半教師ありGAN
半教師ありGANとは?
半教師学習とは、一言で言うと「少量のラベル付きデータを用いることで、大量のラベルなしデータを生かすことができ、簡単に学習させることができるモデル」。
具体的な話をすると、人間は小さい頃、親とか図鑑で数回程度「これが猫である」と学んだだけで(ラベル付きデータ)、あとは自分で野生の猫とかをみて自己学習しますよね。これとやってることは同じです。ある意味、人間の学習方法に一番近いのが半教師学習なのかもしれませんね。
半教師ありGANとは、「少量のラベル付きデータ(大体全体の1〜2%で十分)を用いることで、大量のラベルなしデータを生かすことができ、簡単に学習させることができる生成モデル」です。上の文章ほぼそのままですけど。
具体的な半教師ありGANの構造は以下の図をご覧ください。
シンプルなGANと大きく異なるのは2点。
1. 識別器に対する入力が、三種類(ラベル付き本物のデータ、ラベルなし本物のデータ、偽データ)
2. 識別器が二値分類ではなく、多クラス分類器である。
具体的には、N+1クラスを分類する識別器。
Nは本物の訓練データに含まれるクラス数、+1は生成器が作った偽画像であることを表すクラス。

実装に際して注意すべき点は主に2点。
- 識別器に対する入力が、ラベル付き(ラベル付き本物データ)かラベルなし(ラベルなし本物のデータ、偽データ)かによって、識別器の出力が異なるので、識別器のモデルを定義するときに場合分けが必要。入力がラベル付きの場合はsoftmaxを用いたクラス分類を、入力がラベルなしの場合はpredictを用いた二値分類を行う。
2.訓練アルゴリズムが通常のGANと大幅に異なる。具体的な訓練アルゴリズムは以下。
通常のGANの訓練アルゴリズムと比較して欲しい。
For 訓練ステップ do:
1.識別器の訓練(教師あり)
a. ラベリングされた本物のデータ(x,y)からランダムにサンプルを取り出し、ミニバッチを作成する
b. このミニバッチからD((x,y))を計算し、求めた多クラスの分類損失を逆誤差伝播し、誤差を再消化するようにθdを更新する
2.識別器の訓練(教師なし)
a. ラベルのない本物のデータxからランダムにサンプルを取り出し、ミニバッチを作成する
b. このミニバッチからD(x)を計算し、求めた二値分類の損失関数を逆誤差伝播し、誤差を最小化するようなθdを更新する
c. ランダムなノイズベクトルzからなるミニバッチを作り、偽の生成サンプルx'からなるミニバッチを作る
d. このミニバッチからD(x')を計算し、求めた二値分類の損失を逆誤差伝播し、誤差を最小化するようにθdを更新する
3. 生成器の訓練
a.ランダムなノイズベクトルzからなるミニバッチを作り、偽の生成サンプルx''からなるミニバッチを作る
b. このミニバッチからD(x'')を計算し、求めた二値分類の損失を逆伝播し、誤差を最小化するようにθgを更新する。
実装
1.import
# 諸々import
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from keras import backend as K
from keras.datasets import mnist
from keras.layers import Activation, BatchNormalization, Concatenate, Dense, Dropout, Flatten, Input, Lambda, Reshape
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.models import Model, Sequential
from keras.optimizers import Adam
from keras.utils import to_categorical
2. モデルの入力次元の設定
# モデルの入力次元の設定
img_rows = 28
img_cols = 28
channels = 1
img_shape = (img_rows, img_cols, channels)
z_dim = 100
num_classes = 10
3. データの整形
# 訓練とテストの為のデータの整形
class Dataset:
def __init__(self, num_labeled):
self.num_labeled = num_labeled
(self.x_train, self.y_train),(self.x_test, self.y_test) = mnist.load_data()
def preprocess_imgs(x):
x = (x.astype(np.float32) - 127.5) /127.5
#x = (x / 127.5) -1.0
x = np.expand_dims(x, axis = 3)
return x
def preprocess_labels(y):
return y.reshape(-1, 1)
self.x_train = preprocess_imgs(self.x_train)
self.y_train = preprocess_labels(self.y_train)
self.x_test = preprocess_imgs(self.x_test)
self.y_test = preprocess_labels(self.y_test)
def batch_labeled(self, batch_size):
idx = np.random.randint(0, self.num_labeled, batch_size)
imgs = self.x_train[idx]
labels = self.y_train[idx]
return imgs, labels
def batch_unlabeled(self, batch_size):
idx = np.random.randint(self.num_labeled, self.x_train.shape[0], batch_size)
imgs = self.x_train[idx]
return imgs
def training_set(self):
x_train = self.x_train[range(self.num_labeled)]
y_train = self.y_train[range(self.num_labeled)]
return x_train, y_train
def test_set(self):
return self.x_test, self.y_test
num_labeled = 100
dataset = Dataset(num_labeled)
4. 生成器の構築
# 生成器
def build_generator(z_dim):
model = Sequential()
model.add(Dense(256*7*7, input_dim=z_dim))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding="same"))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding="same"))
model.add(Activation("tanh"))
return model
5. 識別器の構築
predict関数が行っている処理に注意!
# 識別器
def build_discriminator_net(img_shape):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=img_shape, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(64, kernel_size=3, strides=2, input_shape=img_shape, padding="same"))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(128, kernel_size=3, strides=2, input_shape=img_shape, padding="same"))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(num_classes))
return model
def build_discriminator_supervised(discriminator_net):
model = Sequential()
model.add(discriminator_net)
model.add(Activation("softmax"))
return model
def build_discriminator_unsupervised(discriminator_net):
model = Sequential()
model.add(discriminator_net)
def predict(x):
'''
10ニューロンの出力大きい(つまりニューロンが入力画像を本物だと知覚した)時、predictionは1.0に近づく。
逆に、10ニューロンの出力が全て小さい(つまりニューロンが入力画像を偽物だと知覚した)時、predictionは0に近づく。
'''
prediction = 1.0 - (1.0 /(K.sum(K.exp(x), axis=-1, keepdims=True) + 1.0))
return prediction
model.add(Lambda(predict))
return model
6. コンパイル
# モデルの構築
def build_gan(generator, discriminator):
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
discriminator_net = build_discriminator_net(img_shape)
# 教師あり学習のコンパイル
discriminator_supervised = build_discriminator_supervised(discriminator_net)
discriminator_supervised.compile(loss='categorical_crossentropy',
metrics=['accuracy'],
optimizer=Adam())
# 教師なし学習のコンパイル
discriminator_unsupervised = build_discriminator_unsupervised(discriminator_net)
discriminator_unsupervised.compile(loss='binary_crossentropy',
optimizer=Adam())
# 生成器のコンパイル
generator = build_generator(z_dim)
discriminator_unsupervised.trainable = False
gan = build_gan(generator, discriminator_unsupervised)
gan.compile(loss='binary_crossentropy', optimizer=Adam())
7.訓練アルゴリズム
# 訓練アルゴリズム
supervised_losses = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for iteration in range(iterations):
#ラベル付きサンプルの取得
imgs, labels = dataset.batch_labeled(batch_size)
labels = to_categorical(labels, num_classes=num_classes)
#ラベルなしサンプルの取得
imgs_unlabeled = dataset.batch_unlabeled(batch_size)
#偽画像バッチの作成
z = np.random.normal(0, 1, ((batch_size, z_dim)))
gen_imgs = generator.predict(z)
d_loss_supervised, accuracy = discriminator_supervised.train_on_batch(imgs, labels)
d_loss_real = discriminator_unsupervised.train_on_batch(imgs_unlabeled, real)
d_loss_fake = discriminator_unsupervised.train_on_batch(gen_imgs, fake)
d_loss_unsupervised = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, z_dim))
gen_imgs = generator.predict(z)
g_loss = gan.train_on_batch(z, real)
if (iteration + 1) % sample_interval == 0:
supervised_losses.append(d_loss_supervised)
iteration_checkpoints.append(iteration+1)
print(
"%d [D loss supervised: %.4f, acc.: %.2f%%] [D loss unsupervised: %.4f] [G loss: %f]"
% (iteration + 1, d_loss_supervised, 100 * accuracy,
d_loss_unsupervised, g_loss))
8. 訓練開始
iterations = 8000
batch_size = 32
sample_interval = 800
train(iterations, batch_size, sample_interval)
9. テストデータに対する精度
x, y = dataset.test_set()
y = to_categorical(y, num_classes=num_classes)
# Compute classification accuracy on the test set
_, accuracy = discriminator_supervised.evaluate(x, y)
print("Test Accuracy: %.2f%%" % (100 * accuracy))
10. 精度結果
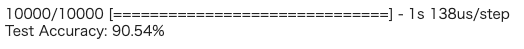
ラベルなしデータにラベル付きデータをほんの少しの割合(今回の実装では100個)加えることで、半教師ありGANを実装しました。その結果学習された識別器は、テストデータのサンプルの90%を正確に分類することができました。
比較のために、同じく100個ラベル付きデータを用いた完全教師あり学習を同じネットワーク構造で行った結果、テストデータサンプルの70%しか正確に分類できませんでした。
つまり、少量のラベルありデータに対して、そのまま完全教師あり学習を行うのではなく、ラベルなしデータを加えて半教師あり学習を行うことにより、精度を20%近く上げられるのです!
次の記事では、conditional GANについて詳しくみていきます。
参考文献
・https://sinyblog.com/deaplearning/gansemi-supervised-gan-001/