Data Version Control(DVC)とは?
データ分析や機械学習のコードを書いているときに遭遇する以下のような問題を解決してくれるツールです。
- データセットの管理がつらい
- 例えば、Gitのリポジトリで大きい容量のデータセットを管理することは不便になりがち
- Githubには1ファイルのサイズ上限100MBで、それ以上はpushできない(https://help.github.com/articles/what-is-my-disk-quota/)
- 実験条件が微妙に異なるときのバージョン管理
- ハイパパラメータ、前処理、データセットが異なるときバージョン管理は煩雑になりがち
- 実験を再現できるようにする工夫が必要
- データセット、スクリプト、各種パラメータなどがそろっていないとモデル作成が再現できない
- 中間生成ファイルが階層的にあり、最終的にモデルが生成されるといった時の再現性の担保
DVCは実験管理ソフトウェアと呼ばれるもので、Gitと一緒に使用することでデータセット、スクリプト、モデルなどのバージョン管理を行えるように作られています。また、モデル作成の一連の手順も設定ファイルとして出力し、実験を再現する機能を提供しています。
DVCのソフトウェアとしての思想は以下のページにまとまっているので、興味のある方は参照ください。
https://dvc.org/doc/dvc-philosophy/what-is-dvc
DVCの特徴
公式ドキュメントのCore FeaturesによるとDVCの主な特徴は以下になっています。
- Gitのリポジトリと一緒にDVCは使用される
- コマンドがGitと似ているので、Gitに慣れている人は使い始める障壁が低い
- 軽量なパイプラインを作成し、実験を再現可能にする
- 大きなデータファイルのバージョン管理が可能
- プログラミング言語に依存しない
- DVCはOSSで外部サービスに依存しない
- データを社外に出せない環境でも使用可能
- DVCはクラウドサービスもサポートしている(AWS S3, Azure Blob Storage, GCP)
DVCのバージョン管理の概要
画像は公式ドキュメントから引用
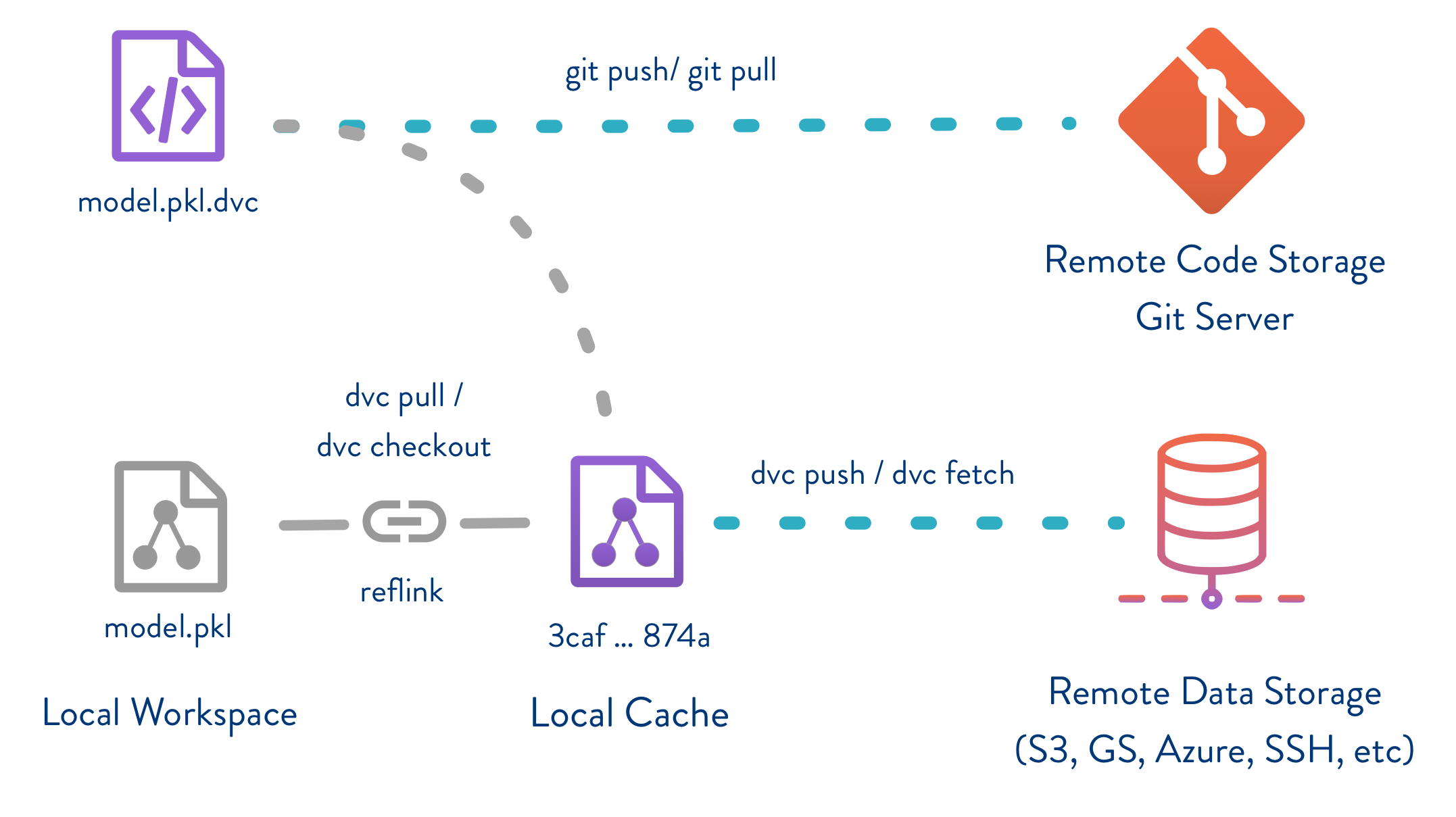
DVCを用いた時のデータやモデルファイルのバージョン管理の概要を以下に説明します。
DVCコマンドを実行することで、.dvcという拡張子を持ったファイルを作成し、データやモデルについての情報を格納します。上図のように実体となるデータやモデルファイルはLocal Cacheに置かれ、作成された.dvcファイルに紐つけられます。コードと一緒に.dvcファイルだけがGitリポジトリで管理され、データやモデルといった大きなサイズとなりうるファイルは、Gitリポジトリとは別のリモートのデータストレージに置いて管理します。
DVCを実際に動かしてみる
以下は公式ドキュメントのTutorialをやってみた際の手順をまとめたメモとなります。
英語の公式ドキュメントを見た方が早いと言う方はそちらを参照ください。
動作確認したバージョンは以下になります。
- Python 3.6.7
- DVC 0.22.0
準備
環境構築とサンプルコードのダウンロード
- 作業ディレクトリを作成し、gitの初期化、公式Tutorialのサンプルコードをダウンロードする。ダウンロードが完了したら、展開してgitにコミットする。
$ mkdir classify
$ cd classify
$ git init
$ wget https://dvc.org/s3/so/code.zip
$ unzip code.zip && rm -f code.zip
$ git add code/
$ git commit -m 'download code'
自分はcondaで仮想環境を構築しましたので手順は以下になります。(ここは自分の環境に合わせて変えてください)
- 以下のコマンドを実行して仮想環境を作成し、仮想環境に入る。
$ conda create -n py36-dvc python=3.6
$ source activate py36-dvc
- Tutotrialに必要なライブラリをインストールする。
$ pip install -r code/requirements.txt
DVCのインストール手順
- 一番楽なインストール方法は以下のようにpipでインストールする
$ pip install dvc
dev,rpm, homebrowでのインストール手順も提供されており、他の方法による詳細なインストール手順は以下を参照してください。
https://dvc.org/doc/get-started/install
Bashでコマンドの補完が効くようにする
Bashシェルでコマンド補完が効くようにする手順の詳細については以下を参照してください。
https://dvc.org/doc/user-guide/autocomplete
ドキュメントにあったLinuxOSでの手順を以下に示す。ドキュメント通りに実行するだけ。
- 以下のコマンドを実行する
$ sudo wget -O /etc/bash_completion.d/dvc https://raw.githubusercontent.com/iterative/dvc/master/scripts/completion/dvc.bash
- シェルを再起動する。
- 仮想環境に再度入る。
DVCの初期化をする
- 以下のコマンドを実行して、作業ディレクトリでDVCの初期化をする。
$ dvc init
$ ls -a .dvc/
. .. .gitignore cache config updater updater.lock
dvc initを実行すると上のように.gitignore,cache,configなどが作成されます。.dvcディレクトリ内はユーザが基本的にはいじる必要のないディレクトリとなります。また、cacheディレクトリには、実体のデータファイルやモデルファイルが置かれ、Gitリポジトリにはpushされないようになります。
.dvc/.gitignoreの中身を見ると以下のようになっており、cacheディレクトリがgitの管理下にないことがわかります。
$ cat .dvc/.gitignore
/state
/lock
/config.local
/updater
/updater.lock
/state-journal
/state-wal
/cache
Pipelineを定義する
データファイルを取得する
- 以下のコマンドを実行して学習に使用するデータセットを取得する。
$ mkdir data
$ wget -P data https://dvc.org/s3/so/100K/Posts.xml.zip
$ du -sh data/*
41M data/Posts.xml.zip
-
dvc addコマンドを実行して、data/Posts.xml.zipをDVCの管理下に入れる。コマンドを実行するとPosts.xml.zip.dvcというファイルが作成される。
$ dvc add data/Posts.xml.zip
$ du -sh data/*
41M data/Posts.xml.zip
4.0K data/Posts.xml.zip.dvc
- また、
git statusコマンドを実行するとdata/.gitignoreが作成されていることがわかる。
$ git status -s data/
?? data/.gitignore
?? data/Posts.xml.zip.dvc
-
data/.gitignoreを確認すると/Posts.xml.zipのデータ本体はgit管理から外されていることが確認できる。
$ cat data/.gitignore
/Posts.xml.zip
- ここまでの作業を一旦gitにcommitしておく。
$ git add .
$ git commit -m 'add source dataset'
- また、
git ls-filesコマンドでもPosts.xml.zipはgit管理下にないことが表示される。
$ git ls-files
.dvc/.gitignore
.dvc/config
code/conf.py
code/evaluate.py
code/featurization.py
code/requirements.txt
code/split_train_test.py
code/train_model.py
code/xml_to_tsv.py
data/.gitignore
data/Posts.xml.zip.dvc
- 以下のコマンドを実行して
data/Posts.xml.zip.dvcの中身を確認する。
$ cat data/Posts.xml.zip.dvc
md5: 7559eb45beb7e90f192e836be8032a64
outs:
- cache: true
md5: ec1d2935f811b77cc49b031b999cbf17
path: Posts.xml.zip
.dvcファイルの中身はyamlファイルでDVCの管理に必要な情報が書かれている。Posts.xml.zip.dvcファイルには、Posts.xml.zipのmd5 cacheが格納されており、以下のコマンドを実行すると.dvc/cacheディレクトリに本体のデータがあることが確認できる。
$ du -sh .dvc/cache/ec/*
41M .dvc/cache/ec/1d2935f811b77cc49b031b999cbf17
runコマンドを実行する
- DVCには
dvc runコマンドで処理のpipelineを定義する機能があるので、それを実行する。
$ dvc run -d data/Posts.xml.zip -o data/Posts.xml \
unzip data/Posts.xml.zip -d data/
Running command:
unzip data/Posts.xml.zip -d data/
Archive: data/Posts.xml.zip
inflating: data/Posts.xml
Adding 'data/Posts.xml' to 'data/.gitignore'.
Saving 'data/Posts.xml' to cache '.dvc/cache'.
Saving information to 'Posts.xml.dvc'.
To track the changes with git run:
git add data/.gitignore Posts.xml.dvc
$ du -sh data/*
154M data/Posts.xml
41M data/Posts.xml.zip
4.0K data/Posts.xml.zip.dvc
上のコマンドのオプション引数については以下となっています。
-
-dunzipコマンドを実行するのに必要な依存ファイルを指定 -
-oDVCが管理下に入れる出力ファイル(dvc add data/Posts.xmlを実行するのに等しい)
上のコマンドを実行したことにより、data/Posts.xmlは.dvc/cacheに移動し、.gitignoreにファイル名が追加されてgit管理されないようになります。
- 以下のコマンドを実行してdvcファイルを確認する。実行したコマンドを再現するために必要な情報が記載されている。
$ cat Posts.xml.dvc
cmd: ' unzip data/Posts.xml.zip -d data/'
deps:
- md5: ec1d2935f811b77cc49b031b999cbf17
path: data/Posts.xml.zip
md5: 16129387a89cb5a329eb6a2aa985415e
outs:
- cache: true
md5: c1fa36d90caa8489a317eee917d8bf03
path: data/Posts.xml
上のPosts.xml.dvcの記載内容の説明は以下になります。
-
cmd実行するコマンド -
depsコマンド実行に依存するファイル情報 -
outsコマンド実行後に出力されるファイル情報
dvc runコマンドの実行で生成されたdvcファイルと、Posts.xmlが.gitignoreに追加されたことを見ます。
- 以下のコマンドを実行して更新されたファイルと、.gitignoreに追加されたファイルを確認する。
$ git status -s
M data/.gitignore
?? Posts.xml.dvc
$ cat data/.gitignore
Posts.xml.zip
Posts.xml
- 以下のコマンドを実行して、Posts.xmlが.dvc/cacheにあることを確認する。
$ du -sh .dvc/cache/c1/* .dvc/cache/ec/*
154M .dvc/cache/c1/fa36d90caa8489a317eee917d8bf03
41M .dvc/cache/ec/1d2935f811b77cc49b031b999cbf17
表示されたmd5 cacheが.dvcに記載されているものと等しいので同じデータセットであることがわかります。
- ここまでの作業をgitにcommitします。
$ git add .
$ git commit -m 'extract data`
- 続いて学習のいくつかのstepを実行する。1つ目はデータファイルをxmlからtsv形式に変換。2つ目はtsvに変換したデータファイルをtrain,testに分割する。
$ dvc run -d data/Posts.xml -d code/xml_to_tsv.py -d code/conf.py \
-o data/Posts.tsv \
python code/xml_to_tsv.py
$ dvc run -d data/Posts.tsv -d code/split_train_test.py \
-d code/conf.py \
-o data/Posts-test.tsv -o data/Posts-train.tsv \
python code/split_train_test.py 0.33 20180319
上の2つのコマンドを実行すると、以下のようにそれぞれの出力ファイルに対応する.dsvファイルができています。
$ git status -s
M data/.gitignore
?? Posts-test.tsv.dvc
?? Posts.tsv.dvc
?? code/__pycache__/
- 不要なディレクトリを以下のコマンドで無視するようにする。
$ echo "code/__pycache__" >> .gitignore
- ここまでの作業をgitにcommitする。
$ git add .
$ git commit -m 'Process to TSV and separate test and train'
- 次に特徴量抽出のstepを実行する。
$ dvc run -d code/featurization.py -d code/conf.py \
-d data/Posts-train.tsv -d data/Posts-test.tsv \
-o data/matrix-train.p -o data/matrix-test.p \
python code/featurization.py
Running command:
python code/featurization.py
The input data frame data/Posts-train.tsv size is (66999, 3)
The output matrix data/matrix-train.p size is (66999, 5002) and data type is float64
The input data frame data/Posts-test.tsv size is (33001, 3)
The output matrix data/matrix-test.p size is (33001, 5002) and data type is float64
- モデル学習のstepを実行する。
$ dvc run -d data/matrix-train.p -d code/train_model.py \
-d code/conf.py -o data/model.p \
python code/train_model.py 20180319
Running command:
python code/train_model.py 20180319
Input matrix size (66999, 5002)
X matrix size (66999, 5000)
Y matrix size (66999,)
- 精度評価のstepを実行する。
$ dvc run -d data/model.p -d data/matrix-test.p \
-d code/evaluate.py -d code/conf.py -o data/eval.txt \
-f Dvcfile \
python code/evaluate.py
Running command:
python code/evaluate.py
上の精度評価のコマンド実行では、-fでDvcfileを出力している。このファイルは精度評価までの実験の再現に必要な情報が記載されて出力される。
- 以下のコマンドを実行して生成されたファイルを確認する。
$ git status -s
M data/.gitignore
?? Dvcfile
?? matrix-train.p.dvc
?? model.p.dvc
特徴量抽出と、モデル学習の結果のdvcファイルがそれぞれ生成されています。
- これまでの作業をコミットする。
$ git add .
$ git commit -m Evaluate
-
data/eval.txtに精度評価の結果が出力されているので、確認する。
$ cat data/eval.txt
AUC: 0.630725
これで一連のpipelineの定義は完了です。次にDVCの実験の再現機能を見ていきます。
実験の再現
dvc reproコマンドの使用方法
DVCでは以下のようにdvc reproコマンドを用いて一連の処理を再現することができます。
- 以下のコマンドを実行する。
$ dvc repro model.p.dvc
Stage 'data/Posts.xml.zip.dvc' didn't change.
Stage 'Posts.xml.dvc' didn't change.
Stage 'Posts.tsv.dvc' didn't change.
Stage 'Posts-test.tsv.dvc' didn't change.
Stage 'matrix-train.p.dvc' didn't change.
Stage 'model.p.dvc' didn't change.
上のコマンド実行では、作成された.dvcファイルのいずれも変更がないので特に何も処理は行われません。データセットの変更やスクリプトの変更などがあった場合に再度処理が行われる形となります。
- 次に以下のコマンドを実行する。
$ dvc repro
Stage 'data/Posts.xml.zip.dvc' didn't change.
Stage 'Posts.xml.dvc' didn't change.
Stage 'Posts.tsv.dvc' didn't change.
Stage 'Posts-test.tsv.dvc' didn't change.
Stage 'matrix-train.p.dvc' didn't change.
Stage 'model.p.dvc' didn't change.
Stage 'Dvcfile' didn't change.
dvc reproを引数なしで実行した場合は、Dvcfileの中身が実行されます。
次にスクリプトを変更してモデル作成を行ってみます。
モデルのチューニングをする
- モデルのチューニングのため、新しいブランチを作成し、モデル学習のスクリプトのパラメータを変更する。
$ git checkout -b tuning
$ vi code/train_model.py
train_model.pyの以下の箇所を変更する。
clf = RandomForestClassifier(n_estimators=700,
n_jobs=6, random_state=seed)
- 以下のコマンドを実行して、一連の処理の再現を行う。
$ dvc repro
Stage 'data/Posts.xml.zip.dvc' didn't change.
Stage 'Posts.xml.dvc' didn't change.
Stage 'Posts.tsv.dvc' didn't change.
Stage 'Posts-test.tsv.dvc' didn't change.
Stage 'matrix-train.p.dvc' didn't change.
Dependency 'code/train_model.py' of 'model.p.dvc' changed.
Stage 'model.p.dvc' changed.
Reproducing 'model.p.dvc'
Running command:
python code/train_model.py 20180319
Input matrix size (66999, 5002)
X matrix size (66999, 5000)
Y matrix size (66999,)
Saving 'data/model.p' to cache '.dvc/cache'.
Saving information to 'model.p.dvc'.
Dependency 'data/model.p' of 'Dvcfile' changed.
Stage 'Dvcfile' changed.
Reproducing 'Dvcfile'
Running command:
python code/evaluate.py
Saving 'data/eval.txt' to cache '.dvc/cache'.
Saving information to 'Dvcfile'.
dvc reproを実行すると以下の表示のように、code/train_model.pyのスクリプトが変更されたことを検出してモデル学習の処理からやり直してくれることがわかります。
Dependency 'code/train_model.py' of 'model.p.dvc' changed.
DVCのこの再現機能によって再度実行が必要な処理だけしてくれるので、無駄な計算を行わずに済むのは利点だと思います。
- チューニングしたモデルの精度を確認する。
$ cat data/eval.txt
AUC: 0.643155
モデルのパラメータをチューニングしたことにより、精度が上がりました。
AUC: 0.630725→AUC: 0.643155
- これまでの作業をコミットして、モデルのチューニングは完了。
$ git add .
$ git commit -m '700 trees in the forest'
データの共有(データセット、モデルファイルなど)
DVCはcacheのデータを共有するため、リモートのストレージにpushする機能があります。設定できるリモートのストレージの情報については、ドキュメントの以下に詳細に載っています。
https://dvc.org/doc/commands-reference/remote
リモートストレージには、AWS S3, Azure, GCP, SSHなどいろいろ設定できるので、使用場面に応じて選択でき、便利かと思います。
ローカルにもストレージが設定できるので今回はローカルで試してみます。
- 以下のコマンドでローカルにストレージを設定する。
$ dvc remote add -d myremote /home/user/work/dvc/dvc-storage
- cacheのデータをpushする。
$ dvc push
Preparing to push data to /home/user/work/dvc/dvc-storage
[##############################] 100% Collecting information
(1/9): [##############################] 100% data/eval.txt
(2/9): [##############################] 100% data/matrix-test.p
(3/9): [##############################] 100% data/Posts-test.tsv
(4/9): [##############################] 100% Posts.xml.zip
(5/9): [##############################] 100% data/matrix-train.p
(6/9): [##############################] 100% data/Posts-train.tsv
(7/9): [##############################] 100% data/Posts.tsv
(8/9): [##############################] 100% data/model.p
(9/9): [##############################] 100% data/Posts.xml
$ ls ~/work/dvc/dvc-storage
22 2c 30 3f 5f 72 ba c1 ec
pushすると、ストレージとして設定したディレクトリにデータが保存されていることが確認できます。今回はローカルのストレージで試しましたが、クラウドなどのサーバをリモートストレージとしてpushしてあげれば複数人とデータが共有できるようになります。
- 共有されたデータを取ってくるときはリモートストレージを設定してから、以下のようにpullを実行する。
$ dvc pull
DVCの一連の使い方の説明は以上です。
DVCを触って見た感想
- Gitに普段から慣れていればほとんどコマンドが似ているので覚えるのもそこまで負担にならないかと感じました。
- データセット、実行スクリプト、入出力ファイル、中間生成ファイルも含めてバージョン管理ができるので、DVCを活用するとデータ分析の再現性がより担保できそうです。