はじめに
AWS re:Invent 2024に現地参加しました。
前回投稿からまた間が空いてしまいましたが、引き続き参加したセッションの感想や現地の熱気などを私なりにレポートしていきたいと思います。5回に渡るレポート記事も今回で終わりです。
前回の記事はこちら。
今回は5日目最終日の内容と全体のまとめをお届けします。
5日目:12/6(金)
5日目に参加した主なセッションやアクティビティは次の通りです。
5日目はお昼までにすべてのセッションやイベントが終了するのでボリュームは少なめです。
- STG353-NEW | [NEW LAUNCH] Accelerate data discovery with Amazon S3 Metadata
- STG403-R1 | Safeguard and audit data protection with AWS Backup [REPEAT]
- ACT130 | Ride the slide (sponsored by Datadog)
それぞれ取り上げていきます。
STG353-NEW | [NEW LAUNCH] Accelerate data discovery with Amazon S3 Metadata
セッション名に"[NEW LAUNCH]"とついている通り、セッション予約開始以後に追加されたセッションです。このようなセッションは、re:Invent会期中に発表される新サービス・機能を取り上げる内容が多いです。
re:Invent直前の週に正式なセッション名や詳細は伏せられたまま、カタログに追加されていました。
といっても、セッションIDがストレージ関連であることを示すSTGで始まっていること、登壇者の一人がS3のディレクターであることから、どんな内容になるかは大方見当が付きます。
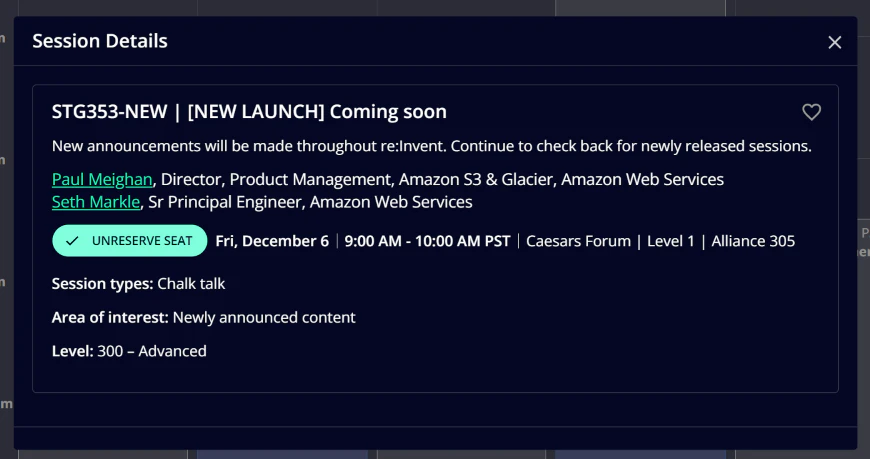
具体的なタイミングは忘れてしまいましたが、会期中に確認したところ、セッション名が"[NEW LAUNCH] Comming soon"から現在の"[NEW LAUNCH] Accelerate data discovery with Amazon S3 Metadata"に更新されていました。おそらく、本サービスが発表されたCEOのKeynote(2日目午前)以降に更新されたと思います。
そして本題ですが、本セッションはre:Invent会期中に発表されたAmazon S3 TablesとAmazon S3 Metadataを取り上げるChalk Talkです。
登壇者はAWSでS3の開発に長年携わるエンジニア2名で、内部の仕組みを踏まえて解説し、質問にも詳しく答えていました。セッションの構成としては、最初の10分で新発表の内容をおさらいし、残り50分は聴講者からの質問を受け付ける構成です。
紹介されていたS3 TablesとS3 Metadataの利点と特長を以下にまとめておきます。
-
S3 Tables
- 利点:S3における構造化データの管理を簡素化。
- 特長:
- バケット種別としてテーブルバケットを新たに導入し、テーブルをAWSマネージドなリソースとして管理。
- Apache Icebergを使用したOpen Table Format、データ形式としてApache Parquetに対応。
- Amazon AthenaやAmazon EMRによる高速なクエリ実行とテーブルメンテナンスが可能。
-
S3 Metadata
- 利点:S3に保存された非構造化データに対するメタデータ管理を自動化。
- 特長:
- バケットに保存された全てのオブジェクトに対して自動的にメタデータ(いわばジャーナルログ)を生成。
- 生成されたメタデータはSQLクエリで簡単にアクセス可能。
- 21種類のシステムメタデータフィールドを自動的に提供。
- ユーザーカスタムのメタデータも追加可能。
製品ページも執筆時点(2025/3/21)では整備されていますね。
想定されるユースケースとしては以下が紹介されていました。
- オブジェクトの検索と処理
- ビジネスロジックの一環として、特定のオブジェクトを識別し処理するために使用。
- SQLクエリを使って簡単にオブジェクトをフィルタリング可能。
- データの理解と追跡
- データセットの状態を特定の時点で把握し、変更履歴を分析するために使用。
- データリネージの簡易的なソリューションとして機能。
- ストレージ使用状況の把握
- SQLクエリを使ってストレージの使用状況を詳細に分析可能。
- インフラチームがストレージ管理を効率化するためのツールとして利用。

聞き取れた質疑のうちいくつかをご紹介します。出たばかりのサービスで疑問に思うことを開発者にすぐ直接尋ねることができるのはre:Inventならではです。
Q:アカウントごとに1つのメタデータテーブルしか存在しないのか。
A:ソースバケットごとに1つのテーブルだが、1つのテーブルバケットに複数のソースバケットのメタデータを含められる。
Q:S3上のオブジェクトにアクセスしたが、アクセス権限が無かった時は記録されるか。
A:記録されない。オブジェクトの作成、削除、メタデータの更新のみが記録される。
Q:メタデータの記録を有効にしていたバケットで記録を無効にすると記録済みのメタデータはどうなるか。
A:そのまま残る。
Q:DynamoDBとS3 Tablesに同じデータを保管した場合、パフォーマンスに違いは出るか。
A:設定による。
Q:SDKはもう使えるのか。
A:まだプレビュー版だがもう使える。
S3上で構造化データを扱えるようになること、S3上のオブジェクトのメタデータをSQLでクエリできるようになることは、これまで以上にシステムの構成やデータの管理を簡素化できると思うのでうれしい新サービスですね。
座席数100程度に対し、最終日ながら当日枠を狙う待機列も長く、基盤的な技術であるストレージに関しても聴講者の興味が高いことを感じました。
質問時間が長く取られたこともあり、質問者は十数名を数え、次々と質問が飛び交う空間でした。
時折、聴講者からの質問に"Fantastic idea!"や"Great question!"と登壇者が返答する場面もあり、ユーザーが疑問に思う点やニーズなど生の声を直接開発者に伝えられる貴重な場面であるとも感じました。
一部の聴講者は、セッション終了後に登壇者に駆け寄り、追加で質問をしている光景も見られました。

STG403-R1 | Safeguard and audit data protection with AWS Backup [REPEAT]
re:Invent最後のセッションは、AWS Backupに関するWorkshopに参加しました。
ここで扱う内容は、単なるバックアップだけではなく、バックアップが正常に実行されているかの確認や、バックアップデータが誤って消されないように保護されているかなどコンプライアンスに関係した内容も含んでいます。
AWS Backupは、EC2インスタンスやRDSのバックアップのために機能を試してみたことはありましたが、より厳重にバックアップを管理するための機能は今回初めて触りました。
スライドで紹介されていたAWS Backupの概要です。ストレージ関連のサービスを中心に幅広くカバーしています。
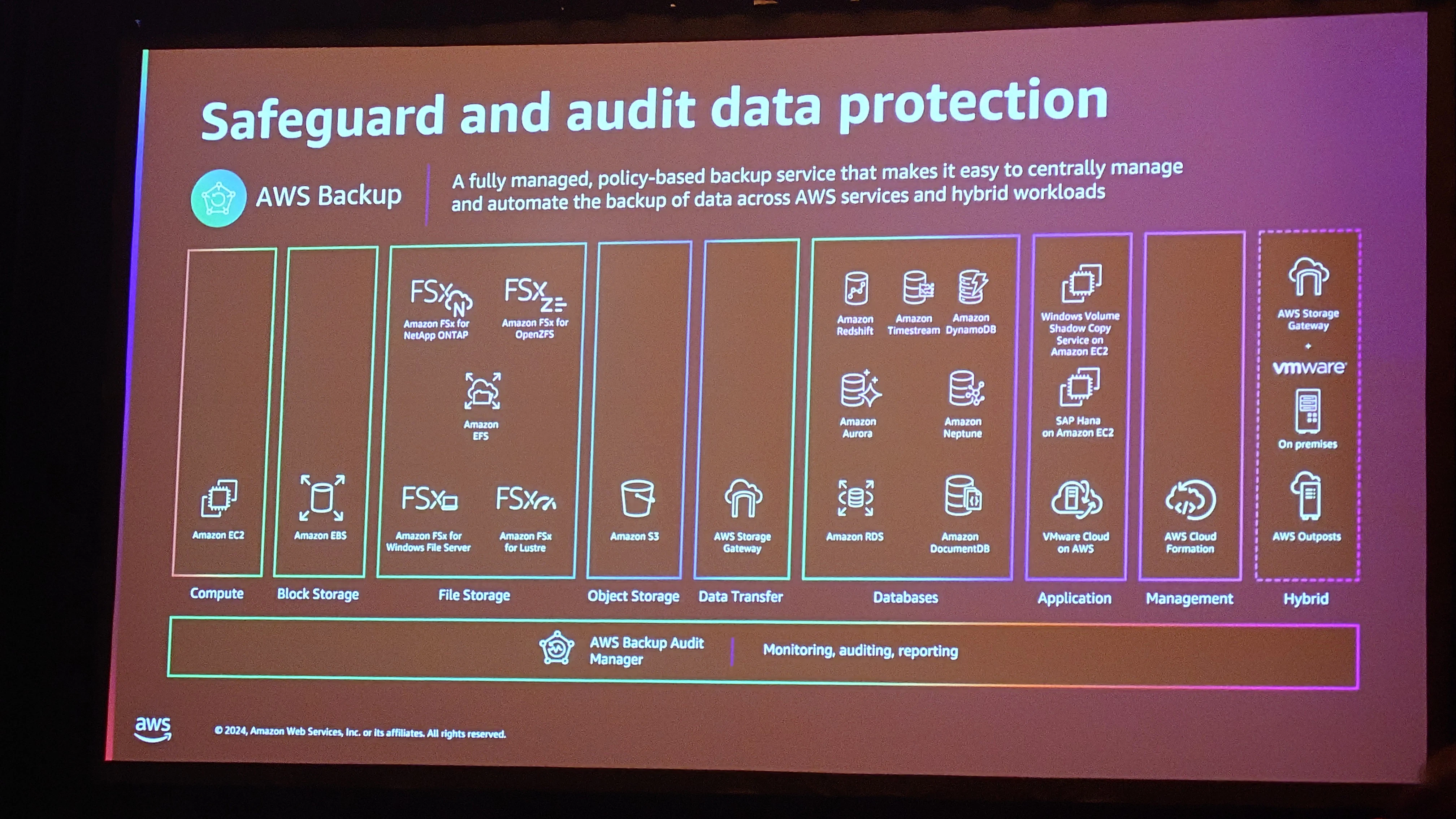
AWS Backupのユースケースとしては、以下の例が紹介されていました。
- クラウドネイティブなバックアップ
- コンプライアンスとガバナンス
- DR対策
- ランサムウェアからの保護と復旧

ワークショップで体験する内容の要点としては、以下の通りです。コンプライアンス関連の機能を使い尽くします。
- AWS Backup Audit Managerを使用し、バックアップジョブとコンプライアンスを監視するための基盤を設定。
- 複数のAWS Backupボールト、ボールトポリシー、およびボールトロックを使用し、データに複数の保護層を適用。
- 組織のコンプライアンス基準を満たすパラメータセットを使用し、Gold Tierリソースが保護されるようにするAWS Backupプランを作成。
- データの誤削除や変更後にアプリケーションを既知の良好な状態に復元する方法を実演。
構築した環境の構成図は以下の通りです。背後にAuroraと接続し、EC2上で動作するWebサーバーが今回のサンプルアプリケーションです。
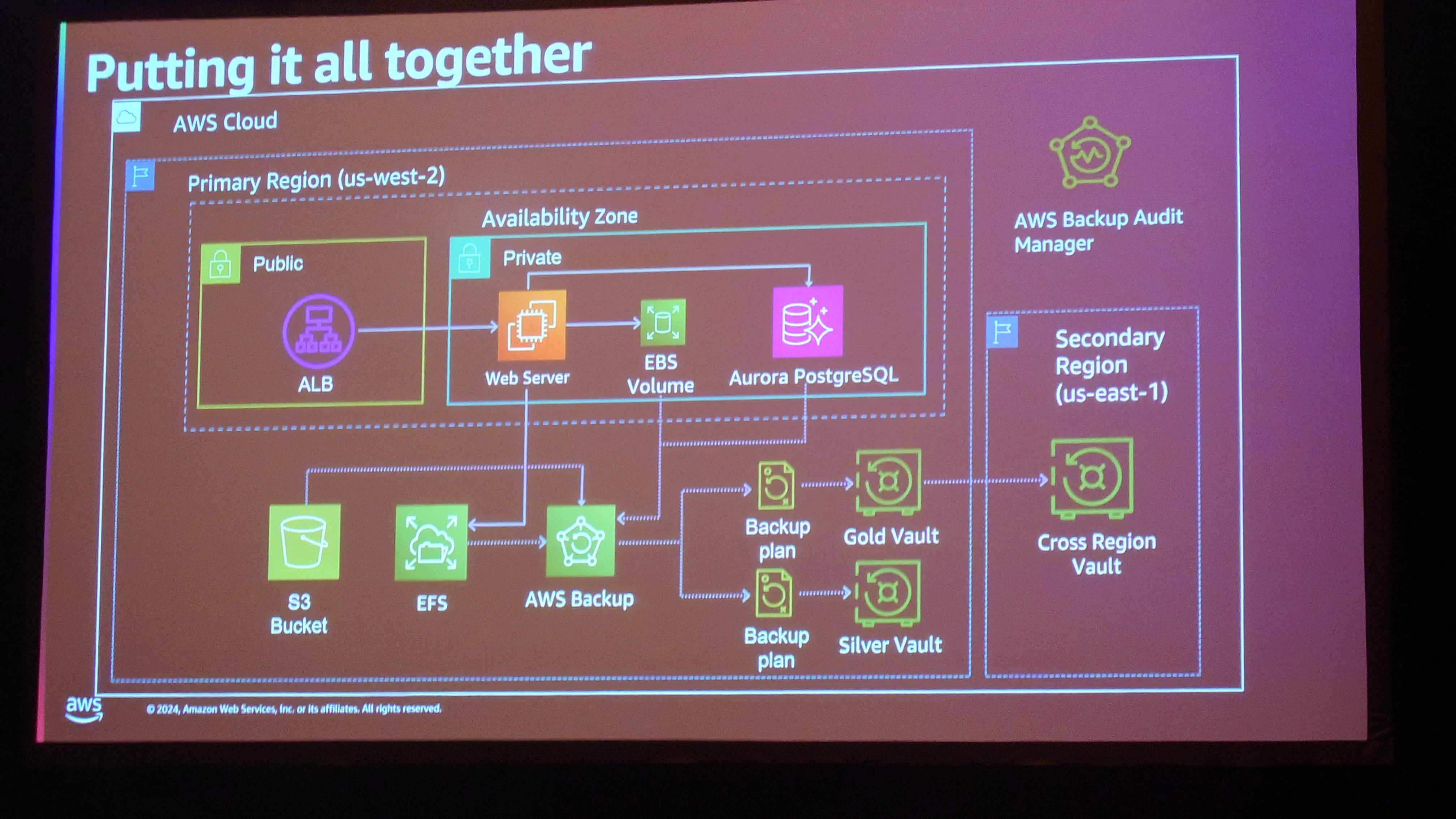
バックアップの対象リソースは、EC2、EBS、EFS、S3、Auroraです。
今回のシナリオでは以下のようにTierを分けてバックアップを管理しました。
| Gold Tier | Silver Tier | |
|---|---|---|
| 頻度 | 毎時 | 最低1日1回 |
| 保持期間 | 最低90日間 | 最低30日間 |
| その他 | 地理的に離れた場所に バックアップのコピーを保管 |
Gold Tierは特に重要なバックアップ向けのポリシーで、今回はEC2のバックアップに適用します。Gold Tierのバックアップに関しては、クロスリージョンコピーが適用されます。
また、ボールトロックを使用し、バックアップが不用意に削除されないようにポリシーを設定しました。
ボールトロックにはガバナンスモードとコンプライアンスモードの2つがありますが、特にコンプライアンスモードでは、猶予期間を過ぎるとたとえrootユーザーやAWSでさえバックアップを削除できなくなる強力な保護が適用されます。
以上、ワークショップではAWS Backupの様々な機能を実際に使用して、サンプルアプリケーションをバックアップしたり、実際に保護されているバックアップが削除できないことを確認したりしました。また、リソースの一部を一旦削除し、バックアップから復元する操作も試しました。
AWS Backupと連携したSNSからは、バックアップ処理の完了後に以下のような内容のメールが飛んできました。
An AWS Backup job was completed successfully. Recovery point ARN: arn:aws:backup:us-west-2:123456789012:recovery-point:images-bucket-487b8fa0-b344-11ef-8aad-02-20241206201744-22e43683. Backed up Resource ARN : arn:aws:s3:::images-bucket-487b8fa0-b344-11ef-8aad-02c2c8cd5ac5. Backup Job Id : 871C5EDE-5739-83C2-A8BD-26D7EE1BDAE2
AWS Backupの機能をここまで使い込んだのは初めてでしたが、マネージドな分、誤ってバックアップデータを削除したりランサムウェアによって暗号化されてしまったりすることを防げるのがメリットだと思いました。
コンプライアンスの達成状況を画面で確認できるのも、監査の観点で管理がしやすいと思いました。
ACT130 | Ride the slide (sponsored by Datadog)
実は開催前日の日曜日から最終日までやっているDatadog提供のスライド(滑り台)です。メイン会場の1つVenetianにある階段に滑り台が特設され、誰でも滑ることができます。
どの日に滑りに来てもよかったのですが、結局全セッションが終わった最後の最後に滑り込みでの参加となりました。
途中の踊り場でバウンドしそうになったり、一番下はクッションが敷き詰められているので安心して突っ込めたりと大人でも楽しいです。

滑っている途中でアトラクションよろしく最後の部分で写真を撮ってもらえます。また、滑り終わるとre:Inventの文字とDatadogのロゴ入り「I RODE THE SLIDE!」ステッカーももらえるので、間接的にre:Inventに参加したことを証明できます。

ところで、最終日の昼近くになるとブースが店仕舞いを始めますが、終了予定時刻の30分前に既に撤収が完了しているなど、さすがアメリカだなと感じる場面もありました。最終日の最後にまわろうとしている方はご注意を。
5日間のまとめ
re:Invent 2024を簡単に振り返ります。
まずイベントとしては、生成AIが出始めたre:Invent 2023と比べて、2024は生成AIの活用が当たり前の内容になっていました。セッション名にも「Generative AI」と付くものが多く(付くものの方が多く)、セッション以外のブースなどでも生成AIを活用した展示が多くありました。
また、AWSのパートナー企業が出展するExpoでも、生成AIをどんどん活用する企業もあれば、何としてでも自社サービスに取り入れなければ取り残されてしまうという焦りをにじませる企業もありました(無理して活用しているな…と展示内容からの私の主観です)。
一方で、AWSとしては、ストレージやコンピューティングなど、従来技術の進化に関しても引き続き注力している印象を受けます。Aurora DSQLやEKS Auto Modeなどがその例です。
個人としては、Breakout Session中心で受け身的だった2023の反省を踏まえて、よりインタラクティブなChalk TalkやGameDayを中心にセッションを選択しました。
最終的に、Keynoteを2回、Breakout Sessionを2回、Chalk Talkを6回、GameDayを3回、Workshopを2回聴講しました。その他にもExpoや5Kマラソン、BuildersCardなどコミュニティイベントにも多数参加しています。
中でも、GameDayで日本人1人で海外の方とチームを組み、好成績を残せたのは今回の収穫です。次回参加する機会があれば、Chalk Talkで質問するなど、より積極的に行動したいです。
開催日前日から最終日まで滞在したこともあり、体力の限界に近い中、re:Inventを味わい尽くすことができました。最終日の午後はラスベガスを満喫し、翌日土曜日の早朝のフライトでラスベガスを後にしました。
最後に私のスケジュールを載せておきます。バツを付けたものは受けなかったセッションです。結構詰め込んだ方だと思います。
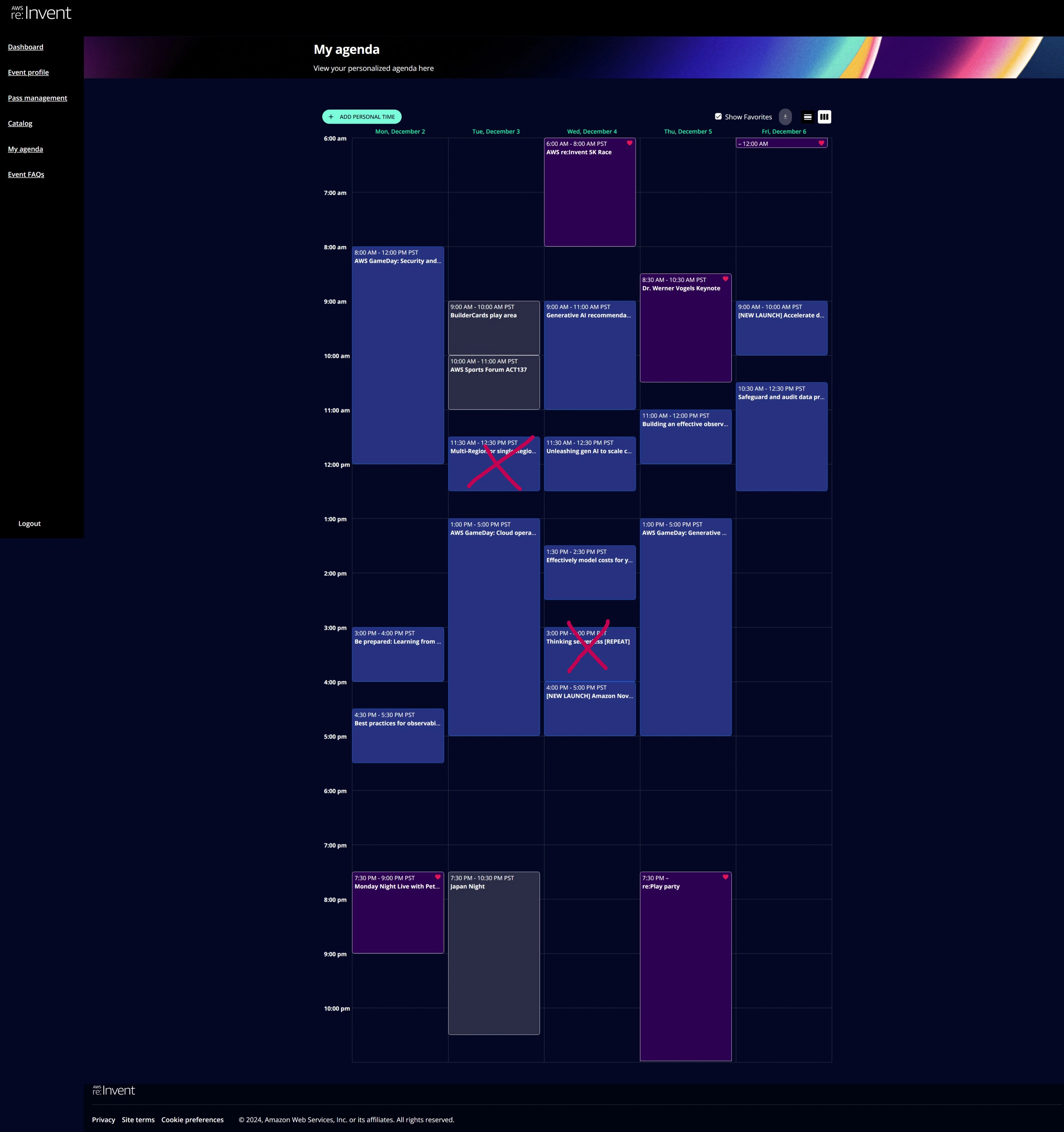
後から振り返ろうとしても遅すぎると参加者ポータルのサイトが閉じられてしまいますが、今回は2025/3/21時点でまだ使えました。re:Invent 2023の時よりも長い間使えています。AWSイベントアプリの方は、もうログインできなくなっているようです。
おわりに
re:Inventの最終日5日目の内容をお伝えしました。最後の最後まで刺激を受けつくした1日になったと思います。
新サービス発表後のセッションは、単に新サービスの詳細を開発者から直接聞けただけでなく、他の参加者が新サービスに対して何に注目しているか、どう活用しようとしているかを窺い知れる機会にもなりました。
自分も積極的に質問できるように、AWSのサービスに慣れ、語学力を身に付けていきたいところです。
5回に渡る参加レポートをお読みいただきありがとうございました。
今後のre:Inventにも注目していきます。