📚 関連書籍
『モダンデータスタック時代の シン・要件定義 クラウド構築大全 ― DWHからCDP、そしてMA / AI連携へ』
クラウド時代の「要件定義」って、どうやって考えればいい?
Databricks・Snowflake・Salesforce・n8nなど、主要サービスを横断しながら“構築の全体像”をやさしく解説!
DWHからCDP、そしてMA/AI連携まで──現場で使える知識をこの一冊で。
AI活用と自動化の要件定義
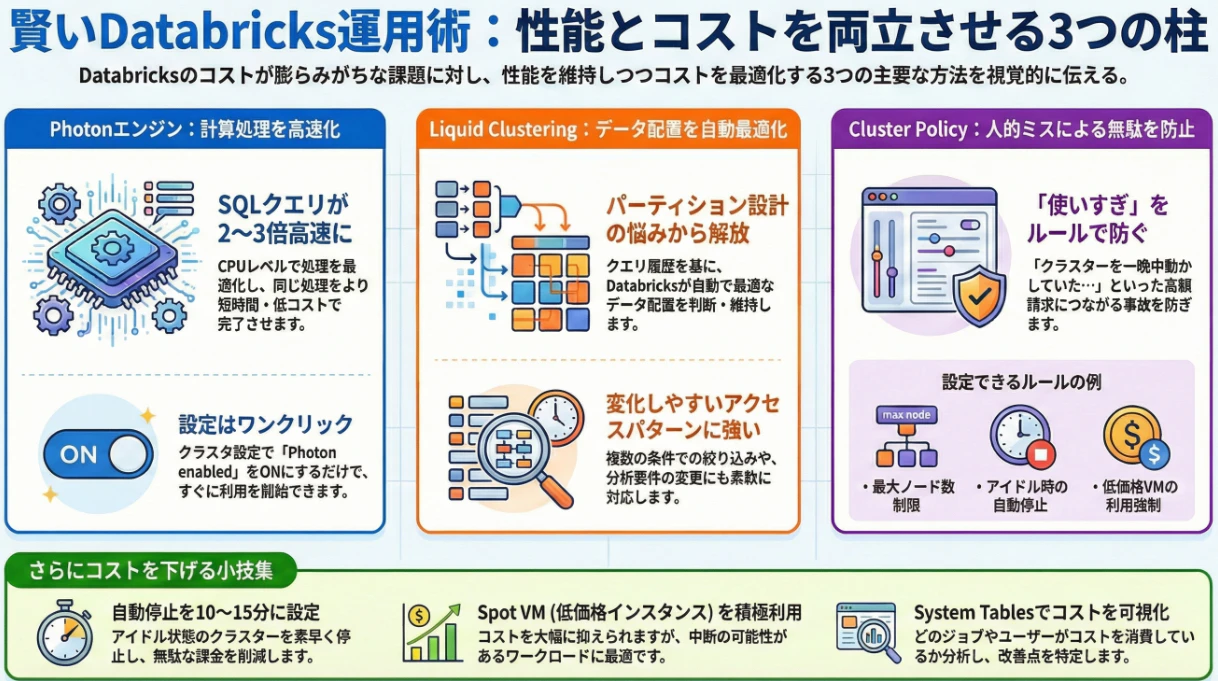
コスト最適化(Photon/ZORDER/Cluster Policy)
AI活用・自動化プロジェクトが長期的に失敗する最大の理由は、
「技術的には正しいが、コスト的に続かない」 という状態です。
・PoCでは問題なかった
・本番にした瞬間、請求額が跳ね上がる
・誰も止められず、最終的に使われなくなる
この原因の多くは、
コスト最適化を“運用”ではなく“要件”として定義していない
ことにあります。
本節では、
Photon/ZORDER/Cluster Policy を軸とした
コスト最適化の要件定義を整理します。
なぜコスト最適化は要件定義なのか? 🤔
Databricksのコストは、
「使った分だけ払う」モデルです。
つまり、
・誰が
・どんな処理を
・どれくらいの頻度で
実行できるかを決めていないと、
コストは必ず暴走します。
そのため、
- 速くする
- 安くする
ではなく
「どこまで許すか」を決めること
が要件定義の役割になります。
Photon ― “速さ=コスト削減”という前提を作る ⚡🚀
Photon は、
DatabricksのSQL/Delta処理を高速化する
ベクトル化実行エンジンです。
Photonを要件として定義する視点
-
対象ワークロード
・BIクエリ
・集計処理
・特徴量生成 -
効果指標
・実行時間短縮
・スキャン量削減 -
利用前提
・Photon対応Runtime -
使う理由の明文化
・速くするためではなく
コストを下げるため
Photonは
「高性能オプション」ではなく
“同じ処理を短時間で終わらせるためのコスト制御手段”
として要件に含めるべき存在です。
ZORDER ― スキャン量を減らすという設計思想 📦📉
ZORDERは、
Deltaテーブルのデータ配置を最適化し、
不要なデータ読み取りを減らす仕組みです。
ZORDERを要件として定義すべき理由
- クエリ性能は
・CPUより
・スキャン量に支配される - AI/BIでは
・同じキーで繰り返し参照される
要件として整理すべきポイント
- ZORDER対象カラム
・ID
・時刻
・セグメントキー - 実行タイミング
・日次/週次 - 対象レイヤ
・Silver
・Gold
ZORDERは
**「速くするための工夫」ではなく
「無駄に読まないための設計」**です。
Cluster Policy ― “勝手に使えない”を仕組みにする 🔒💸
Cluster Policyは、
Databricks利用コストを制御する
最重要ガバナンス機能です。
Cluster Policyで定義すべき要件
- インスタンスタイプ制限
- 最大ノード数
- Auto Termination
- Photon有効/無効
-
利用目的別ポリシー
・開発
・AI学習
・本番推論
これを定義しないと、
・誰でも最大構成
・放置クラスター
・意図しない高額請求
が必ず発生します。
Cluster Policyは、
コストを人に委ねず、仕組みで抑えるための要件
です。
AI活用視点でのコスト最適化 🤖📊
AI活用では特に、
以下のコストが増えがちです。
・学習の再実行
・特徴量生成
・推論バッチ
・品質チェック
だからこそ、
- Photonで処理時間短縮
- ZORDERでスキャン量削減
- Cluster Policyで暴走防止
という 三層防御 を
最初から要件として組み込みます。
よくある失敗パターン 🚨
・PoC用設定のまま本番
・高速化=高コストだと誤解
・Cluster Policyが未設定
・誰もコストを見ていない
これらはすべて、
コスト最適化を後付けにした結果です。
まとめ
- Photon:処理時間短縮=コスト削減
- ZORDER:スキャン量を減らす設計
- Cluster Policy:使いすぎを仕組みで防止
AI活用におけるシン・要件定義力とは、
「どれだけ使えるか」ではなく
「どこまで使っていいか」を決める力です。
この設計ができていれば、
AIと自動化は
長く・安全に・現実的なコストで使い続けられる基盤
になります。
📚 関連書籍
Databricks/n8n/Salesforce/AI基盤 を体系的に学べる「ゼロから触ってわかった!」シリーズをまとめました。
MCP
『ゼロから触ってわかった!MCPビギナーズガイド』 ― AIエージェント時代の次世代プロトコル入門 アーキテクチャ・ガバナンス・実装―
MCPというプロトコルは、単なる技術トレンドではなく
「AIとシステムの関係性」そのものを変える可能性を秘めています。
SaaS、AIエージェント、ガバナンス、アーキテクチャ。
その交差点を一度、立ち止まって整理した一冊です。
👉 https://amzn.to/3LcAjgg
Snowflake
ゼロから触ってわかった!Snowflake非公式ガイド ― 基礎から理解するアーキテクチャとCortexによる次世代AI基盤
「結局、DatabricksとSnowflakeは何が違うの?」
一見シンプルですが、機能表を比べるだけでは見えてこない深い問いです。 本書ではこの疑問を軸に、Snowflakeの思想・アーキテクチャ・設計思想を紐解いていきます。「違い」を知ることは、すなわち「現代のデータ基盤の本質」を知ることだからです。
初めてSnowflakeに触れる方には「最初の一冊」として。 なんとなく使っているけれどモヤモヤしている方には「頭の中を整理する一冊」として。 AI時代のエンジニアを目指すための、確かな燃料となる一冊です。
『ゼロから触ってわかった! Snowflake × Databricksでつくる次世代データ基盤 - 比較・共存・連携 非公式ガイド』
SnowflakeとDatabricks――二つのクラウドデータ基盤は、これまで「どちらを選ぶか」で語られることが多くありました。
しかし、実際の現場では「どう共存させるか」「どう連携させるか」が、より重要なテーマになりつつあります。
本書は、両プラットフォームをゼロから触り、構築・運用してきた実体験をもとに、比較・共存・連携のリアルを丁寧に解説する“非公式ガイド”です。
『ゼロから触ってわかった!スペック駆動開発入門 ― SaaS is dead?AI時代のソフトウェア設計論』
本書は、近年現場や技術コミュニティで注目を集め始めた**スペック駆動開発(Spec Driven Development:SDD)**を軸に、
AI時代のソフトウェア設計がどこへ向かおうとしているのかを解き明かします。
なぜ今「コード」でも「GUI設定」でも足りなくなってきたのか。
なぜ業務の意図や判断を、実装の外に出す必要があるのか。
前半では思想や背景を丁寧に整理し、後半ではスペック・実装・実行の三層モデルをサンプルコードとともに具体化します。
Databricks
『Databricks──ゼロから触ってわかった!Databricks非公式ガイド』
クラウド時代の分析基盤を “体験的” に学べるベストセラー入門書。
Databricksの操作、SQL/DataFrame、Delta Lakeの基本、ノートブック操作などを
初心者でも迷わず進められる構成で解説しています。
https://amzn.to/4pzlCCT
『ゼロから触ってわかった!Azure × Databricksでつくる次世代データ基盤 非公式ガイド ―』
クラウドでデータ基盤を作ろうとすると、Azure・Storage・ネットワーク・権限・セキュリティ…そこに Databricks が加わった瞬間、一気に難易度が跳ね上がります。
「結局どこから理解すればいいの?」
「Private Link むずかしすぎない?」
「Unity Catalog って実務ではどう扱うの?」
——そんな “最初のつまづき” を丁寧にほどいていくのが本書です。
👉 https://amzn.to/4ocWcJI
「ゼロから触ってわかった!Databricks × Airbyte」
クラウド時代のデータ基盤を“なぜ難しいのか”から丁寧にほどくガイドが完成しました。
Ingestion / LakeFlow / DLT / CDC をやさしく体系化し、
Airbyte × Databricks の真価を引き出す設計思想まで詰め込んだ一冊です。
『Databricks──ゼロから触ってわかった!DatabricksとConfluent(Kafka)連携!非公式ガイド』
Kafkaによるストリーム処理とDatabricksを統合し、リアルタイム分析基盤を構築するハンズオン形式の一冊。
イベント駆動アーキテクチャ、リアルタイムETL、Delta Live Tables連携など、
モダンなデータ基盤の必須スキルがまとめられています。
『Databricks──ゼロから触ってわかった!AI・機械学習エンジニア基礎 非公式ガイド』
Databricksでの プロンプト設計・RAG構築・モデル管理・ガバナンス を扱うAIエンジニアの入門決定版。
生成AIとデータエンジニアリングの橋渡しに必要な“実務の型”を体系化しています。
資格本ではなく、実務基盤としてAIを運用する力 を育てる内容です。
🧠 Advancedシリーズ(上/中/下)
Databricksを “設計・運用する” ための完全版実践書
「ゼロから触ってわかった!Databricks非公式ガイド」の続編として誕生した Advancedシリーズ は、
Databricksを触って慣れた“その先”――本格運用・チーム開発・資格対策・再現性ある設計 に踏み込む構成です。
Databricks Certified Data Engineer Professional(2025年9月改訂版)のカリキュラムをベースに、
設計思考・ガバナンス・コスト最適化・トラブルシュートなど、実務で必須の力を養えます。
📘 [上]開発・デプロイ・品質保証編
📘 [中]取込・変換・監視・コスト最適化編
📘 [下]セキュリティ・ガバナンス・トラブルシュート・最適化戦略編
n8n
『n8n──ゼロから触ってわかった!AIワークフロー自動化!非公式ガイド』
オープンソースの自動化ツール n8n を “ゼロから手を動かして” 学べる実践ガイド。
プログラミングが苦手な方でも取り組めるよう、画面操作中心のステップ構成で、
業務自動化・AI連携・API統合の基礎がしっかり身につきます。
Salesforce
『ゼロから触ってわかった!Salesforce AgentForce + Data Cloud 非公式ガイド』
Salesforceの最新AI基盤 AgentForce と Data Cloud を、実際の操作を通じて理解できる解説書。
エージェント設計、トピック/アクション構築、プロンプトビルダー、RAG(検索拡張生成)など、
2025年以降のAI×CRMのハンズオン知識をまとめた一冊です。
要件定義(上流工程/モダンデータスタック)
『モダンデータスタック時代の シン・要件定義 クラウド構築大全 ― DWHからCDP、そしてMA / AI連携へ』
クラウド時代の「要件定義」って、どうやって考えればいい?
Databricks・Snowflake・Salesforce・n8nなど、主要サービスを横断しながら“構築の全体像”をやさしく解説!
DWHからCDP、そしてMA/AI連携まで──現場で使える知識をこの一冊で。
💡 まとめ:このラインナップで“構築者の視点”が身につく
これらの書籍を通じて、
クラウド基盤の理解 → 要件定義 → 分析基盤構築 → 自動化 → AI統合 → 運用最適化
までのモダンデータスタック時代のソリューションアーキテクトとしての全体像を
「体系的」かつ「実践的」に身につけることができます。
- PoC要件整理
- データ基盤の要件定義
- チーム開発/ガバナンス
- AIワークフロー構築
- トラブルシュート
など、現場で直面しがちな課題を解決する知識としても活用できます。