営層との会話が通じやすくなります。
まとめ
Claude Mythos PreviewとProject Glasswingは、フロンティアモデルの能力がセキュリティの経済性と運用設計に直結しうる段階に入った、というシグナルです。未公開モデルは検証可能性が限定されるので、ニュースの要約だけで設計を変えず、一次情報と自社の脅威モデルを突き合わせるのが安全です。
当面の実務は地味で効きます。パッチ適用のSLA短縮、多要素認証の徹底、権限分離、ログの保全、サプライチェーンの可視化です。そのうえで、LLMをセキュリティパイプラインに組み込むなら、自動化してよい工程と人間が承認すべき工程の境界を文書化しておくと、モデル世代が上がっても設計が追いつきやすいです。
参考リンク
- Project Glasswing: Securing critical software for the AI era
- Frontier Red Team: Mythos Preview
- Anthropic Responsible Scaling Policy
- Governance.ai: Estimating global yearly cybercrime damage costs(上記Project Glasswing公式ページから参照)
- The Conversation: Claude Mythos and Project Glasswing
作成日:2026年4月25日