はじめに
Crashlyticsにクラッシュのアラートが届いたときに、AIエージェント(Claude Code Actions)が自動で原因を調査し、GitHubのIssueに結果をまとめ、必要に応じて修正のドラフトPRまで作成する仕組みを運用しています。
この仕組みを作った経緯や、DevinからClaude Code Actionsへ移行できるかを検証した話はそれぞれ以下にまとめました。本記事はその続きになります。
DevinからClaude Code Actionsに移行してからしばらく運用を続け、各調査のトークン消費などを記録してきたので、今回はその集計結果などを備忘も兼ねてまとめておきたいと思います。
なお、この仕組みはあくまで一次トリアージの自動化であり、エンジニアを不要にするものではありません。要対応と判定されるケースもありますし、最終的な対応の判断は人間が行っています。
システム全体像
移行後の構成は次のようになっています。
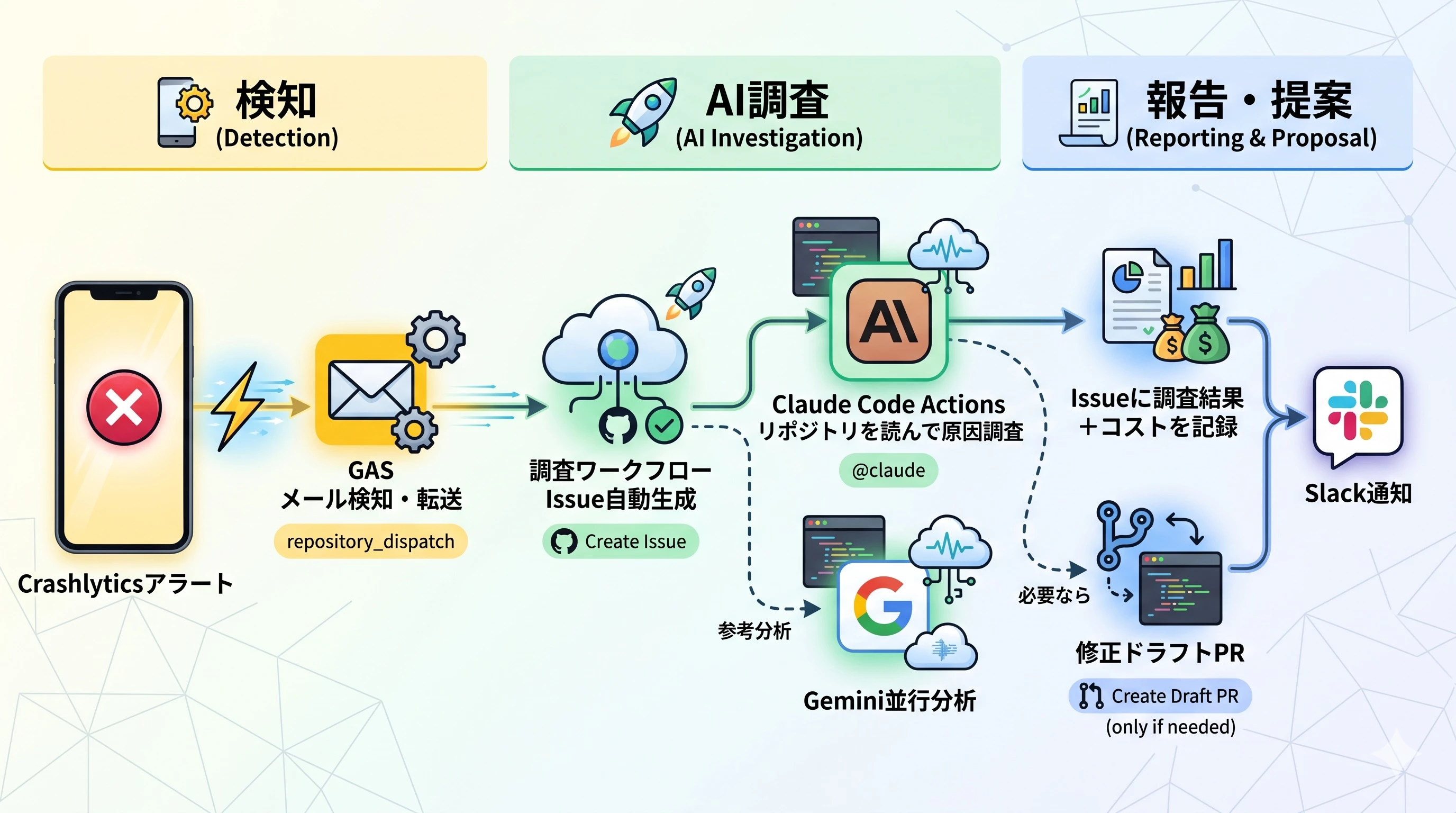
おおまかな流れは、アラート受信 → GASがメールを検知してGitHub Actionsを起動 → Claude Code Actionsがリポジトリを読んで調査 → Issueに結果を報告 → Slackに通知、という形で、これを無人で回しています。あわせて、各調査のトークン消費とコストをIssueに自動で記録するようにしました。この記録があるおかげで、後から運用実績を定量的に振り返ることができています。
図中の「Gemini並行分析」は、Claudeの調査と並行して別モデルの参考意見も得るための補助的な位置づけで、正式な判定にはClaudeの結果を用いています。
なお、AIにリポジトリをcloneさせる際の権限やシークレットの扱いは、前記事で触れています。
集計条件
本記事の数値は、100を超えるテナントアプリを横断して運用しているなかで蓄積した調査ログを集計したものです。対象はAndroid・iOSの両方を含み、Claude Code Actionsによる一次調査が完了したIssueを用いています。コストは約50回分の調査について、Issueに自動記録したトークン使用量から算出しました。リードタイムはワークフローの実行時間(AIが実際に調査に費やした時間)で、通知の遅延や人間の確認待ちは含めていません。
コストの実績
1回の調査にかかるコストは、おおよそ3〜4ドルという結果でした。内訳は次のとおりです。
| 指標 | 値 |
|---|---|
| 1回あたり(中央値) | 約3.4ドル |
| ばらつき(最小〜最大) | 0.8〜7.3ドル |
| プラットフォーム差 | ほぼなし(Android・iOSとも約3ドル強) |
なお、ここでのコストはClaude Code GitHub Actionsのトークン使用量をAPI料金に換算したもので、GitHub Actionsのランナー費用やGoogle Apps Script(GAS)、Geminiの参考分析分は含めていません。
この値は2026年6月時点のもので、モデルはclaude-opus-4-8[1m]を使用しています(集計には以前指定していたclaude-opus-4-7[1m]も含まれます。なお、モデル名はワークフロー上の指定名をそのまま記載しています)。運用状況やモデルの価格で変動するので、絶対額そのものよりも傾向として捉えるようにしています。
興味深かったのは、コストが調査の深さに応じて増える傾向があった点です。AIが何ターン、リポジトリのcloneやgrep、ファイルの読み込みといったツールを叩いて掘り下げたかが、コストに反映されているようでした。既知の結論を素早く再確認するだけなら数ターンで1ドル強に収まりますが、新しいOSや共通基盤の深くまで原因を追う調査では数十ターンを要し、4〜7ドルに達することもありました。
費用対効果という観点では、これまで人手で1〜2営業日、休日を挟めば数日かかっていた初動の原因切り分けが、無人で数ドル・数分に置き換わったかたちになります。
リードタイムの実績
一次調査、つまり原因の切り分けと緊急度の判定が終わるまでの所要時間は、次のとおりでした。
| 指標 | 値 |
|---|---|
| 一次調査・中央値 | 約7分 |
| 一次調査・9割(p90) | 12分以内 |
| 一次調査・最長 | 約18分 |
| 1時間後の再評価(追加調査)・中央値 | 約3分 |
表中の「1時間後の再評価」は、要対応と判定したクラッシュが本当に継続しているかを1時間後にもう一度確認する仕組みになっています。
人手の場合は、確認待ちも含めた初動が休日を挟むと数日後になることもありましたが、無人での一次調査は数分で終わります。この差が運用上もっとも効いていると感じています。
トークン消費の内訳
1回の調査でのトークン消費は、おおよそ次の規模でした。
| 項目 | 1回あたりの規模 | 備考 |
|---|---|---|
| 新規Input(非キャッシュ) | 数十〜数Kトークン | ほぼキャッシュにヒット |
| キャッシュ書き込み | 数十〜数百Kトークン | - |
| キャッシュ読み出し | 数Mトークン | トークン量が最大 |
| Output | 20〜40Kトークン | - |
新規Inputが極端に小さいのは、1回の調査が数十ターンに及ぶあいだ、システムプロンプトや調査指示・クラッシュ情報・読み込んだソースコードといった共通のコンテキストが、各ターンでプロンプトキャッシュにヒットして再利用されるためです。毎ターン新規として課金される入力はほとんど発生しません。エージェント的に多ターンで深掘りしても入力コストが膨らみにくいのは、プロンプトキャッシュがよく効いているからだと感じています。
したがって、コストの主役はOutput生成と、ターンを重ねるごとに積み上がるキャッシュの読み書きになります。トークン消費としては、リポジトリをcloneする、関連コードを読む、スタックトレースと突き合わせる、報告を書く、という一連のエージェント探索です。
調査ログから見えた探索プロセス
AIの探索プロセスを確認するため、全ターンのツール呼び出しと、そのターンで出力された推論・判断理由を記録するようにしています。その記録を確認したところ、どの調査もおおむね次の流れをたどっていました。
クラッシュ情報とスタックトレース、自動収集した緊急度データを受け取り、スタックトレースからアプリ側か共通基盤(コア)側かカスタマイズ(テナント)側かを判断してリポジトリをcloneします。該当ファイルを特定して読み込み、スタックトレースと実コードを突き合わせて原因を推論し、バージョンや関連コードで裏取りをします。最後に緊急度と確信度を判定して報告し、確信度が高く具体的な修正がある場合に限って修正のドラフトPRを作成する、という型です。
ケース1: 巨大画像によるクラッシュ
あるAndroidアプリで、Canvas: trying to draw too large bitmap(約150MB)というFATALクラッシュが発生していました。ログを要約すると、AIは次のように動いていました。
対象リポジトリをcloneし、発生バージョンのtagをcheckout
画像表示まわりのコンポーネントを読み込み
→ 画像ライブラリ経由で、デコードサイズの上限指定が無いまま
ほぼ原寸の巨大画像を描画しようとしていると判断
呼び出し側のレイアウト制約も確認
→ 制約不足ではなく、共通基盤の画像表示コンポーネントが
デコード上限を指定していないことが根本原因と結論
このクラッシュはスタックトレースに自前のコードのフレームが一つも含まれず、描画フェーズのシステムやライブラリのフレームだけ、という調査の難しいケースだと思います。それでもAIは実際にコードを読みに行き、原因のコンポーネントまで辿り着いていました。ただしこの件は確信度を「中」とし、断定はせず、修正PRも作らずに報告へ留めました(上限値の決定にデザイン要件の確認が必要と判断したためです)。
ケース2: 「直っているはずなのに落ちる」を追う
あるiOSアプリのSIGABRTは、AIの裏取りが有用な例がありました。共通基盤とテナントの両リポジトリをcloneして該当箇所を読み込んだあと、ログを要約すると、次のように推論していました。
最新のコードはすでに修正済みになっている。ということは、このクラッシュは古い版が原因のはずだ。
そこでAIは、テナントが同梱しているコアのバージョン指定ファイルを確認し、まだ古い版を固定したままで修正が取り込まれていないこと、だからこのアプリバージョンでだけ発生していること、を突き止めていました。
「最新は直っている。ならば古い版ではどうか」「テナントが採用しているコアバージョンを確認しよう」というように、人が次に見るべき場所を自分で決めて掘り進めるように思考しているようでした。
精度と限界
原因特定の正しさを厳密に計測しているわけではありません。そのうえで体感を正直に書くと、これまでクラッシュレポートが上がった範囲では、AIの原因特定はいずれも妥当だったと感じています。ただし、本当に難しいクラッシュにまだ当たっていないだけ、という可能性も十分にあり、過信は禁物だと考えています。
精度を支えているのは、各調査が確信度(高・中・低)を明示し、確信度が高く具体的な修正があるときだけ修正ドラフトPRを作り、それ以外は推測と明記して人間の確認に委ねる、という運用です。先ほどのケース1も確信度は「中」で報告に留めました。確信度の表示と人間レビューの二段構えで、誤りをフィルタするようにしています。
おわりに
今回の集計では、コストは1回あたりおおよそ3〜4ドルで、調査の深さに応じて増える傾向があることが分かりました。一次調査のリードタイムは中央値で約7分、9割が12分以内で、人手で数日かかっていた初動が数分に短縮されました。そして探索プロセスとしては、cloneして読み、突き合わせ、裏取りをして判定するという型を数ターンから数十ターン繰り返し、スタックトレースの1行から共通基盤の構造的な原因まで辿り着いていました。
現時点では、AIによるクラッシュの一次調査は実運用に十分活用できると考えています。とはいえ「要対応」と判定されるクラッシュもあり、最終的な判断は人間が担っています。この役割分担は今後も保ちつつ、特に休日に飛んでくるアラートの初動負担が軽くなった効果は大きいと感じています。
今後は、要対応ケースの絞り込み精度の向上や、複数クラッシュの相関分析といった次のステップにも取り組んでいきたいと思います。Crashlytics運用やAIエージェント活用の参考になれば幸いです。