はじめに
マルチエージェントなど、AIと共にRAG(Retrieval-Augmented Generation)を本気でプロダクトに組み込むと、「ベクトル検索」だけで十分なシーンは多くありません。
実務ではしばしば、
- 日付(published_at,created_at,update_at...)
- カテゴリ(category)
- タグ / スコア / ユーザ属性 など
といった 構造化メタデータによる柔軟な絞り込み が必要になります。
上記のようなベクトル × 構造化メタデータ の組み合わせによる検索は一般的に 「ハイブリッド検索」と呼ばれます。
ACORNは、まさにこの「ハイブリッド検索」において、フィルタの選択性によって性能が大きく変動しにくい安定的な検索を実現するためのインデックス設計を提案しています。
本記事では、以下の項目について主に書いていきたいと思います。
- ACORNの概要
- ACORNを用いたRAGのアーキテクチャ例
- QdrantによるACORN活用のスキーマ & 実装例
- OpenSearchでACORNのハイブリッド検索を再現する方法
ACORNの概要
ACORNは、めちゃくちゃ分かりやすく言うと
「どんなフィルタ条件が来ても遅くなりにくいハイブリッド検索の方式」 です。
なぜそれが重要なのか?
まずは従来のハイブリッド検索が抱えていた問題から整理します。
どんな問題を解こうとしているか?
ハイブリッド検索では、クエリの要求が「ベクトル的に近い、かつ lang='ja' かつ 2024年以降 かつ category in ('攻略', 'レビュー')」のような形になります。
このような場合、従来はだいたい以下の2パターンが選択肢としてありました。
- pre-filter
→ RDB/検索エンジンでメタデータ条件を満たす行を先に絞り、そのsubsetに対してベクトル検索する - post-filter
→ まずベクトル検索で top-n を取り、その中をメタデータでフィルタする
しかし、predicate の選択性(どれくらい絞れるか)やカーディナリティ(メタデータの値の種類や散らばりの多さ)が変わると、どちらも簡単に死にます。
pre-filterは「ほとんど絞れない」場合にほぼ全件スキャン・post-filterは「条件を満たすベクトルが遠くに散らばっている」場合nを爆増させる必要があり、どちらも遅く&メモリを食いがちなのが課題です。
ACORNのアイデア
ACORNは、HNSW(graph-based ANN index)の上に predicate subgraph traversal という考え方を導入し、「任意の predicate(フィルタ条件)を満たすノードだけから構成されるサブグラフを、うまく辿れるように」インデックスを構築します。
ポイントは、グラフ全体を毎回再構築するのではなく、条件に応じたサブグラフを切り替えて探索する点です。そのため、どんなフィルタ条件が与えられても 探索経路が大きくぶれにくく、検索速度が安定しやすい、ということです。
ACORN の特徴を RAG 視点でまとめると:
- ベクトル+メタデータの ハイブリッド検索専用の HNSW 拡張インデックス
- フィルタ条件をあとから増やしても再構築不要(条件が変わっても遅くなりにくい)
- 実験では、従来手法より 2〜1000倍のスループット で同等のリコールを達成
公開実装は Faiss ベースの C++ ライブラリとして提供されています。
最近では Qdrant が ACORN をオプションとして統合し始めていて、HNSW グラフ探索でより多くのノードを辿るモードとして提供されています。
OpenSearchにおいては、3.1以降で「Faiss エンジン + HNSW を使う場合」において、「メモリ最適化検索 (memory-optimized search) が有効になっているとき」に限り、ACORNが有効になると書かれています。
一方で、一般的なベクトル検索できるDB は、
・knn + filter(前/中間フィルタ)
・hybrid(keyword + vector)+ filter
などを中心にサポートしており、「低〜中カーディナリティの条件」なら実用的ですが、ACORN のような条件に依存しないサブグラフ構築までは行っていない例も多いと思います。
ACORNを用いたRAGのアーキテクチャ例
ChatGPTでざっくりアーキテクチャ図を作ってみました。
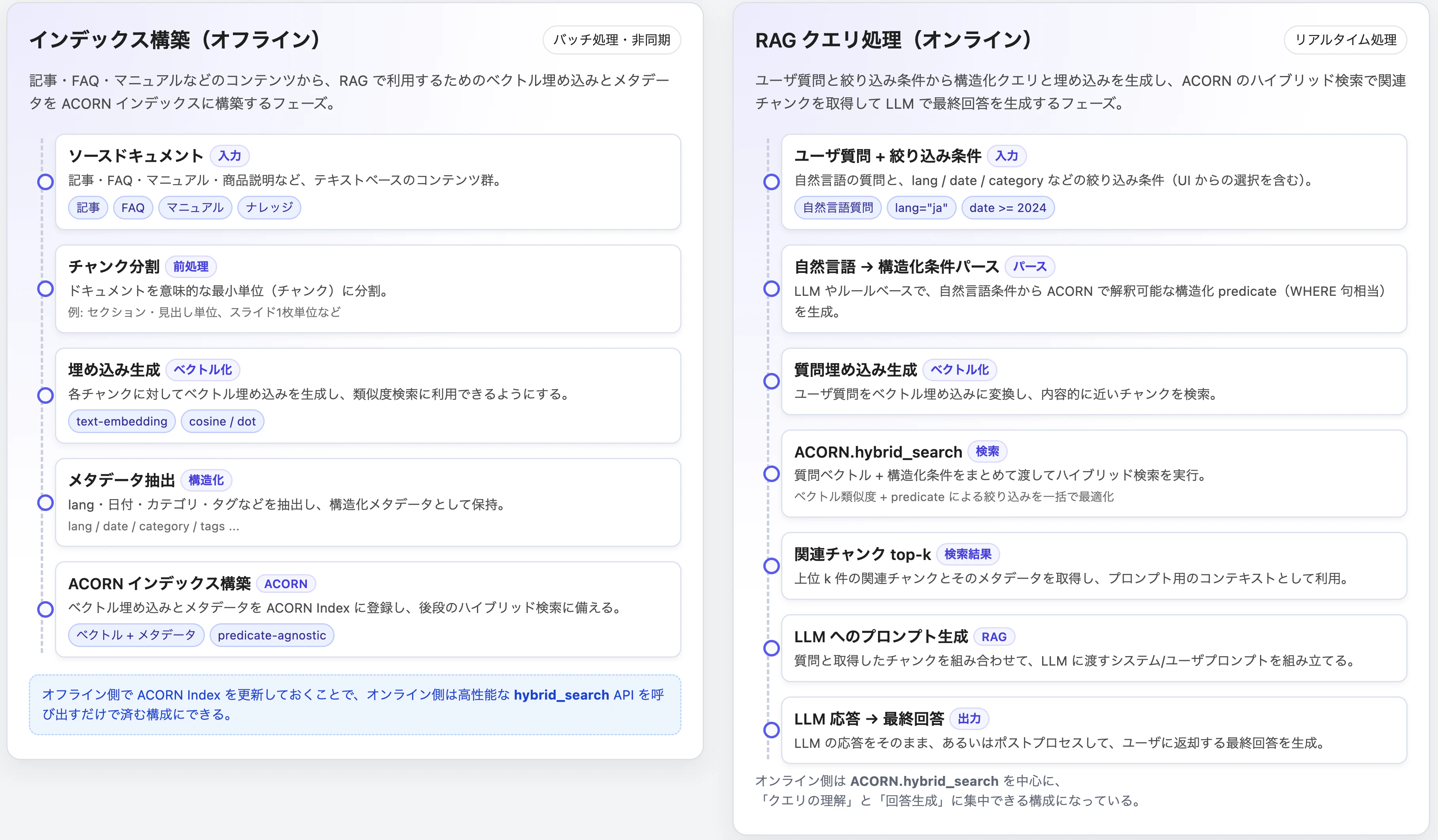
QdrantでACORNを利用するスキーマと実装例
QdrantでACORNインデックス構築する方法として、コレクションの最低限の定義の方法、ドキュメント追加例、実際のハイブリッド検索する際のクエリ発行の実装例を示します。※実装例はPythonを使っています。
コレクション定義(schema)
PUT /collections/rag_docs
{
"vectors": {
"size": 1536,
"distance": "Cosine"
},
"hnsw_config": {
"payload_m": 32,
"max_edges": 96,
"acorn": {
"enabled": true // ACORN をオン
}
},
"optimizers_config": {
"default_segment_number": 5
}
}
hnsw_configでacornを有効にするだけ
ドキュメント追加(埋め込み + メタデータ)
qdrant.upsert(
collection_name="rag_docs",
points=[
PointStruct(
id=uuid,
vector=embed(text),
payload={
"text": text,
"lang": "ja",
"published_at": "2024-11-01",
"category": "攻略",
"tags": ["原神", "ビルド"]
}
)
]
)
メタ系はpayloadに入れる
ハイブリッド検索(ACORN + predicate)
query_vector = embed(question)
res = qdrant.search(
collection_name="rag_docs",
query_vector=query_vector,
limit=10,
query_filter=Filter(
must=[
FieldCondition(key="lang", match=MatchValue(value="ja")),
FieldCondition(key="published_at", range=Range(gte="2024-01-01")),
FieldCondition(key="category", match=MatchAny(any=["攻略", "レビュー"]))
]
)
)
普通にquery_filterで使うだけ
OpenSearchでACORNのハイブリッド検索をする方法
OpenSearch 3.1 以降では、Faiss エンジン + HNSW を使った Efficient k-NN filtering において、Lucene の ACORN filtering optimization が内部的に利用されます。
ただし、論文の ACORN のように「明示的に ACORN インデックスを選ぶ」ことはできず、あくまで フィルタ付き k-NN 検索時に自動で最適化アルゴリズムが動く 形で提供されています。
ここでは、RAG 用のドキュメントインデックスを想定して、ACORN ベースの Efficient k-NN filtering を前提にした構成例を示します。
インデックスのマッピング例(Faiss + HNSW)
PUT rag-docs
{
"settings": {
"index": {
"knn": true
}
},
"mappings": {
"properties": {
"title": { "type": "text" },
"body": { "type": "text" },
"embedding": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"name": "hnsw",
"engine": "faiss",
"space_type": "cosinesimil"
}
},
"lang": { "type": "keyword" },
"published_at": { "type": "date" },
"category": { "type": "keyword" },
"tags": { "type": "keyword" }
}
}
}
Efficient k-NN filtering(ACORN ベース)を使った検索例
ACORN 最適化を効かせたい場合は、bool クエリの外側に k-NN を置くのではなく、
knn クエリの中に filter を埋め込む 形にします。
POST rag-docs/_search
{
"size": 10,
"query": {
"knn": {
"embedding": {
"vector": [ /* question embedding */ ],
"k": 50,
"filter": {
"bool": {
"must": [
{ "term": { "lang": "ja" } },
{ "range": { "published_at": { "gte": "2024-01-01" } } },
{ "terms": { "category": ["攻略", "レビュー"] } }
]
}
}
}
}
}
}
この形にしておくと、OpenSearch 側で:
フィルタを満たす候補だけを優先的に探索しつつ
フィルタによってグラフが疎になる場合は「neighbors of neighbors」まで辿る
フィルタの効き方(何%が落ちるか)に応じて探索の広がりを調整
といった ACORN ベースのフィルタリング最適化 が自動的に適用されます。
とはいえ「フル ACORN」ではない点:
-
OpenSearch からは ACORN 専用のインデックス型を選ぶことはできない(Lucene / Faiss の実装に組み込まれているだけ)
-
構造化フィルタの種類ごとに細かくインデックス設計を変えるような、論文レベルのチューニングは現状できない
-
極端に偏った分布や、複雑な構造化フィルタが重なりすぎるケースでは、依然としてレイテンシや負荷のチューニング余地は残る
とはいえ、「ベクトル + メタデータフィルタ」を単純な pre/post-filter でやるよりは、かなり ACORN らしい挙動に近づけられる ので、RAG 用のハイブリッド検索ではまずこの構成をベースラインにしておくのが扱いやすいと思います。
さいごに
最近の AI エージェント / マルチエージェント分野では、
- Agent A:最新ニュース抽出
- Agent B:ユーザ履歴を加味した推薦
- Agent C:過去会話 × 好み × 日付範囲 × コンテキストで検索
のように、検索に求められるフィルタ条件の複雑さと可変性が加速度的に増大してきています。
とくにエージェントは推論プロセスが長くなることも多く、レスポンス時間のばらつきはUXに直結するため、 従来の「ベクトル検索+メタデータ検索」だけでは性能要件を満たしづらくなってきています。
こうした状況においては、 ACORNのようなフィルタ選択性に依存しにくいハイブリッド検索のインデックス手法を採用することが、 性能・スケーラビリティの両面で有効な選択肢になり得ます。
ACORNはまだ発展途上ですが、 “ハイブリッド検索が当たり前になる未来(特にマルチエージェント時代)” を見据えた有力なアプローチであることは間違いありません。
もし
- 「ベクトル検索を導入したけど精度が伸びない」
- 「フィルタを組み合わせると検索速度が急に落ちる」
といった課題を抱えているなら、
ACORN + Qdrant or OpenSearchの組み合わせは試す価値のある選択肢です。
一度試してみてはいかがでしょうか?