『Databricks──ゼロから触ってわかった!Databricks非公式ガイド(2026年更新版)』
クラウド時代の分析基盤を “体験的” に学べるベストセラー入門書。
Databricksの操作、SQL/DataFrame、Delta Lakeの基本、ノートブック操作、SDP(宣言型パイプライン)
Serverless、Genieなどを初心者でも迷わず進められる構成で解説しています。
https://amzn.to/4uIqEj4
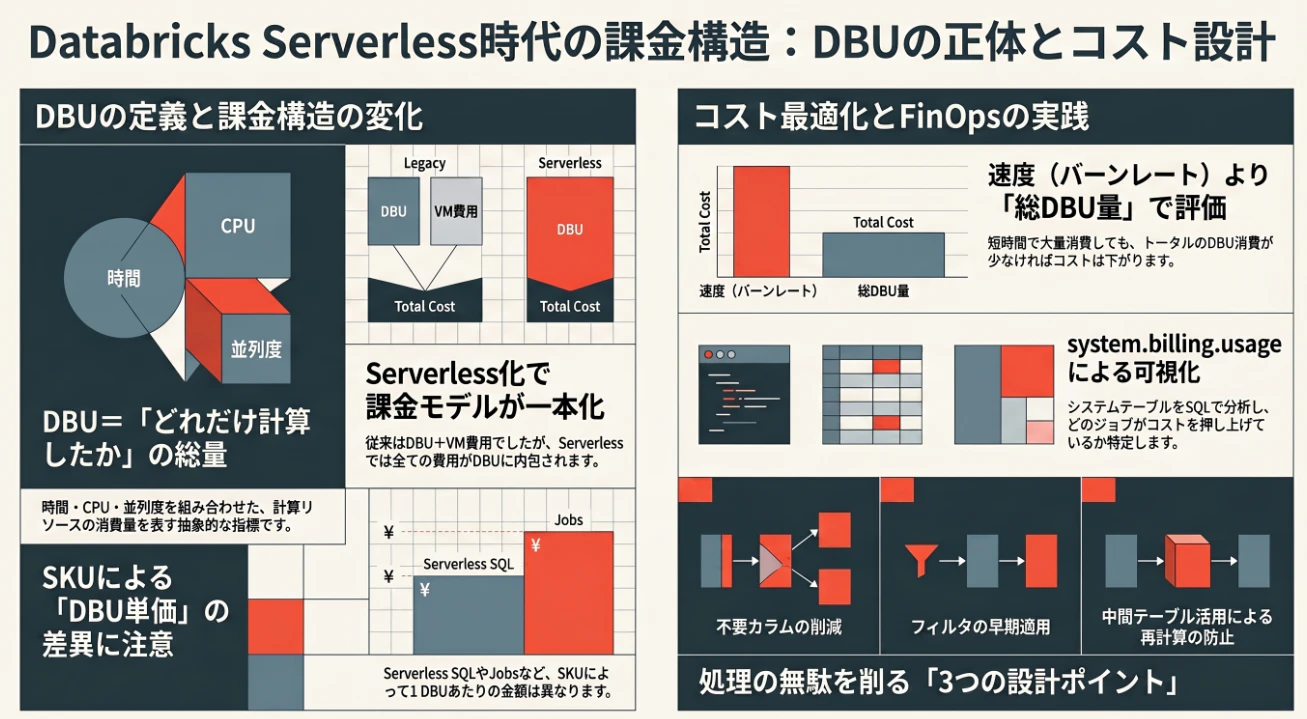
DBUの正体 ― Serverless時代の課金構造と落とし穴 ―
Databricksのコストを理解するうえで、避けて通れないのが DBU です。
DBUは、Databricksにおける課金の基本単位です。
ただし、最初は少し分かりにくい概念でもあります。
なぜならDBUは、
時間そのものでもなく、CPUそのものでもない
からです。
DBUとは一言で言えば、
処理に使った計算リソース量を抽象化した指標
です。
つまり、
- どれくらい重い処理をしたか
- どれくらい並列に処理したか
- どれくらい長く実行したか
をまとめて表す単位です。
Serverless時代のDatabricksでは、このDBUを正しく理解することが、性能設計だけでなくコスト設計にも直結します。
DBUとは何か
DBUは、Databricks Unitの略です。
Databricks上で処理を実行すると、その処理に応じてDBUが消費されます。
基本的な考え方はシンプルです。
どれだけ計算したか = DBU
です。
たとえば、
- 処理が重いほどDBUは増える
- 並列度が高いほどDBUは増える
- 実行時間が長いほどDBUは増える
という関係になります。
ここで重要なのは、DBUを単なる「時間課金」として見ないことです。
同じ10分の処理でも、利用するComputeの種類や処理内容によって消費DBUは変わります。
そのため、DBUは
処理時間と計算リソースを組み合わせた消費量
と理解すると分かりやすくなります。
Serverless時代の課金構造
従来のClassic環境では、Databricksのコストは大きく2つに分かれていました。
- DatabricksのDBU費用
- クラウド側のVM費用
つまり、
Databricks利用料
インフラ利用料
が分離されていたわけです。
AzureであればAzure VM、AWSであればEC2の費用が別途発生します。
そのため、実際のコストを見るには、Databricks側とクラウド側の両方を確認する必要がありました。
一方でServerlessでは、この構造が大きく変わります。
Serverlessでは、計算リソースの費用がDBU側に含まれる形になります。
つまり、
- VMを個別に意識しない
- クラスタ構成を細かく管理しない
- Databricks側の利用量として把握しやすい
という課金構造になります。
これは単なる簡略化ではありません。
コストの見方そのものが変わった
ということです。
Serverless化によるメリット
Serverless化による大きなメリットは、コスト把握がしやすくなることです。
従来は、
- Databricks側のDBU
- クラウド側のVM費用
- アイドル時間
- クラスタ起動時間
- オートスケールの挙動
を組み合わせて考える必要がありました。
しかしServerlessでは、利用した処理単位でコストを見やすくなります。
特にFinOpsの観点では、
どの処理が、どれだけ使い、いくらかかったのか
を追いやすくなります。
これは本番運用では非常に大きなメリットです。
SKUの違いに注意する
DBUを理解するうえで、非常に重要な注意点があります。
それは、
同じ1 DBUでも、単価は同じではない
という点です。
Databricksには複数のSKUがあります。
たとえば、
- Serverless SQL
- Serverless Jobs
- Classic Jobs
- All-Purpose Compute
- Model Serving
などです。
これらはDBUで表現されますが、1 DBUあたりの単価は異なります。
特にServerlessは、
- アイドルコストがない
- 起動が速い
- インフラ管理が不要
- スケーリングが自動
という価値を含んでいるため、1 DBUあたりの単価が高めに設定されることがあります。
つまり、
DBU消費量だけ見ても、本当のコストは分からない
のです。
必ずSKU単価まで含めて評価する必要があります。
落とし穴:速い = 安いとは限らない
ServerlessとPhotonを使うと、処理は非常に速くなります。
しかし、ここで注意が必要です。
速く終わるからといって、必ず安いとは限りません。
なぜなら、短時間で大量のリソースを使う場合があるからです。
これが、
DBUバーンレート
の考え方です。
バーンレートとは、単位時間あたりにどれだけDBUを消費しているかを表す考え方です。
たとえば、
- 高速だが瞬間的に多くのDBUを使う処理
- 遅いが少しずつDBUを使う処理
があります。
ここで重要なのは、
速度と総コストは別物
ということです。
短時間で大量消費しても、総DBUが少なければ安く済む場合があります。
逆に、低速で長時間動く処理は、結果的に高くなることもあります。
そのため、瞬間的な消費量だけで判断してはいけません。
必ず、
総DBU
SKU単価
処理結果
をセットで見る必要があります。
落とし穴:見えないコストは制御できない
Serverlessでは、インフラが見えなくなります。
これは大きなメリットです。
しかし同時に、コストが見えにくくなるリスクもあります。
たとえば、
- どのジョブが高コストなのか
- どのSQLがDBUを多く使っているのか
- どの処理が頻繁に実行されているのか
- どのSKUで課金されているのか
が分からなければ、改善はできません。
そこで重要になるのが、systemテーブルによる可視化です。
Databricksでは、利用量をSQLで確認できます。
SELECT
usage_date,
sku_name,
job_id,
usage_quantity AS dbu,
usage_cost
FROM system.billing.usage
WHERE usage_date >= current_date - INTERVAL 7 DAY
ORDER BY usage_cost DESC
このように確認することで、
- どの日に
- どのSKUで
- どのジョブが
- どれだけDBUを使い
- いくらかかったのか
を把握できます。
これがDatabricksにおけるFinOpsの第一歩です。
コスト最適化の本質
従来のクラスタ環境では、コスト削減というとリソース削減が中心でした。
たとえば、
- インスタンスサイズを小さくする
- ノード数を減らす
- クラスタを早く停止する
といった考え方です。
しかしServerless時代では、少し発想を変える必要があります。
Serverlessでは、個別のVMを細かく調整するよりも、
何を計算するか
が重要になります。
具体的には、
- 不要な処理を減らす
- 読み込むデータ量を減らす
- 再計算を減らす
- 重いJOINを見直す
- 中間結果を再利用する
といった設計が重要です。
つまり、Serverless時代のコスト最適化とは、
リソース削減ではなく、計算量削減
です。
実務で効く3つの最適化ポイント
Databricksのコスト最適化で、実務上効果が出やすいポイントは大きく3つあります。
不要カラムの削減
まず重要なのが、読み込むカラムを減らすことです。
SELECT * を多用すると、不要なカラムまで読み込んでしまいます。
その結果、Scan量が増え、DBU消費も増えます。
必要なカラムだけを取得することで、処理量を削減できます。
フィルタの早期適用
次に重要なのが、フィルタをできるだけ早い段階で適用することです。
データ量を早い段階で絞り込めば、その後のJOINや集計の負荷も下がります。
これは性能改善だけでなく、コスト削減にも直結します。
再計算の削減
同じ処理を何度も実行している場合は、中間テーブルやキャッシュの活用を検討します。
特に重い集計や変換処理は、毎回再計算するとDBUを消費します。
必要に応じて結果を再利用することで、無駄な計算を減らせます。
FinOpsの視点
Databricksのコストは、実行後に初めて決まるものではありません。
実際には、設計段階でほぼ決まります。
たとえば、
- どの処理を実行するか
- どの頻度で回すか
- どの粒度でデータを扱うか
- どこまでリアルタイム性を求めるか
- どのデータを再利用するか
これらの選択が、そのままコストになります。
つまり、
コストは結果ではなく設計で決まる
ということです。
FinOpsとは、利用後に請求額を眺めることではありません。
設計段階からコストを意識し、利用状況を可視化し、継続的に改善する活動です。
Serverless時代のコスト管理
Serverless時代には、インフラの細かな管理負荷は下がります。
しかし、コスト管理が不要になるわけではありません。
むしろ、
見えないからこそ可視化が重要
になります。
本番環境では、少なくとも次のような仕組みを用意すべきです。
- ジョブ別DBU使用量の可視化
- SKU別コストの集計
- 日次・週次・月次の推移確認
- 異常なコスト増加の検知
- チーム別・プロジェクト別のコスト配賦
これらを整えることで、Databricksの利用を健全にスケールできます。
よくある誤解
DBUに関して、実務でよくある誤解も整理しておきます。
DBUが少なければ必ず安い
DBUが少なくても、SKU単価が高ければコストは高くなる可能性があります。
DBU量だけでなく、単価を含めて見る必要があります。
Serverlessは必ず高い
Serverlessは1DBU単価が高めに見える場合があります。
しかし、アイドルコストがなく、起動が速く、管理負荷も下がるため、総コストでは有利になるケースもあります。
速ければ必ず安い
速い処理でも、大量のリソースを一気に使えばコストが高くなる可能性があります。
評価すべきは処理時間だけではなく、総DBUと総コストです。
まとめると
DBUは一見すると分かりにくい指標です。
しかし、本質を理解すると、Databricksのコストを読み解くための非常に重要な手がかりになります。
要点を整理すると、
- DBUは計算リソース消費量を抽象化した指標
- 時間やCPUそのものではなく、計算量の総量として見る
- ServerlessではDBUに計算リソース費用が含まれる
- SKUによって1 DBUあたりの単価は異なる
- 速い処理が必ず安いとは限らない
- バーンレートと総DBUを分けて考える
- systemテーブルで利用量を可視化する
- コスト最適化の本質は計算量を減らすこと
- FinOpsは設計段階から始まる
Serverless時代において、インフラは見えにくくなりました。
しかし、コストが消えたわけではありません。
むしろ、
見えないからこそ、設計で制御する
ことが重要になります。
DBUを正しく理解できれば、Databricksのコストは怖いものではありません。
可視化し、分解し、設計でコントロールする。
これがDatabricksにおけるFinOpsの本質です。
📚 関連書籍
※この記事は書籍の一部をベースに再構成しています。もう少し踏み込んだ内容(設計や具体例)は
書籍の中でまとめているので、気になる方はそちらもどうぞ。
Databricks/Snowflake/n8n/Salesforce/AI基盤e/POC/要件定義の進め方 を体系的に学べる
「ゼロから触ってわかった!」シリーズをまとめました。
『ゼロから触ってわかった! Databricks 本番導入完全ガイド(非公式) ― Serverless・Lakeflow・AI時代のデータ基盤実践 ― 』
『Databricks──ゼロから触ってわかった!Databricks非公式ガイド(2026年更新版)』
クラウド時代の分析基盤を “体験的” に学べるベストセラー入門書。
Databricksの操作、SQL/DataFrame、Delta Lakeの基本、ノートブック操作、SDP(宣言型パイプライン)
Serverless、Genieなどを初心者でも迷わず進められる構成で解説しています。
https://amzn.to/4uIqEj4
『ゼロから触ってわかった! Snowflake × Databricks次世代データ基盤PoC実践 非公式ガイド』
本書を読み終えたとき、「POCって何から始めればよいのか」が明確になり、「自分たちにもできる」という確信を持てることを目指しています。
https://amzn.to/43qI0oR
『ゼロから触ってわかった! Snowflake × Databricksでつくる次世代データ基盤 - 比較・共存・連携 非公式ガイド』
SnowflakeとDatabricks――二つのクラウドデータ基盤は、これまで「どちらを選ぶか」で語られることが多くありました。本書は、両プラットフォームをゼロから触り、構築・運用してきた実体験をもとに、比較・共存・連携のリアルを丁寧に解説する“非公式ガイド”です。
https://amzn.to/4efDkIk
Snowflake
ゼロから触ってわかった!Snowflake非公式ガイド ― 基礎から理解するアーキテクチャとCortexによる次世代AI基盤
初めてSnowflakeに触れる方には「最初の一冊」として。
なんとなく使っているけれどモヤモヤしている方には「頭の中を整理する一冊」として。
AI時代のエンジニアを目指すための、確かな燃料となる一冊です。
https://amzn.to/4x1VvZm
「ゼロから触ってわかった!Codex - AIエージェント時代のソフトウェア設計」
本書は、AIエージェントと共に開発する時代において、エンジニアが思考停止せず、主体的に価値を発揮し続けるための指針を提示します。
ツールの使い方ではなく、これからの開発の本質を理解したいすべてのエンジニアへ。
https://amzn.to/4o0repH
「ゼロから触ってわかった! Claude Code × ChatGPT × Gemini AI共生戦略 -“対立”ではなく“共生”する時代へ」
Claude Code × ChatGPT × Geminiという共生モデルを解説します。
https://amzn.to/4a2dJjC
『ゼロから触ってわかった!スペック駆動開発入門 ― SaaS is dead?AI時代のソフトウェア設計論』
前半では思想や背景を丁寧に整理し、後半ではスペック・実装・実行の三層モデルをサンプルコードとともに具体化します。
https://amzn.to/3RFEZya
Databricks
『ゼロから触ってわかった!Azure × Databricksでつくる次世代データ基盤 非公式ガイド ―』
クラウドでデータ基盤を作ろうとすると、Azure・Storage・ネットワーク・権限・セキュリティ…
そこに Databricks が加わった瞬間、一気に難易度が跳ね上がります。 “最初のつまづき” を丁寧にほどいていくのが本書です。
https://amzn.to/3QaOzbW
『Databricks──ゼロから触ってわかった!AI・機械学習エンジニア基礎 非公式ガイド』
Databricksでの プロンプト設計・RAG構築・モデル管理・ガバナンス を扱うAIエンジニアの入門決定版。
生成AIとデータエンジニアリングの橋渡しに必要な“実務の型”を体系化しています。
資格本ではなく、実務基盤としてAIを運用する力 を育てる内容です。
https://amzn.to/3PYK4ku
『Databricks認定データエンジニアプロフェッショナル 試験レベル ― 1日3分!気になったところから読めるデータブリックス!魂の100本ノック!』
本書は、Databricks認定データエンジニア・プロフェッショナル相当の論点を、
100個のユースケースに分解し、**“2択の検討”→“解説コラム”→“結論”**でテンポよく叩き込む「魂の100本ノック」です。
暗記ではなく、現場で遭遇する判断ポイント(取り込み・変換・品質・共有・監視・性能/コスト・セキュリティ・ガバナンス・デプロイ・モデリング)を、短い読書時間で反復できるように整えました。
https://amzn.to/4vkLm8K
https://amzn.to/4fhNBF5
Databricks Advancedシリーズ(上/中/下)
Databricksを “設計・運用する” ための完全版実践書
「ゼロから触ってわかった!Databricks非公式ガイド」の続編として誕生した Advancedシリーズ は、
Databricksを触って慣れた“その先”――本格運用・チーム開発・資格対策・再現性ある設計 に踏み込む構成です。
📘 [上]開発・デプロイ・品質保証編
https://amzn.to/4dGQoGv
📘 [中]取込・変換・監視・コスト最適化編
https://amzn.to/49zbPHb
📘 [下]セキュリティ・ガバナンス・トラブルシュート・最適化戦略編
https://amzn.to/4efDkIk
「ゼロから触ってわかった!Databricks × Airbyte」
クラウド時代のデータ基盤を“なぜ難しいのか”から丁寧にほどくガイドが完成しました。
Ingestion / LakeFlow / DLT / CDC をやさしく体系化し、
Airbyte × Databricks の真価を引き出す設計思想まで詰め込んだ一冊です。
https://amzn.to/3XOlV0t
『Databricks──ゼロから触ってわかった!DatabricksとConfluent(Kafka)連携!非公式ガイド』
Kafkaによるストリーム処理とDatabricksを統合し、リアルタイム分析基盤を構築するハンズオン形式の一冊。
イベント駆動アーキテクチャ、リアルタイムETL、Delta Live Tables連携など、
モダンなデータ基盤の必須スキルがまとめられています。
https://amzn.to/42HdmqZ
Salesforce
『ゼロから触ってわかった!Salesforce AgentForce + Data360(Data 非公式ガイド』
Salesforceの最新AI基盤 AgentForce と Data360(Data Cloud) を、実際の操作を通じて理解できる解説書。
https://amzn.to/4u4PyZ2
要件定義(上流工程/モダンデータスタック)
『モダンデータスタック時代の シン・要件定義 クラウド構築大全 ― DWHからCDP、そしてMA / AI連携へ』
クラウド時代の「要件定義」って、どうやって考えればいい?
Databricks・Snowflake・Salesforce・n8nなど、主要サービスを横断しながら“構築の全体像”をやさしく解説!
DWHからCDP、そしてMA/AI連携まで──現場で使える知識をこの一冊で。
https://amzn.to/4nZm0ux
データメッシュ
####『ゼロから触ってわかった データメッシュ入門 ― 思想・型・組織構造から考えるデータメッシュ』
「Data Mesh を導入すべきかどうか」を断言する本ではありません。
自分たちにとって、どこまで分散し、何を共有し、どこに責任を置くのか。
その判断をするための思考の土台を整理する一冊です。
https://amzn.to/3REkyBS
データクリーンルーム
ゼロから触ってわかった データクリーンルーム実践入門 ~ Lakehouse時代のクリーンルームを、思想・設計・マネタイズで読み解く ~
データはあるのに、渡せない。それでも一緒に分析したい——そんな現場の悩みから、本書は始まります。
データクリーンルームを「難しい技術」ではなく、現実の業務でどう使い、どう続けるかという視点で整理しました。
非ITのビジネスパーソンにも読める、実践的な一冊です。
https://amzn.to/4fiG6O2
MCP
『ゼロから触ってわかった!MCPビギナーズガイド』 ― AIエージェント時代の次世代プロトコル入門 アーキテクチャ・ガバナンス・実装―
MCPというプロトコルは、単なる技術トレンドではなく
「AIとシステムの関係性」そのものを変える可能性を秘めています。
SaaS、AIエージェント、ガバナンス、アーキテクチャ、その交差点を一度、立ち止まって整理した一冊です。
https://amzn.to/4nZm0ux
n8n
『n8n──ゼロから触ってわかった!AIワークフロー自動化!非公式ガイド』
オープンソースの自動化ツール n8n を “ゼロから手を動かして” 学べる実践ガイド。
プログラミングが苦手な方でも取り組めるよう、画面操作中心のステップ構成で、
業務自動化・AI連携・API統合の基礎がしっかり身につきます。
👉 https://amzn.to/48Blxca
💡 まとめ:このラインナップで“構築者の視点”が身につく
これらの書籍を通じて、
クラウド基盤の理解 → 要件定義 → 分析基盤構築 → 自動化 → AI統合 → 運用最適化
までのモダンデータスタック時代のソリューションアーキテクトとしての全体像を
「体系的」かつ「実践的」に身につけることができます。
- PoC要件整理
- データ基盤の要件定義
- チーム開発/ガバナンス
- AIワークフロー構築
- トラブルシュート
など、現場で直面しがちな課題を解決する知識としても活用できます。