この記事は 馬蹄分布(Horseshoe Distribution) について、基本となる事柄だけを簡単にまとめたものです。
Googleで馬蹄分布と検索するといくつかの解説記事がヒットしますが、どれもがしっかりとした内容を解説していて基本的な事柄について触れている記事を見つけることができませんでした。
この記事は筆者が馬蹄分布について調べた事柄をまとめたものになります。この記事を読むことで馬蹄分布をフワッと理解できるくらいのレベル感で執筆します。
どんな時に使われる?
馬蹄分布が用いられる文脈は様々ですが、代表的なものとしてはベイズ線形回帰の回帰係数に対する事前分布として用いられます。
次のような線形回帰モデルを考えます。
\mathbf{y}=\mathbf{X}\boldsymbol \beta + \boldsymbol \epsilon
\boldsymbol \epsilon\sim\mathbb{N}(\mathbf{0},\sigma^2\mathbf{I})
このとき、
y_i = \beta_1 x_{i1}+\beta_2 x_{i2} + \cdots +\beta_n x_{in} + \epsilon_i
における、回帰係数 $\beta_1, \beta_2, \cdots ,\beta_n$ がスパース(0が多いということ)であるとき、 $\beta_i$ の事前分布に対して馬蹄分布を設定することで、事前知識を用いたモデルを作ることができます。
一般的に説明変数が多くあるときや信号処理などでは、解はスパースとなる傾向があることが知られています。
馬蹄分布
馬蹄分布は次のような数式で記述されます。
\beta_i|\lambda_i,\tau\sim\mathbb{N}(0,\lambda_i^2\tau^2)
\lambda_i\sim C^+(0,1)
$C^+(0,1)$ は半コーシー分布です。半コーシー分布は次のような数式で記述され、その確率密度関数は次図のようになります。
\begin{split} \begin{align}
f(x;a, b) = \left\{\begin{array}{cll}
\frac{2}{\pi b}\,\frac{1}{1 + (x-a)^2/b^2} & & x \ge a \\[1em]
0 & & \text{otherwise}.
\end{array}\right.
\end{align}\end{split}
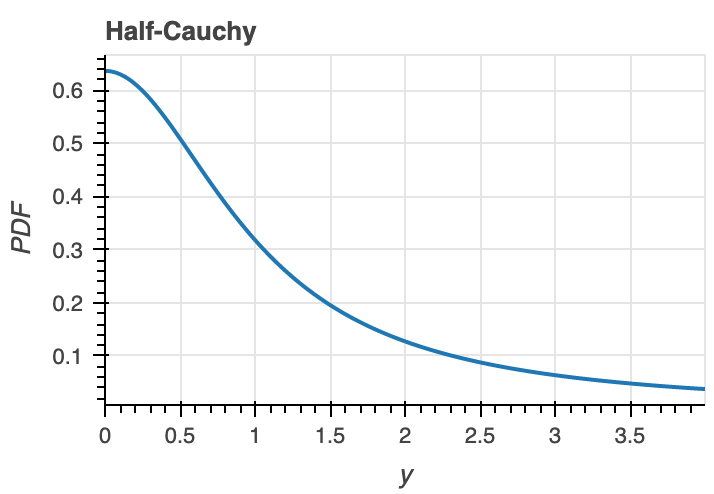
つまり馬蹄分布は、$\lambda_i$ が半コーシー分布から生成されているとき、平均 $0$ で分散 $\lambda_i^2\tau^2$ のガウス分布から生成されます。
馬蹄分布から10000個サンプリングした結果を次図に示します。馬蹄分布は分布がスパースであるときに用いられる分布なので、サンプリングの結果もほとんど0となっています。
いくつかのサンプルは0以外の値となっていますが、0のサンプル数と比べて極端に少ないためヒストグラムでは確認できません。

縮小係数
ここまで解説した上でまだ馬蹄分布の名前の由来となった次のような形をした分布が登場していません。
馬蹄分布と検索をすると一番最初に出てくるのがこのような図ですが、これは馬蹄分布の分布の形を表しているのではなく、 縮小係数(Shirinkage Factor) の分布の形を表しています。
(ちなみに馬蹄分布という名前は縮小係数の分布の形が馬の蹄の形に似ていることに由来しています。)

縮小係数は次式で定義されます。 $\lambda_i\sim C^+(0,1)$ なので $k_i\in[0,1]$ となります。
k=\frac{1}{1+\tau^2\lambda_i^2}
縮小係数 $k$ は確率変数である $\lambda_i$ を変数変換したものなので、その分布は次のように導出することができます。表記の都合上、半コーシー分布を $f(x)$ 、変数変換の式を $g(x)$ と記述します。
確率変数の変換公式を用います。
f(x)=\frac{2}{\pi(1+x^2)}
g(x)=\frac{1}{1+\tau^2x^2}
\begin{align}
f(y)&=f(g^{-1}(y))|\frac{d}{dy}g^{-1}(y)|\\
&=\frac{2}{\pi}\frac{1}{1+\frac{1-y}{\tau^2 y}}\frac{1}{\tau}\frac{1}{2y^2\sqrt{\frac{1-y}{y}}}\\
&=\frac{\tau}{\pi}\frac{1}{1-(1-\tau^2)y}(1-y)^{-\frac{1}{2}}y^{-\frac{1}{2}}
\end{align}
従って、縮小係数 $k$ の分布は
p(k)=\frac{\tau}{\pi}\frac{1}{1-(1-\tau^2)k}(1-k)^{-\frac{1}{2}}k^{-\frac{1}{2}}
となります。
特に $\tau=1$ のとき、 $k$ の分布はBeta分布と等しくなります。
p(k)=\frac{1}{\pi}(1-k)^{-\frac{1}{2}}k^{-\frac{1}{2}}=\textrm{Beta}(\frac{1}{2},\frac{1}{2})
$\tau=1$ のときのみ、Beta分布という比較的単純な分布からのサンプリングで事足りるため、下のコードのような簡潔なコードのみで記述できますが、一般の $\tau$ からサンプリングを行うにはMCMCなどのアルゴリズムが必要です。
$p(k)$ から100000個サンプリングした図が下に該当します。
beta = np.random.beta(0.5, 0.5, size=100000)
fig = plt.figure()
plt.title("Beta(0.5, 0.5)")
plt.hist(beta, bins=100)
fig.savefig("dist-k.png")
plt.close()
なぜ $k$ には縮小係数という名前がついているのでしょうか。
説明を簡単にするために次のようなモデルを考えます。
y_i=\beta_i+\epsilon
\epsilon\sim\mathbb{N}(0,1)
y_i|\beta_i,\epsilon\sim\mathbb{N}(\beta_i,1)
\beta_i\sim\mathbb{N}(0,\lambda_i^2)
\lambda_i\sim C^+(0,1)
このとき、 $y_i$ を観測したあとの $\beta_i$ の期待値は、ベイズの定理を用いることで
\begin{align}
\mathbb{E}(\beta_i|y_i,\lambda_i)&=\int \beta_i p(\beta|y_i,\lambda_i) d\beta_i\\
&=(\frac{\lambda_i^2}{1+\lambda_i^2})y_i+(\frac{1}{1+\lambda_i^2})0\\
&=(1-k_i)y_i
\end{align}
k_i=\frac{1}{1+\lambda_i^2}
となります。
したがって、縮小係数 $k_i$ は $y_i$ が観測されたときに、どの程度 $\beta_i$ が0に縮小されるかを表していると解釈できます。
実際に $\tau=1$ のときに馬蹄分布からサンプリングを行なってみます。
def horseshoe():
tau = 1.0
k = np.random.beta(0.5, 0.5, size=10000)
λ = np.sqrt(-1 + 1 / k) / tau
scale = (tau ** 2) * (λ ** 2)
samples = np.random.normal(0, scale)
return samples
samples = horseshoe()
fig = plt.figure()
plt.title("Horseshoe ditribution")
plt.hist(samples, bins=100)
fig.savefig("horseshoe.png")
plt.close()
$\tau$ の値を変えることは、 $\beta_i$ が従う正規分布の裾の広さに影響を与えることになるので、$\tau$ は 大域的縮小係数(Global Shrinkage Factor) と呼ばます。
また $\lambda_i$ はそれぞれの係数 $\beta_i$ が0に圧縮される割合に関与するので、 局所的縮小係数(Local Shrinkage Factor) と呼ばれます。
まとめ
馬蹄分布は確率変数がスパースであるという事前知識があるときに用いられる分布になっています。
馬蹄分布そのものは平均0のある分散の値を持った正規分布から生成されるものですが、縮小係数は $\tau=1$ のときにBeta分布から生成され、その形が馬の蹄に似ていることから馬蹄分布という名前がつきました。
今回の実験コードはGitHub上にあります。
参考
[1] 縮小事前分布によるベイズ的変数選択3: Horseshoe prior (馬蹄事前分布)とは
[2] CARLOS M. CARVALHO, O, NICHOLAS G. POLSON. The horseshoe estimator for sparse signal. 2010.
[3] Carlos M. Carvalho, Nicholas G. Polson, James G. Scott. Handling Sparsity via the Horseshoe. 2009.