 (上図は[公式サイト](https://dvc.org/)のもの。)
(上図は[公式サイト](https://dvc.org/)のもの。)
はじめに
機械学習(ML)を扱う研究ないし製品開発プロジェクトにおいては、データサイエンティストやMLエンジニアがMLモデルの試作を繰り返すことでモデルの性能を改善しようと努力します。その試行錯誤の過程で発生する問題として、データ(前処理済みデータセットやモデルなど)や精度の管理が煩雑になりがちになります。そのようなプロジェクト内のリソースを適切に管理していないと、意図せずプロジェクトのデータを改変してしまった時に、ある精度はどのようなパラメータでどのようなモデルをどのようなコードで学習した結果なのかわからなくなってしまいます。学習や評価の過程を再現できなければ、数字の客観性に乏しくなってしまいます。したがって、データのバージョンを適切に管理して、成果物のトレーサビリティを担保することが大切になります。
データのバージョン管理ツールとしてまず思い浮かぶのはGitではないかと思います。DVC(Data Version Control)はGitと併用してMLプロジェクトのリソース管理や試作開発を支援するツールです。下図は公式サイトに掲載されている、DVCでのデータ管理を表現した図に説明をつけたものです。

DVCは、あるコードバージョンと対応づくデータをすぐに準備してくれます。その仕組を4つの領域にわけて説明します。コード類は右上のgitで従来どおり管理します。バージョン管理したいデータは実体を右下のリモートストレージにおきます。データのバージョン情報だけを左上のdvcファイル(中身はテキストデータ)に持っておき、これもgitで管理します。このdvcファイルにはどういう入力がきてどういうコマンド実行しどういう出力がされるかの情報が載っており、このファイルを実行すると、左下のローカル環境に無いデータは右下のリモートから取得されて実行されます。このように、左上のdvcファイルがデータのバージョンをもっており、それがgitのコードバージョンと結びついていることで、実験環境の保存や再現ができるという仕組みです。
さて、DVCの公式サイトでは、これからDVCを触る人に向けて、いわゆるチュートリアルとして、TutorialとGet Startedの2つのレッスンを提供しています。
前者のTutorialに関しては、すでに先人の方が、すばらしい日本語解説記事を書いてくださっています。
そこで私は、後者のGet Startedをやってみました1。写経をただするだけだと学習効果が薄いので、今回サブノートという形でQiitaに残しました。時間が経つと、元のサイトのページやリソースがリンク切れになるかもしれません。その時がこの記事の賞味期限切れのタイミングということになりますので、予めご了承ください。
私の実行環境は下記です。
- DVC: 0.57.0
- OS: Ubuntu 16.04 LTS
- Python: 3.6.7
- git: 2.7.4
※以下の各見出し(ヘッダー)を、Get Startedの対応ページへのリンクにしました。私の記事では割愛した部分も多いので、併せてご覧いただければと思います。
1. アジェンダ
これから行うの機械学習の実験シナリオの説明です。シナリオはStackOverflowの質問文を入力として、トピックのタグを推定するモデルを学習・評価するというものです。
下図は、公式サイトに掲載されているシナリオのフロー図です。大きく分けて6つのステップがあります。

機械学習タスクの基本的とも言える流れですが、それぞれのステップの具体的な補足説明をすると、下記になります。
- データの収集: StackOverflowからデータをクローリングします。ただし、このレッスンでは割愛されています。代わりにでき合いのxmlファイルをダウンロードします。
- データの前処理: xmlファイルから、機械学習に使うデータを抽出し、tsvファイルとして出力します。
- データセットを学習と評価に分ける
- 特徴抽出: 文章をn-gram特徴量にします。
- モデルの学習
- モデルの評価
それぞれのステップの中で、 data artifacts(最終成果物や中間ファイル)ができるので、ステップを後から再現できるように、それらのバージョンをトラッキングし保存したいです。gitでもできるのですが、DVCはそのようなdata artifactsのバージョン管理だけでなく、それらを用いた再現実験も支援します。
それではレッスンを始めていきましょう!
2. DVCのインストール
DVCはOSのパッケージ管理ソフトでインストールすることができます。別の手段として、Pythonのパッケージ管理ツールであるpipからもインストールすることができます。
私はpip経由でDVCをインストールしました。主な理由は、仮想環境でレッスンを完結させたいためです。「Get Started」のレッスンには、Pythonのパッケージをインストールして使うステップがあり2、私個人のPython開発環境が汚れる可能性があったため、DVCレッスン用の仮想環境を用意しました。私の場合は、仮想環境構築にvirtualenvを使用しました。
$ virtualenv myenv
$ source myenv/bin/activate
DVCをインストールします。
$ pip install dvc
ちなみに、元のページでは、DVCのコマンドを補完できるようにする設定がShell autocompleteページに載っています。ちなみに私もこのページの通りに設定してみたのですが、なぜか補完が効きませんでした。
3. 機械学習プロジェクトの作成
まずは適当な場所に、MLプロジェクトを想定したgitリポジトリを新規で作ります。先に述べますが、この章の手順を終えると最終的には、下図のような(隠しディレクトリからなる)フォルダ構成になります。

$ mkdir example-get-started
$ cd example-get-started
$ git init
次にDVC側の初期化を行います。dvc initをすると、.dvc/ディレクトリが作られ、.dvc/.gitignoreと.dvc/cacheと.dvc/configが作成されています。また、.dvc/configと.dvc/.gitignoreがgitの管理対象になっていますので、これをcommitします。
$ dvc init
$ ls -a # .dvcディレクトリができているか確認
. .. .dvc .git
$ git commit -m "Initialize DVC project"
なお、この時点では、.dvc/configの中身は空です。
4. DVCのコンフィグの設定

データセットやMLモデルなどのバージョン管理はしたいものの、これらのデータは容量が大きく、そのマスターデータをgitで管理するのはあまりいいやり方ではありません。したがって、データの実体はgitとは別の場所に保存したいです。DVCでは、gitリポジトリとは別に、そのようなサイズの大きなデータをリモートのストレージに保存するようにします。
ストレージですが、S3などの大手クラウドベンダのストレージサービスを指定することもできますし、ローカル上やNAS上のディレクトリを仮想のリモート上のストレージとみなして指定することもできます。今回は、ローカルに保存するように設定します。保存先の設定は.dvc/configに、DVCのコマンドを介して、書き込みます。
$ dvc remote add -d myremote /tmp/dvc-storage
Setting 'myremote' as a default remote.
すると、先程まで空ファイルだった.dvc/configに情報が書き込まれています。
$ cat .dvc/config
['remote "myremote"']
url = /tmp/dvc-storage
[core]
remote = myremote
gitの管理対象である.dvc/configを変更したことになるため、commitします。
$ git commit .dvc/config -m "Configure local remote"
リモートストレージの設定が終わりました。次の章でこのリモートストレージで管理すべきデータを登録します。
5. ファイルをDVCの管理対象に追加する

gitでのバージョン管理に適さない大容量のデータをDVCの管理対象に追加してみます。
まず、今回のモデル学習に使うデータセットを落としてきます。
$ mkdir data
$ wget https://data.dvc.org/get-started/data.xml -O data/data.xml
落としてきたデータを、DVCの(≠gitの)管理対象にします。DVCの管理対象にすると、DVC管理対象のデータが存在する場所に、.gitignoreとdata.xml.dvcが作られます。dvcコマンドを実行した時点で、この2つのファイルはgitの管理対象として追加されます。
$ dvc add data/data.xml
Adding 'data/data.xml' to 'data/.gitignore'.
Saving 'data/data.xml' to '.dvc/cache/a3/04afb96060aad90176268345e10355'.
Saving information to 'data/data.xml.dvc'.
To track the changes with git, run:
git add data/.gitignore data/data.xml.dvc
$ ls data
data.xml data.xml.dvc
.gitignoreの中身は、DVCの管理対象にしたデータが記載されています。すなわち、もとのデータの実体はgitの管理対象外として扱われます。
$ cat data/.gitignore
/data.xml
もとのファイルはgitの管理対象外ですが、もとのファイル名に.dvcのついたファイルであるdata.xml.dvcはgitの管理対象に追加されます。ファイルのハッシュ値(a304afb96060aad90176268345e10355)が記録されていますので、data.xmlに変更があった時、検出できます。
$ cat data/data.xml.dvc
md5: cf591bad7130693369f092bbfffe8672
wdir: ..
outs:
- md5: a304afb96060aad90176268345e10355
path: data/data.xml
cache: true
metric: false
persist: false
これら2つのファイルを管理対象に追加したことをcommitします。
$ git add data/.gitignore data/data.xml.dvc
$ git commit -m "Add raw data to project"
公式サイトの情報によると、この時点でDVCで管理するデータ(data.xml)は、.dvc/cacheの中に移動し、もともとファイルがあった場所にはシンボリックリンクができるようです。移動した時に、もとのファイルのハッシュ値にリネームされます。この例では、a3というディレクトリの下に04afb96060aad90176268345e10355というファイル名になっています。なぜ、もとのデータのハッシュ値の先頭2文字をディレクトリに使うのかはわかりませんでした。
$ ls -R .dvc/cache
.dvc/cache:
a3
.dvc/cache/a3:
04afb96060aad90176268345e10355
ただし、シンボリックリンクを張るのに何らかの理由で失敗した場合は、もとの場所にはファイルの実体がそのまま残り、.dvc/cacheにはデータがコピーされるようです。そのため、ファイルサイズが大きい場合は、コピーに時間がかかります。
6. DVC管理対象データをリモートストレージへの保存

gitのごとく3、DVCのリモートにデータをpushします。
$ dvc push
Preparing to upload data to '../../../../../../tmp/dvc-storage'
Preparing to collect status from ../../../../../../tmp/dvc-storage
Collecting information from local cache...
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2616.53md5/s]
Collecting information from remote cache...
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 6087.52md5/s]
Analysing status: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 8097.11file/s]
$ ls -R /tmp/dvc-storage # リモートを確認。
/tmp/dvc-storage:
a3
/tmp/dvc-storage/a3:
04afb96060aad90176268345e10355
これで、マスタデータがリモートストレージに配置されたので、他人と共有しやすくなります。
7. 保存されているデータの取得
DVC管理対象データが消されても、復元できるか試してみます。
$ rm -f data/data.xml
$ ls data # データが無いことを確認。
data.xml.dvc
消したデータを取得してみます。
$ dvc pull
$ ls data
data.xml data.xml.dvc
.dvc拡張子のファイルを指定して明示的に1つのファイルを取得することもできます。
$ dvc pull data/data.xml.dvc
ちなみに、キャッシュ上のマスターデータ.dvc/cache/a3/04afb96060aad90176268345e10355を消しても、リモートから取得してくれます。
したがって、他人がこのMLのgitリポジトリをcloneした際には、このようにdvc pullをすれば、学習・推論に必要なデータを取得することができるようになります。
8. ソースコードとデータを紐付ける

ここまでは、大容量のデータをリモートでバージョン管理するシナリオでした。この項では、データの生成過程を再現するシナリオを考えます。すなわち、どういうデータをどういうソースコードで学習・推論させたときに、何のデータが生成されるのかを記録することを考えます。
まず、MLモデルの学習・推論を行うソースコードをダウンロードします。ちなみに、展開前のファイル名はcode.zipですが、展開すると、srcという名前でディレクトリができます。
$ wget https://code.dvc.org/get-started/code.zip
$ unzip code.zip
$ rm -f code.zip
このコードを動かすのに必要なPythonパッケージがsrc/requirements.txtにあるので、インストールします。今一度、仮想環境の中に入っていることをご確認ください。
$ pip install -r src/requirements.txt
それでは、まずはsrc/prepare.pyでデータdata/data.xmlの前処理を行い、MLの学習フォーマットに変換します。具体的には、xmlファイルから、レコードごとにId、Tags,Title,Bodyの要素を抽出し、tsv形式でファイルを出力します。
この操作を、DVCに記録させます。
$ dvc run -f prepare.dvc \
-d src/prepare.py -d data/data.xml \
-o data/prepared \
python src/prepare.py data/data.xml
Running command:
python src/prepare.py data/data.xml
Adding 'data/prepared' to 'data/.gitignore'.
Saving 'data/prepared' to '.dvc/cache/68/36f797f3924fb46fcfd6b9f6aa6416.dir'.
Saving information to 'prepare.dvc'.
To track the changes with git, run:
git add prepare.dvc data/.gitignore
オプションの意味について説明します。dvc runの-fオプションは、出力するdvcファイルのパスを指定します。-dは、実行に依存(depend)するファイルを指定します。後段で処理の再現するとき、この-dオプションで指定したファイルがあるかを確認し、存在しない場合は取得や再生成します。-oオプションでは、処理の結果の成果物の出力先を指定します。オプションの後に、本来実行したかった処理のコマンドを書きます。
上述のコマンドを実行すると、prepare.dvcが生成されます。実行に必要なデータと、実行コマンドと、実行後に生成されるデータの情報が記載されています。すなわち、このファイルはデータの入力→処理→データの出力というパイプライン処理の1ステップを表現していることになります。
$ cat ./prepare.dvc
md5: 645d5baf13fb4404e17d77a2cf7461c4
cmd: python src/prepare.py data/data.xml
wdir: .
deps:
- md5: 1a18704abffac804adf2d5c4549f00f7
path: src/prepare.py
- md5: a304afb96060aad90176268345e10355
path: data/data.xml
outs:
- md5: 6836f797f3924fb46fcfd6b9f6aa6416.dir
path: data/prepared
cache: true
metric: false
persist: false
また、コマンドの成果物であるdata/prepared/train.tsv,data/prepared/test.tsvも生成されます。ただし、これらの成果物はgitではなく、リモートで保存すべきものなので、data/.gitignoreにdata/preparedディレクトリが追記されます。
今一度、.dvc/cacheの中身を見てみると、data/data.xml以外のデータが3つ追加されています。
$ ls -R .dvc/cache
.dvc/cache:
58 68 9d a3
.dvc/cache/58:
245acfdc65b519c44e37f7cce12931
.dvc/cache/68:
36f797f3924fb46fcfd6b9f6aa6416.dir
.dvc/cache/9d:
603888ec04a6e75a560df8678317fb
.dvc/cache/a3:
04afb96060aad90176268345e10355
これらのファイルのうち2つが、data/prepared/train.tsv,data/prepared/test.tsvに該当し、残りの1つが次のようなディレクトリ構造を表すファイルです。prepare.dvcでは、このハッシュ値のディレクトリが処理結果の出力先になっています。したがって、pullをすると、このファイルをまず参照して再帰的にディレクトリ下を探索してファイルを取得するのではないかと推測します。
$ cat .dvc/cache/68/36f797f3924fb46fcfd6b9f6aa6416.dir
[{"md5": "9d603888ec04a6e75a560df8678317fb", "relpath": "test.tsv"}, {"md5": "58245acfdc65b519c44e37f7cce12931", "relpath": "train.tsv"}]%
今回のDVCの操作によって、gitで管理すべきファイルが変更、追加されましたので、commitします。また、リモートで管理すべきファイルも3つ生成されたので、リモートへpushします。
$ git add data/.gitignore prepare.dvc
$ git commit -m "Create data preparation stage"
$ dvc push
9. パイプライン処理の記述

ひどく散らかった図になってしまいました。。。
先ほどdvc runで、入力→処理→出力のパイプラインの1処理を表現するファイルを作成しました。このように、ある処理によって出力されたデータを、別の処理の入力として、処理を連結しながらデータをどんどん加工していき最終的な成果物を出力するパイプラインを簡単に作成できる点が、DVCと他のバージョン管理ツール(たとえばgit lfs)と違う点です。
機械学習モデルの学習の続きをします。
先程はデータの前処理をしましたが、この前処理をしたデータを入力し、特徴抽出処理を行って、特徴を出力します。
$ dvc run -f featurize.dvc \
-d src/featurization.py -d data/prepared \
-o data/features \
python src/featurization.py \
data/prepared data/features
続いて、特徴を入力として、モデルを学習し、モデルを出力します。
$ dvc run -f train.dvc \
-d src/train.py -d data/features \
-o model.pkl \
python src/train.py data/features model.pkl
このように、前処理→特徴抽出→モデル学習というパイプラインを、依存データの入出力を指定することで構築します。項目始めのごちゃごちゃした図はそれを表現しようとした図です。
ここまでの処理の結果を今まで同様、コードはgitで、大容量なデータはリモートへ保存します。
$ git add data/.gitignore .gitignore featurize.dvc train.dvc
$ git commit -m "Create featurization and training stages"
$ dvc push
10. パイプラインの可視化
これまでに構築したパイプラインをCUIで可視化できます。いくつかの粒度にもとづいて可視化でき、元のページでは、Stages(dvcファイル)単位、実行コマンド単位、出力ファイル単位で可視化できる例が載っていました。可視化を実行すると、lessコマンドのように、一時的なビューアーが立ち上がります。閲覧を終了する場合はqコマンドを押します。
Stages単位。指定するdvcファイルが前後で依存するdvcファイルのパスが可視化されます4。
$ dvc pipeline show --ascii train.dvc
+-------------------+
| data/data.xml.dvc |
+-------------------+
*
*
*
+-------------+
| prepare.dvc |
+-------------+
*
*
*
+---------------+
| featurize.dvc |
+---------------+
*
*
*
+-----------+
| train.dvc |
+-----------+
コマンド単位(出力は省略)
$ dvc pipeline show --ascii train.dvc --commands
出力ファイル単位(出力は省略)
$ dvc pipeline show --ascii train.dvc --outs
11. 処理の再現

先ほど構築したパイプラインの処理を再現(reproduce)してみます。そのままでは、最終成果物がすでに出来上がっている状態なので実行しても効果がわかりにくいと思います。したがって、ファイルを一部削除して実行します。
$ rm data/prepared/test.tsv
$ rm model.pkl
$ dvc repro train.dvc
一番、最終の処理のdvcファイルだけを指定していますが、それに依存する処理がすべて実行されます。
すなわち、dvcファイルがあれば、自分以外の人がパイプラインを再現できます。
12. モデルの評価実験におけるメトリクス

学習した後は、モデルの性能を評価すると思います。DVCでは、どういうパイプライン(すなわち、どういうコード、どういうデータセット、どういうハイパパラメータの下での処理)を通って生み出されたモデルが、どういう精度になるかという結果を保存・管理することができます。
$ dvc run -f evaluate.dvc \
-d src/evaluate.py -d model.pkl -d data/features \
-M auc.metric \
python src/evaluate.py model.pkl \
data/features auc.metric
-Mをつけたファイルが、管理したい精度の記録されたファイルです。
evaluate.pyはモデルの性能をAUCという尺度で測り、auc.metricというファイルにAUCを記録するスクリプトです。
$ cat auc.metric
0.588426
これまでと同様に、成果物を保存します。
$ git add evaluate.dvc auc.metric
$ git commit -m "Create evaluation stage"
$ dvc push
また、ここまでで、モデル学習の一区切りがついたので、リポジトリにタグを打ちます。今回の結果を再現したい場合は、このタグのコミットへ飛べばよいということになります。
$ git tag -a "baseline-experiment" -m "Baseline experiment evaluation"
13. コードを改造して精度の評価実験
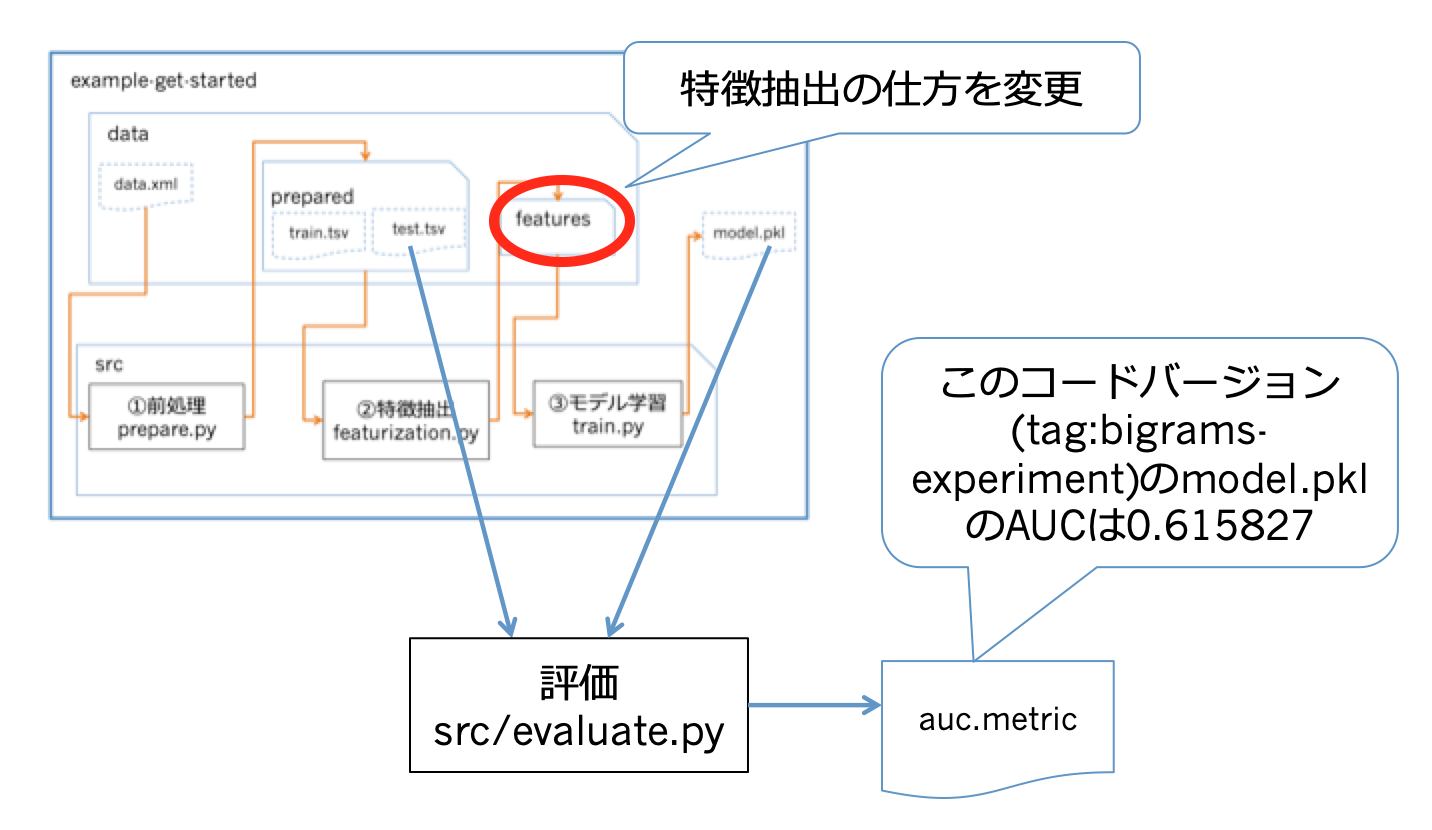
モデルの評価実験においてはよくあるケースですが、
MLモデルの一部のコードやハイパパラメータのコンフィグを少し変えて、それ以外は同等の条件で精度を出してみたいという状況があります。
例えば、src/featurization.pyのうち、特徴抽出をする下記の部分をエディタで変えてみます。変更内容ですが、これまでは1-gram単位で特徴ベクトルを作っていましたが、,ngram_range=(1, 2)をつけて2-gramも追加して、特徴量を拡大します。
bag_of_words = CountVectorizer(stop_words='english',
max_features=6000, # 末尾のコンマもつけ忘れずに!
ngram_range=(1, 2))
その後で、学習を再現します。
$ dvc repro train.dvc
同じパイプラインのものは、同じコマンドで実行できます。
ここで、git diffで変更内容を見てみると、featurize.dvcとtrain.dvcに変更が起こっており、成果物のmd5が変わっています。
この変更をコミットします。
$ git commit -am "Reproduce model using bigrams"
さて、ベースライン(1-gramだけの特徴)のモデルのコミットに戻りたいとします。その時は、gitのコミットを変え、そのあとでデータをdvcで管理しているバージョンにcheckoutします。dvcに必要な情報dvcファイルという形でgitに保存してあるので、dvcコマンドで明示的なバージョンを指定する必要はありません。
$ git checkout baseline-experiment
$ dvc checkout
14. 実験結果の比較

1-gram+2-gramの特徴量の方のモデルも精度評価します。
バージョンを変え、dvc reproで、評価のパイプラインを再現実行します。
$ git checkout master
$ dvc checkout
$ dvc repro evaluate.dvc
evaluate.dvcとauc.metricに変更が起きます。AUCが0.615827に上がっています。
この時点のコミットをタグづけします。
$ git commit -am "Evaluate bigrams model"
$ git tag -a "bigrams-experiment" -m "Bigrams experiment evaluation"
精度を比較します。タグにおける精度が整形されて出力されます。
$ dvc metrics show -T
working tree:
auc.metric: 0.615827
baseline-experiment:
auc.metric: 0.588426
bigrams-experiment:
auc.metric: 0.615827
15. 過去のバージョンのデータを取得
元のページには、gitのcheckoutでdvcファイルのバージョンを変え、dvcのcheckoutでデータのバージョンを変える旨が書かれています。説明が重複するので割愛します。
所感
データの管理や精度管理など再現実験に強いので、トレーサビリティの面で優れていると思いました。欲を言うなら、複数人での実験管理を進める上で下記の機能があるともっといいと思いました。
- バージョンの自動命名機能
- tagの命名規則を真面目に考えないと、どういう条件でだした数値かわかりにくくなる恐れがあります。そもそも、スコアを刻む単位がtagでよいのか、ということはあります。
- 可視化
- スコアは一覧できますが、グラフのような形で可視化できたらな、と思いました。
- 動作環境の提供
- なんというか、dockerコンテナを作ってそこで実行してくれたり、Pipenvみたいな環境を勝手につくってくれたり、、という機能があると、セットアップが楽になると思いました。
他にも、プロダクションでの運用に組み込むなら、オンラインデータ処理を想定した機能も望まれると思います。
DVCの今後のバージョンアップに期待したいと思います。