本ブログは、CircleCI Advent Calendar 2023 の7日目の記事です。
はじめに
DevOps の実装において、ビルドやテスト、リリース、デプロイといったステップを自動化するには、設定ファイルにワークフローを記述します。ワークフローが実行されるのは、リポジトリにコードがコミット、プッシュされるタイミングです。
機械学習を自動化する MLOps に関しても同様に、ロジックを実装したコードが変更されるタイミングでワークフローが実行されます。
ただし、MLOps の場合、コードに変更がない場合であっても、トレーニングデータが更新され、モデルを作成し直したいといったような場合があります。モデルを作成し直したら、これまでのテストデータでテストし、結果を見たいと考えるでしょう。テストデータが追加されたので、既存のモデルでテストしてみたいということもあるでしょう。
本記事では、CircleCI を MLOps の「ハブ」として使い、Roboflow のデータをもとにモデルを作成したり(ここまでが本記事)、作成したモデルが Hugging Face に登録されたタイミングでテストを実行する方法(次記事)をご紹介します。
MLOps ワークフローの流れ
ここでは、画像中の人物がマスクを着用しているかどうかを検出するようなモデルの開発を例にとって、説明を進めていきます。今回はロジックの実装には踏み込まず、Ultralytics社の YOLOv8 を使うことにします。また、モデルをトレーニングする上で、Roboflow 上の Mask Wearing Image Dataset を使用することにします。
なお、プロジェクトのリポジトリは、GitHub にあります。
動作環境の設定
トレーニングは CircleCI の Linux GPU 環境上で実行します。
jobs:
build_model:
machine:
resource_class: gpu.nvidia.medium
image: linux-cuda-11:default
CircleCI のリソースクラス(resource_class)とは、ここでは、VM(machine) のスペック(CPU, RAM, GPUのモデル、数、VRAM、SSD容量)の選択に相当します。指定可能なリソースクラスは、こちらをご覧ください。
またイメージ(image)を指定していますが、これは、VM 上で動作させる OS や CUDA のバージョンの選択に相当します。今回は CUDA 11 イメージを環境で実行していますが、本記事作成時点では CUDA 12.0 までサポートされており、また、CUDA のほかにも、PyTorch や Tensorflow、HuggingFace Transformars があらかじめインストールされています。指定可能なイメージは、こちらをご覧ください。
ジョブの定義
ここでは build_model というジョブを定義して、その中で、モデルの元となる教師データの取得、モデルの構築、構築したモデルのアップロードを行います。
GPU スペック確認
まず、リポジトリの内容をチェックアウトし(checkout)し、nvidia-smi コマンドを実行してGPUのスペックを確認しています。なお、スペックの確認自体は必須ではありません。
steps:
- checkout
- run:
name: Check GPU status
command: nvidia-smi
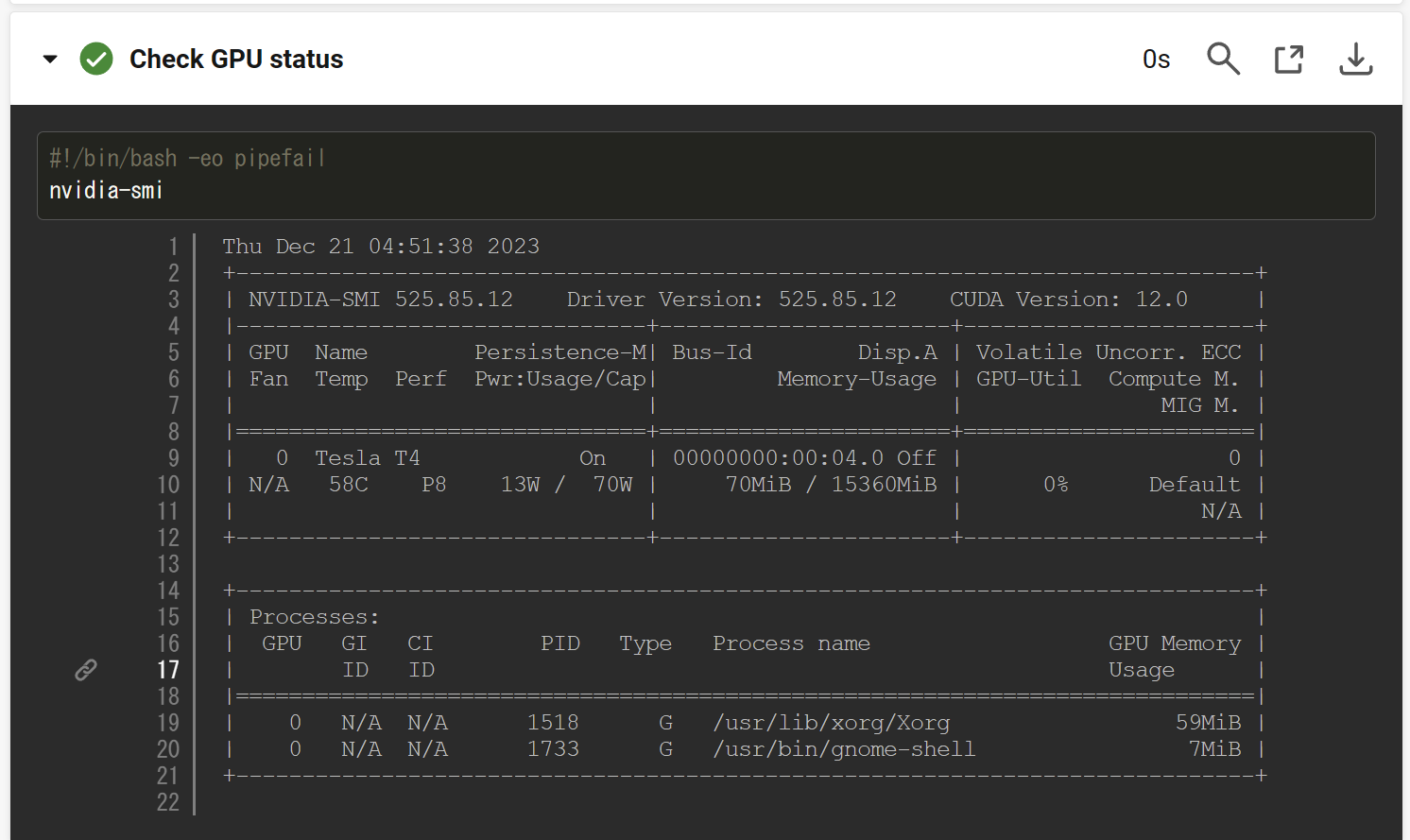
たとえば、次のような情報が得られます。
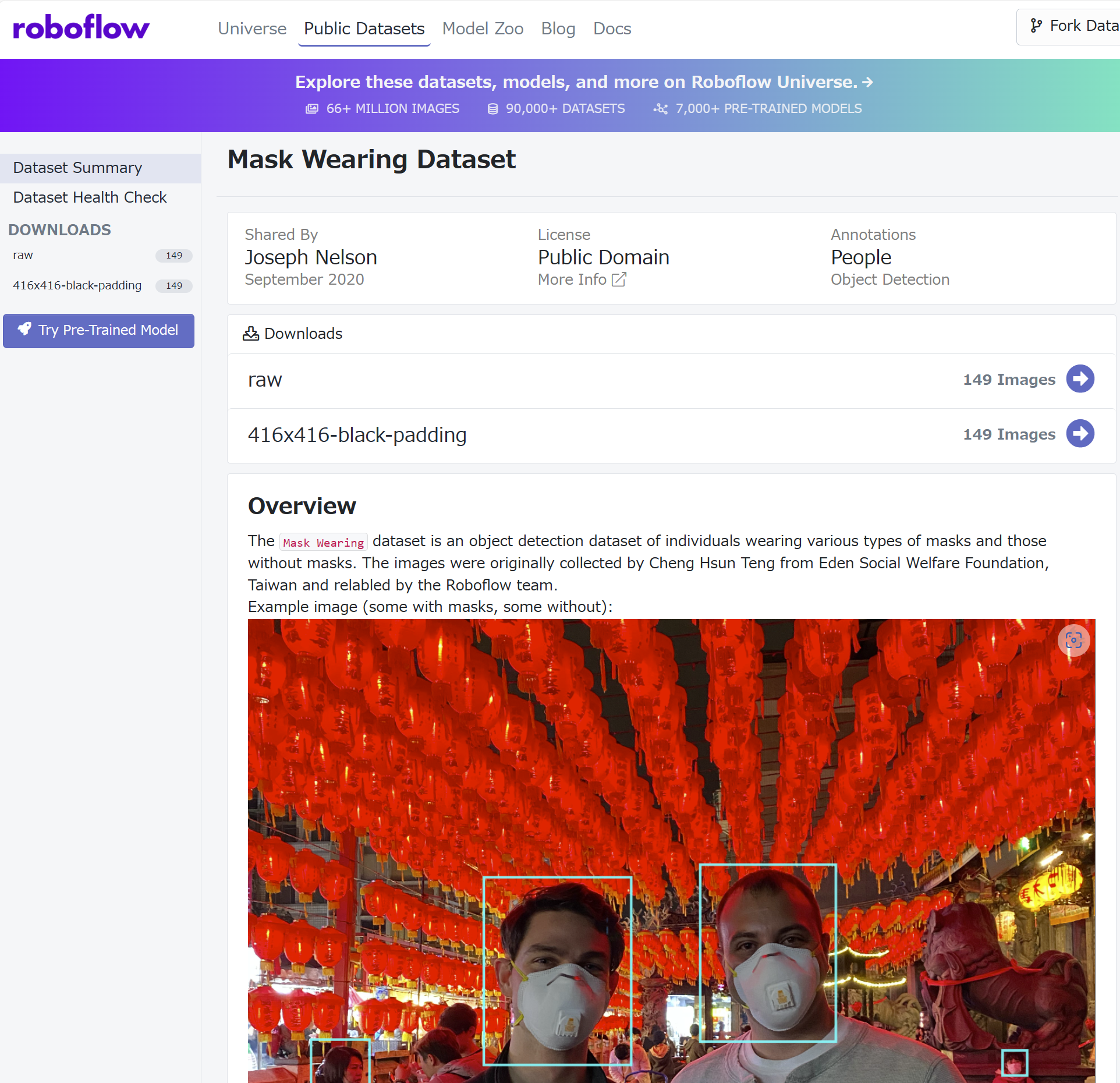
roboflow から教師データを取得
今回はマスク着用/不着用を学習するためのデータとして、roboflow にアップロードされている Mask Wearing Dataset を使用します。
データをダウンロードする部分は、CircleCI では次のように指定します。
- run:
name: Set up a dataset from Roboflow
command: |
cd /opt/circleci
mkdir datasets; cd datasets
curl -L "https://public.roboflow.com/ds/ogCNcy2gya?key=$ROBOFLOW_KEY" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
roboflow からのダウンロードにはアカウントが必要であり、ここでは環境変数 ROBOFLOW_KEY に必要な API キーを設定しておきます。
モデルの構築
ダウンロードしたデータをもとに、モデルの構築を行います。
まずは YOLOv8(パッケージ名はultralytics) の CLI をインストールします。次に、yolo コマンドの引数 model に train を指定してトレーニングを行います。
name: Build a model
command: |
pip3 install ultralytics
cd /opt/circleci/datasets
yolo task=detect mode=train model=yolov8n.pt data=data.yaml epochs=100 imgsz=640 batch=64
モデルの構築には10分弱かかります。
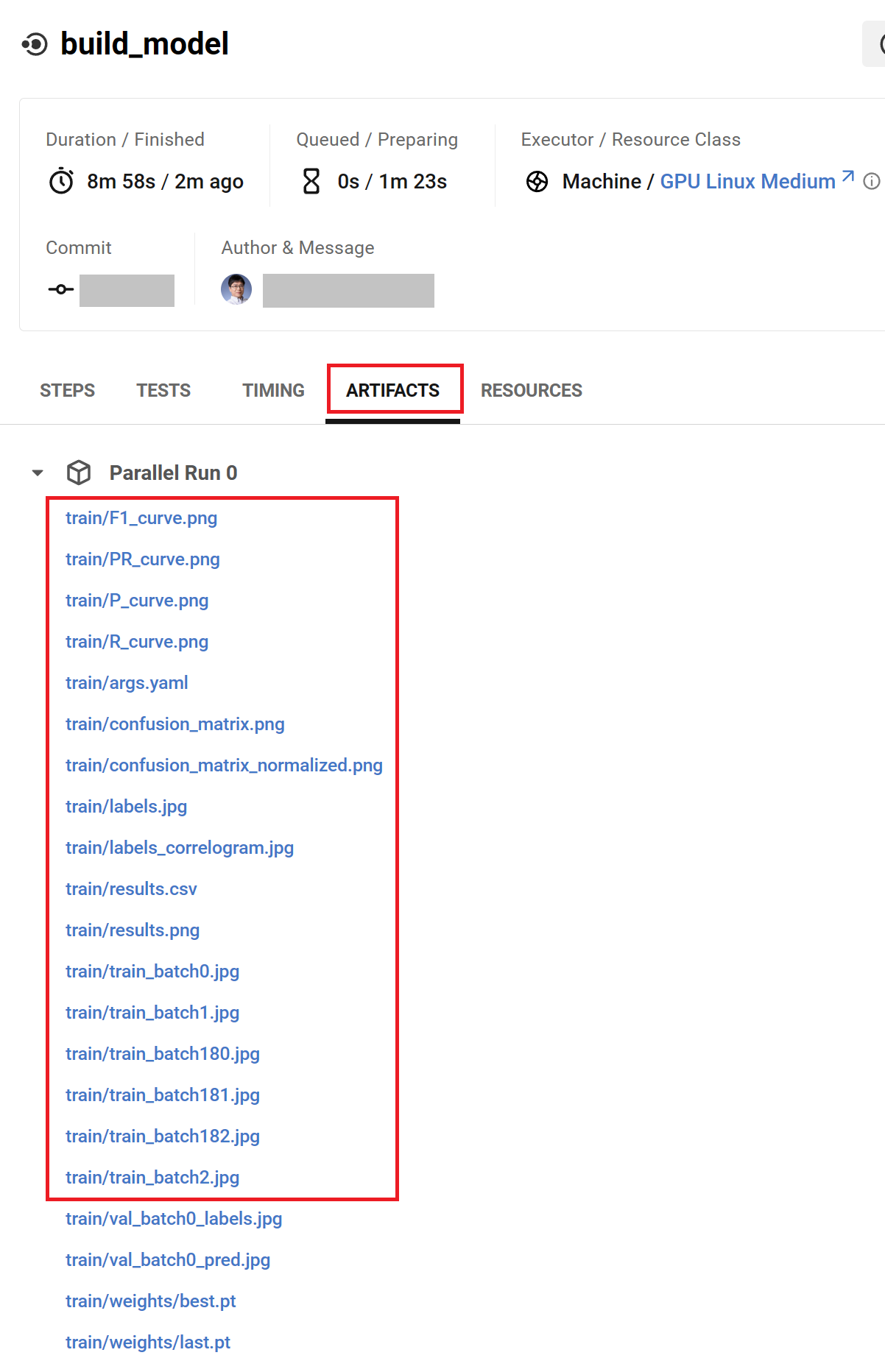
アーティファクトの保存
モデルの構築結果をあとで参照、取得できるようにアーティファクトとして保存しておきます。
- store_artifacts:
path: /opt/circleci/.pyenv/runs/detect/train
destination: train
CircleCI に上のように指定することで、path に指定したディレクトリ以下のファイルが train に保存されます。保存されたファイルは、CircleCIのウェブ画面上で参照、ダウンロードすることが可能です。
構築したモデルを Hugging Face にアップロード
構築したモデルを Hugging Face にアップロードするために、Hugging Face CLI をダウンロードします。
- run:
name: Set up Hugging Face CLI
command: pip3 install -U "huggingface_hub[cli]"
次に Hugging Face CLI の upload コマンドで構築したモデル(mask_best.pt) を、あらかじめ Hugging Face 側で用意しておいた場所([mfunaki/cci-gpu-yolov8-maskdetection])にアップロードします。なお、CircleCI プロジェクトの環境変数として、HUGGINGFACE_TOKEN に API キーを設定しておきます。
- run:
name: Upload the model to Hugging Face
command: |
huggingface-cli login --token $HUGGINGFACE_TOKEN
huggingface-cli upload mfunaki/cci-gpu-yolov8-maskdetection \
/opt/circleci/.pyenv/runs/detect/train/weights/best.pt \
mask_best.pt
リソースクラスを変えた場合の処理時間とコスト
動作環境の設定で紹介したように、CircleCI ではいくつかのLinux GPUリソースクラスを用意しています。
今回ご紹介したモデルの構築において、リソースクラスが違うと処理時間とコストがどれだけ違うか、一例をご覧ください(モデルの構築部分のみの実行時間)。
| クラス | vCPU数 | RAM (GB) | GPU数 | GPU | VRAM (GB) | 実行時間 (mins) | 単価 (credits/min) | コスト (¢) |
|---|---|---|---|---|---|---|---|---|
| small.multi | 4 | 15 | 2 | Tesla T4 | 16 | 3.12 | 160 | 38.4 |
| medium.multi | 8 | 30 | 4 | Tesla T4 | 16 | 3.00 | 240 | 43.2 |
| medium | 8 | 30 | 1 | Tesla T4 | 16 | 2.94 | 240 | 43.2 |
| large | 8 | 30 | 1 | Tesla V100 | 16 | 2.22 | 1000 | 180 |
また、自分で利用可能な GPU リソースがあるということであれば、CircleCI のセルフホストランナーを使うことで費用を抑えることが可能です。セルフホストランナーを使った GPU 活用に関しては、私が公式ブログに書いた以下の記事をご参照ください。
おわりに
本ブログでは、CircleCI の GPU リソースを使った機械学習のモデル構築について説明しました。最後にモデルを Hugging Face に格納しましたが、次のブログでは、Hugging Face に新しいモデルが登録、更新されたのをトリガーに、CircleCI を使って新しいモデルを使って画像認識のテストを行う方法を紹介いたします。