1. はじめに
文章の中で重要な意味を表す単語を導出したいと思ったことありませんか?例えばAmazonのレビューでは、レビューに使われているトピックが下のような形で表示されています。

今回はこのように商品の性質を表す、タグのようなものを抽出してみようと思います!
(アドバイスや間違いがあれば、ご指摘よろしくお願いします!)
本記事の章立て
利用ライブラリ
pandas, pke, ginza, seaborn
1. 商品情報の取得
今回はECサイトの商品のセールストークをスクレイピングし、そこからキーフレーズを抽出します。以下のようにデータフレームにしてまとめておくと、後々加工しやすいので便利です

2. キーフレーズ抽出
pke(python keyphrase extraction)という、キーフレーズ抽出ライブラリを用います。詳しく知りたい方は、この記事で分かりやすく説明されているので参照してみてください
前述の記事に倣ったコードを掲載します。
def keyword_extract(text, n=5):
extractor = pke.unsupervised.MultipartiteRank() # 他にも色んな手法を選べます
extractor.load_document(input=text, language='ja', normalization=None) # languageで日本語設定
extractor.candidate_selection(pos={'NOUN', 'PROPN', 'ADJ', 'NUM'}) # 抽出する品詞を選択
extractor.candidate_weighting(threshold=0.74, method='average', alpha=1.1)
return extractor.get_n_best(n)
# 先程作ったデータフレームに、この関数を適用します。
tqdm.pandas()
df['キーフレーズ'] = df.progress_apply(lambda x :keyword_extract(x['セールストーク']), axis=1)
出力結果

3. アノテーション作業
どれだけいいキーフレーズが抽出できたか定量化するために、セールストークにアノテーションします。
3-1. まずはテキスト出力
with open('sales_talk.txt', 'x') as f:
for d in df['セールストーク'].tolist():
f.write("%s\n" % d)
3-2. アノテーション
アノテーション作業にはdoccanoを使用しました。インストール方法はいろいろあるらしいのですが、Dockerを用いてインストールします。
$ docker pull doccano/doccano
$ docker container create --name doccano \
-e "ADMIN_USERNAME=admin" \
-e "ADMIN_EMAIL=admin@example.com" \
-e "ADMIN_PASSWORD=password" \
-p 8000:8000 doccano/doccano
$ docker container start doccano
起動したら、ブラウザで http://127.0.0.1:8000/ へアクセス(少し時間がかかるかもしれません)。
ちなみにdoccanoは下のように、マウスでアノテーションができるので便利です!
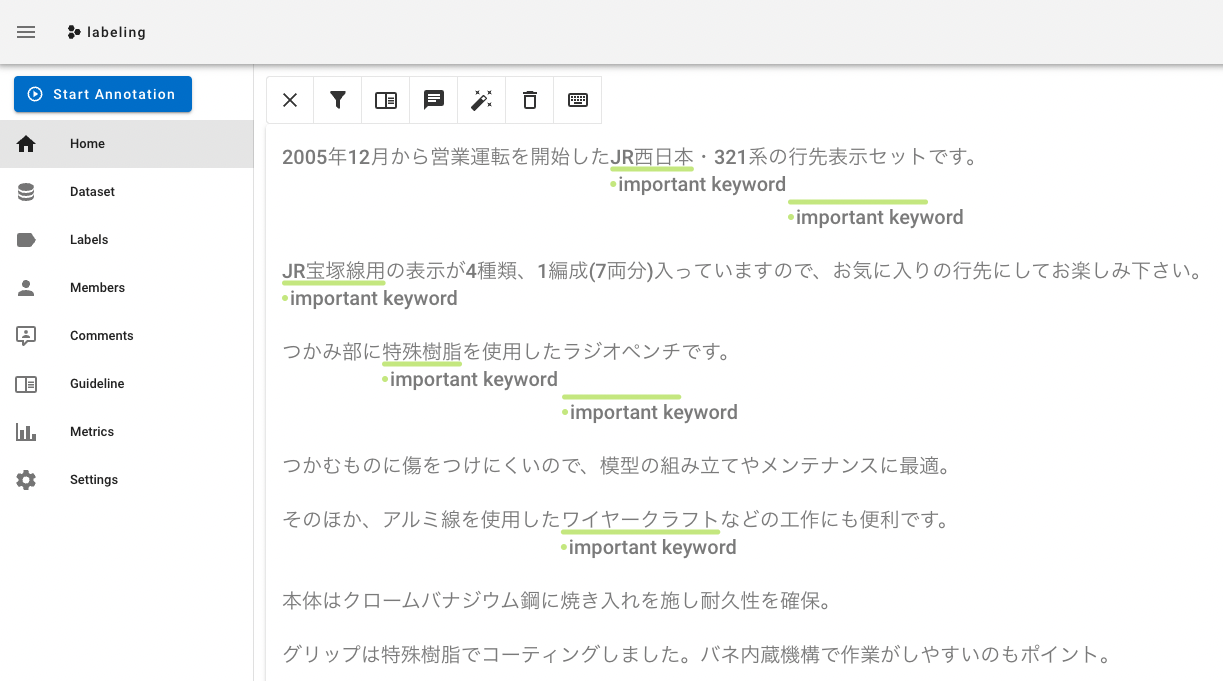
3-3. アノテーション出力ファイルの読み込み
doccanoでアノテーションを行いexportすると.jsonl形式でデータが取れます。
_df = pd.read_json('admin.jsonl', orient='records', lines=True)
↓↓出力結果(textに3-1で出力したテキスト全文が、labelにアノテーションした場所が格納されています。)

ちなみに以下のようにすると、テキスト全文とアノテーションしたキーワードを取れます。
# テキスト全文
texts = _df['text'][0]
# アノテーションしたキーワード
keywords = []
for i in _df['label'][0]:
keywords.append(texts[i[0]:i[1]])
4. 評価
全ての準備が整ったところで精度を求めてみます。
def ask_evaluation(_df, df, method):
# アノテーションしたデータを辞書型へ
labeling = {}
txt = _df['text'][0]
for i in _df['label'][0]:
counter = 0
for key, value in enumerate(txt.split('\n')):
if counter <= i[0] <= counter + len(value):
labeling.setdefault(key, []).append(txt[i[0]:i[1]])
counter += len(value)
# labeling = {0: ['jr西日本', '行先表示セット', 'JR宝塚線用'], 1: ['特殊樹脂', 'ラジオベンチ', 'ワイヤークラフト'],・・・}
# データフレームから辞書型へ
predict = {}
for key, value in enumerate(df[category].tolist()):
for i in value:
predict.setdefault(key, []).append(i[0])
# predict = {0: ['jr西日本', '行先表示セット', '営業運転'], 1: ['特殊樹脂', 'グリップ' '焼き入れ'],・・・}
# 合致したキーワード数
nums = 0
for i in range(len(labeling)):
for j in predict[i]:
for k in labeling[i]:
if j in k or k in j:
nums += 1
# アノテーションしたキーワード総数
total_labels = 0
for i in range(len(df[category].tolist())):
total_labels += len(df[category].tolist()[i])
# pkeで求めたキーワード総数
total_predict = len(_df['label'][0])
# 以下のようにrecallとprecisionを定義
recall, precision = nums / total_labels, nums / total_predict
f1_score = recall * precision * 2 / (precision+recall)
return print(f'recall = {recall}, precision = {precision}, f1_score = {f1_score}')
↓↓出力
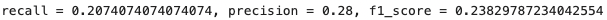
5. 精度比較
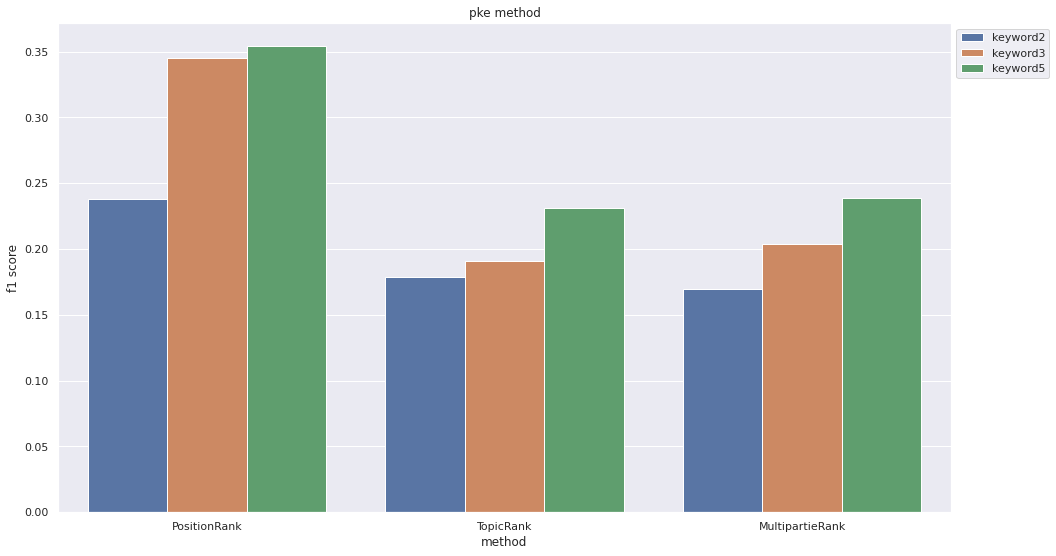
pkeでは様々な手法を選べるので、方法とキーワード抽出数を変えて精度を比較してみます。
data1 = [0.238,0.179, 0.170] # 抽出数を2にしたときのそれぞれのF値
data2 = [0.345, 0.191, 0.204] # 抽出数を3にしたときのそれぞれのF値
data3 = [0.354, 0.231, 0.239] # 抽出数を5にしたときのそれぞれのF値
index = ["PositionRank", "TopicRank", "MultipartieRank"] # 今回試した手法
df = pd.DataFrame(data={"keyword2": data1, "keyword3": data2, "keyword5": data3}, index=index)
data = df.stack().rename("f1 score").rename_axis(["method", "category"]).reset_index()
# グラフサイズ設定。
plt.figure(figsize=(16, 9), facecolor="w")
sns.barplot(data=data, x="method", y="f1 score", hue="category")
title = "pke method"
plt.title(title)
plt.legend(loc="upper left", bbox_to_anchor=(1,1))
plt.show()
出力
6. おわりに
今回はpkeを用いてキーワード抽出をしてみました。pke以外にもいろんなキーワード抽出方法があるので、これからは他の手法も試してみようと思います。