初めに
最近話題の生成AIであるStable diffusionを理解するために、古くから存在する生成AIのVAEを理解しようと思い、本記事を書きました。もう既に多くの参考資料等が出回っているため、自分の理解のための備忘録レベルのものになっています。
Variational Autoencoder(VAE)とは?
下記参考にさせて頂きました!
図が豊富でとても分かりやすかったです。
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24
Variational Autoencoder(VAE)は、その名にある通り「Autoencoder」の一種です。
まずは簡単に「Autoencoder」について説明します。
Autoencoder
下図が簡単なモデル構成です。
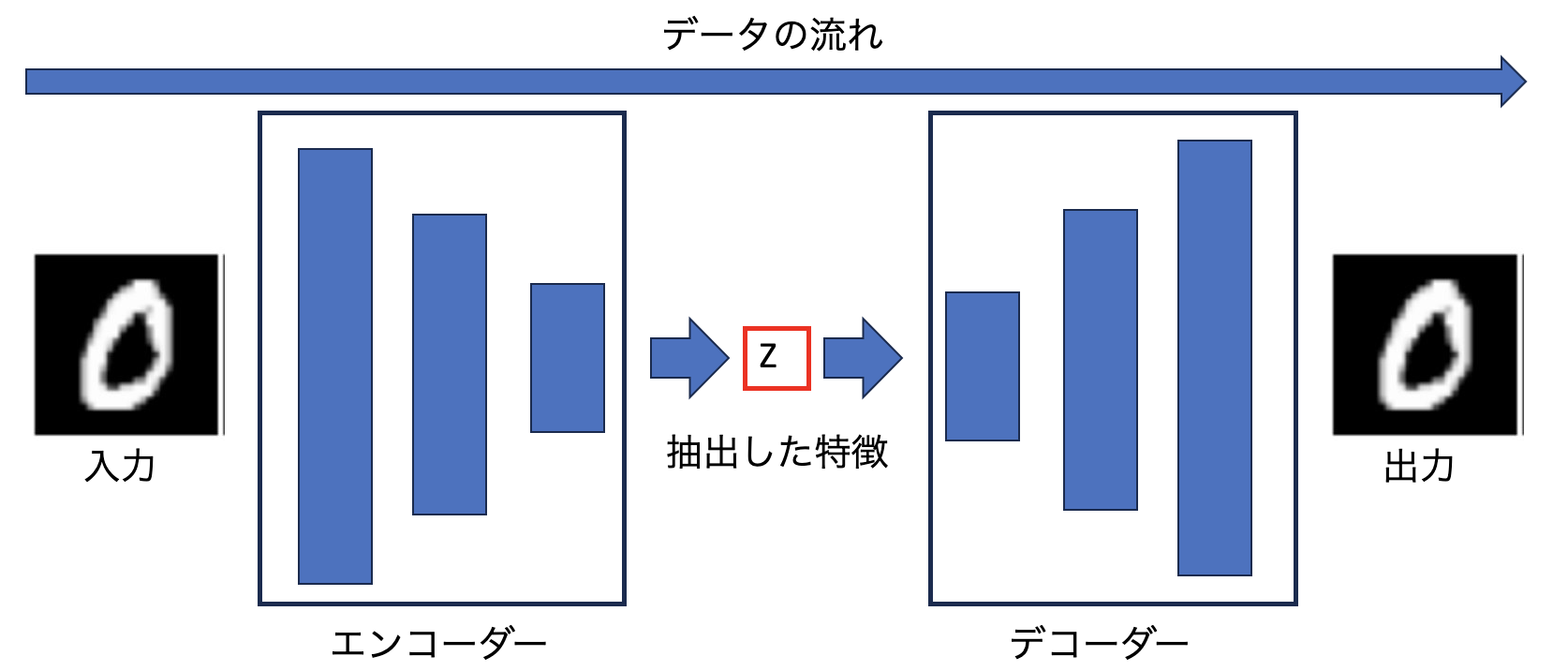
画像を入力として与えて、エンコーダーで特徴を抽出(次元削減)します。
抽出された特徴を「Z」とすると、その「Z」を今度はデコーダーに入力して入力と同等の画像を生成するように学習します。
つまりは、デコーダーの出力と入力画像の差分を損失として学習することで、抽出した特徴「Z」から元の画像を生成するようにデコーダーは学習していきます。
Variational Autoencoder(VAE)
では、「VAE」は「Autoencoder」と何が違うのでしょうか?
下図が、「VAE」のモデル構成です。
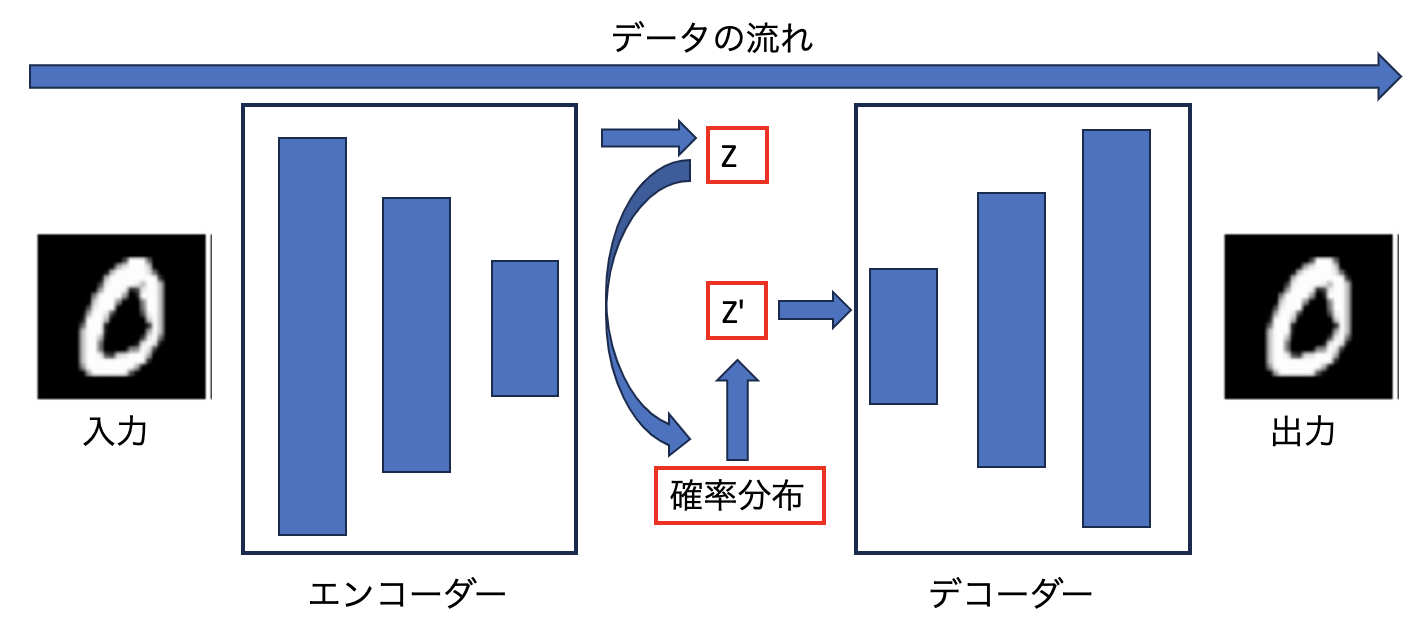
特徴「Z」を抽出するところまでは「Autoencoder」と同じですが、その特徴を用いて確率分布(一般的なのはガウス分布みたいですね。)から新たな特徴「Z'」を出力しています。この「Z'」を用いて、「Autoencoder」と同様にデコーダーの処理を実施します。
具体的には、抽出した特徴「Z」を「平均」と「分散」に変換し、この2変数を用いてガウス分布(図中の確率分布)からのサンプリングが行われます。
こうすることで、CNNで抽出した特徴を確率分布に変換することが可能です。
VAEの損失関数
VAEには特筆すべき点がもう一つあり、それは損失関数にあります。
損失関数は、入力と出力の誤差に加えて、「KLダイバージェンス」を用いています。「KLダイバージェンス」は簡単に言えば、二つの確率分布の差分を測る指標です。
これを用いることで、「Z'」の確率分布とガウス分布の差分を測ることができ、「Z'」の確率分布をガウス分布に近づけるようにペナルティを与えることができます。
VAEのイメージ
VAEの画像生成のイメージですが、学習する画像群がある分布(正規分布)に属していると仮定します。VAEの例では、人の顔画像を学習して生成する例が多いですが、これは人の顔がある確率分布に属しているから学習しやすいと考えられます。
人の顔は、輪郭と髪の毛、目や鼻、口などのパーツによって構成されています。そして、それぞれのパーツの相互間の位置は、全員ほぼ同等と考えられます。そのため、確率分布上のあるパラメータによって、パーツの形状や大きさ、色などが変わるのだと思います。
記事(http://cedro3.com/ai/keras-vae-celeba/) が分かり易いですが、「Z'」を2次元空間上にプロットした際の生成される画像を対応付けた例を出力してくれています。
これを見ると、パラメーターによって顔の向きや髪、目の形状などが連続的に変化していることが分かります。
VAEで学習/生成できる画像
色々実験したわけではないですが、恐らく特定の基準(顔画像であれば、画像内には顔のみかつほぼ正面を向いている)を満たすデータセットでなくては学習が難しいと思われます。
例えば、仮に猫の画像を生成したい場合、通常の画像認識であれば画像中に猫が写っていれば良いです。
しかし、VAEの場合はそうはいかず、例えば猫の顔のみの画像にトリミングする、全体を学習させたい場合は、地面に4足で立っている画像のみを用いるなど、ある程度基準を設ける必要があると考えております。(データセット選定が大変なため検証はできていないですが、上記関係なく物体認識と同様のデータセットで特徴学習できるならば凄いと思います!)
まとめ
VAEは
1.CNNで抽出した特徴をある確率分布に変換することで、特徴を連続的な変数としている
2.確率分布として学習するために、損失関数に「KLダイバージェンス」を用いている
上記二つが特筆すべき内容と思います。
終わりに
古くからある内容のためあまり参考にならないかもしれませんが、自分の備忘録としてまとめてみました。最近の生成AIは顔のみではなく、体全体を含めて高精度で生成できているため、モデルの構造や学習過程が気になりますね。そちらも理解できれば、自分なりにまとめてみようと思います。