概要
TesseractとはGoogleのOCRライブラリで、そのJavaScript版がTesseract.jsである。
Tesseract.jsは文字認識に用いる言語ファイルを「tessdata.projectnaptha.com」からブラウザのデータストレージ(indexedDB)にダウンロードしてOCRを行う仕組みとなっているため、オンライン状態でないと使用できない。
(2回目以降はindexedDBに保存されている言語データを参照するためオフラインでも使用可)
予めローカルにDLした言語ファイルを参照するように設定もできるが、言語ファイルの読み込み処理がfetch APIで実装されてることと(ローカルファイル"file://"の読み込みはスキームサポート外)、ブラウザのセキュリティ設定によりローカルファイルの読み込みが制限されることから、オフラインで動作させるにはWebサーバー上であることが必須。
Webサーバーを用意しなくても、オフラインで動作するツールを作成してみた。
事前準備
①以下資材をCDNからダウンロード
※今回使用するTesseract.jsのバージョンは2.2.0
・tesseract.min.js
・tesseract.min.js.map
・worker.min.js
・worker.min.js.map
・tesseract-core.wasm.js
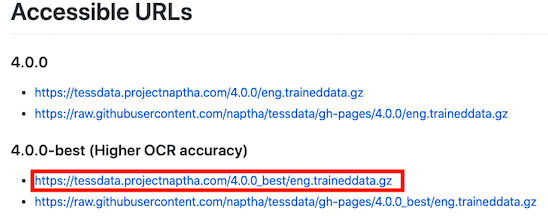
②言語ファイルを以下URLからダウンロード
https://tessdata.projectnaptha.com/
「4.0.0-best」>「eng.traineddata.gz」を選択
("xxx-best"版の方がOCR精度が高い)
日本語対応させたい場合は、「jpn.traineddata.gz」を使用する。
https://tessdata.projectnaptha.com/4.0.0_best/jpn.traineddata.gz
しかし、Tesseract.jsの日本語の読み取り精度があまりよくないため、本稿では英語圏内の「eng.traineddata.gz」を使用する。
③gzipの圧縮・展開ライブラリをダウンロード
https://github.com/imaya/zlib.js/blob/develop/bin/gunzip.min.js
ツール作成
参考記事:https://qiita.com/hiroism/items/bd537e014e71d3cab1f9
<html lang="ja">
<body>
<input type="file" id="imagearea">
<br>
<div>
進捗: <span id="progress">0</span>%
</div>
<div>
<textarea id="result" style="height: 300px;width:300px;"></textarea>
</div>
<script src='js/tesseract.min.js'></script>
<script src='js/gunzip.min.js'></script>
<script>
// 言語ファイルのデータをindexedDBに保存
writeCache();
document.getElementById('imagearea').addEventListener('change', read, false);
function writeCache() {
var req = indexedDB.open("keyval-store");
req.onupgradeneeded = function (event) {
var db = event.target.result;
db.createObjectStore("keyval");
var xhr = new XMLHttpRequest();
xhr.open('GET', 'traineddata/eng.traineddata.gz', true);
xhr.responseType = 'arraybuffer';
xhr.onreadystatechange = function() {
if (xhr.readyState === XMLHttpRequest.DONE) {
var arraybuffer = new Zlib.Gunzip(new Uint8Array(xhr.response)).decompress();
var transaction = db.transaction("keyval", "readwrite");
var keyvalStore= transaction.objectStore("keyval");
keyvalStore.add(arraybuffer,"./eng.traineddata");
}
};
xhr.send();
}
}
function read(event) {
Tesseract.recognize(
event.target.files[0],
'eng', // 言語
{ logger: m => {
let progressArea = document.getElementById("progress");
progressArea.innerText = m.status + " " + Math.round(m.progress * 100);
} ,
workerPath: 'js/worker.min.js',
corePath: 'js/tesseract-core.wasm.js'
}
).then(({ data: { text } }) => {
// 結果の表示
const result = document.getElementById('result')
result.value = text
})
}
</script>
</body>
</html>
writeCache関数でローカルの言語ファイルをXMLHttpRequestで読み込み、indexedDBに保存する処理を行っている。
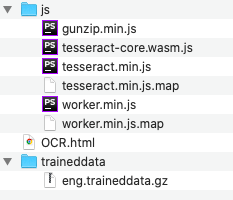
以下、ディレクトリ構成
ツール実行
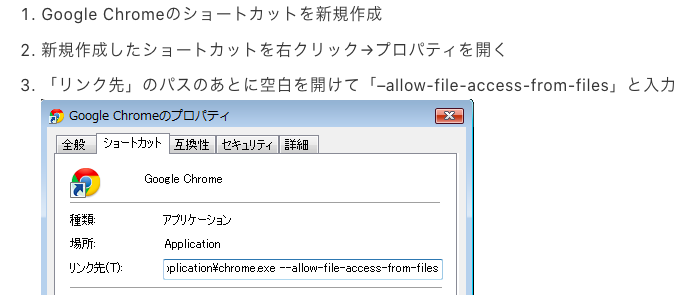
ブラウザのセキュリティ設定でローカルファイルの読み込みが制限されているため、以下起動オプションでGoogle Chromeを起動。
Chromeのプロセスを落とした後に実行
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --args --allow-file-access-from-files
windowsの場合
参考記事:https://www.keyton-co.jp/blog/pc/windows/445/
OCR.htmlを立ち上げて「ファイル選択」を押下し、読み取り画像を選択する。

読み取り画像(Sample.png)

実行結果

追記:言語ファイルの読み込みについて
Chrome拡張機能用のtesseract.jsはfetchでなく、XMLHttpRequestで言語ファイルの読み込みを行うため、Chrome拡張機能用のライブラリを使用すればローカルの言語ファイル"file://"の読み込みは自前で実装することなく、Tesseract.recognize関数の「langPath」を利用するだけでいけることがわかった。
※Chrome起動時の「--allow-file-access-from-files」オプションは必須
Tesseract.recognize(
e.target.files[0],
'eng', // 言語
{ logger: m => {
let progressArea = document.getElementById("progress");
progressArea.innerText = m.status + " " + Math.round(m.progress * 100);
} ,
workerPath: 'js/worker.min.js',
+ langPath: 'traineddata', // 言語ファイルの格納場所を指定
corePath: 'js/tesseract-core.wasm.js'
}
おわりに
仕事がら必要になったので作ってみましたが、結局導入までにいたらず、、
無駄にしないためも記事としてあげて供養させていただきます笑
・公式ページ
https://tesseract.projectnaptha.com/
・Gitリポジトリ
https://github.com/naptha/tesseract.js
・Chrome拡張機能用リポジトリ
https://github.com/jeromewu/tesseract.js-chrome-extension