初めに
上記の続きとなります。
学習に時間がかかってしまい、投稿まで時間が掛かりました。。。
動作環境
tensorflow-gpu==2.10.0
gpu:NVIDIA GeForce GTX 1660
matplotlib(学習の推移を確認するために使用)
tf_explain-0.3.1(grad-camでの確認に使用)
jupyternotebook
データセットについて
今回は、「crab(蟹)」「deer(鹿)」「dolphin(イルカ)」「flamingo(フラミンゴ)」「monkey(猿)」の5種類の動物の画像を100枚ずつ生成(chat-gptを用いて)しました。
trainデータとして80枚ずつの合計400枚、validationデータとして20枚ずつの合計100枚を用いて学習しました。
学習データ例です。
crab(蟹)

「deer(鹿)」

「dolphin(イルカ)」

「flamingo(フラミンゴ)」

「monkey(猿)」
全て生成した画像です!
本物と遜色無いですよね!
学習時の設定
kerasの「flow_from_directory」を用いました。業務ではスコアファイルを作成していましたが、これを用いればディレクトリ構造だけで自動にラベル付けして学習するのでとても便利でした。
また、「ImageDataGenerator」を使用し、回転,縦横方向シフト,シアー変換,ズーム,水平反転の変換を加えました。
モデルは、VGG16とResNet50にファインチューニングを行って学習しました。
validationデータも使用したため、early_stoppingをvalidationデータを対象に行なっています。
使用モデル
- VGG16
- RESNet50
両者finetuningでの学習を実施
学習設定
まずはVGGモデルの設定をします。
# VGGモデルの設定
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import optimizers
from tensorflow.keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
x = conv_base.output
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(256, activation='relu')(x)
x = tf.keras.layers.Dense(5, activation='softmax')(x)
model = tf.keras.Model(inputs=conv_base.input, outputs=x)
model.summary()
# 利用するモデルのtrainableを全てFalseに
conv_base.trainable = False
VGGモデルのfinetuningの設定はこれで完了です。
finetuningとは、学習済のモデルを用いて再学習する方法です。
※一般的には「imagenet」を用いて学習した学習済モデルを使用します。
「imagenet」で学習したモデルは出力ラベル数が1000個あります。
下記、簡単な流れです。
- 元のモデルの出力層のみを削除して新たに層を追加します
- 追加した層のみ学習可能にし5~10epoch程学習します(対象によってどの程度学習するかは変わってくると思いますが、数epoch程度で問題ないと思います)
- 最後に、適当な層までを学習可能にして長いepoch(今回は100epoch)学習します
1では、「imagenet」で学習したモデルでは出力が1000個あるため、大抵は少なくとも出力の数を変える必要があります。そのため、層の削除と追加を実施します。
2では、「imagenet」で学習している重みを全く別の学習データでの重みに変更するため、出力層付近の重みを既存の学習済の重みに均すために行います。
3では、最後に中間層よりも下位層の重みを学習します。
因みに、中間層よりも下位層の重みのみを学習する理由としては、上位層が輪郭など人が目で見て理解できるレベルの特徴を学習しており、それはどのモデルでも同様だからとのことです。しかし、下層になればなるほど、人が見ても理解できないレベルの学習データの本質的な特徴を学習するため、再度学習することになります。
(下記記事が分かりやすいと思います。層が深くなるにつれて目視では分かりにくい特徴が抽出されています。https://hazm.at/mox/machine-learning/computer-vision/keras/intermediate-layers-visualization/index.html)
次に、学習データの前処理設定をします。
from tf.keras.preprocessing.image import ImageDataGenerator
train_dir = "対象フォルダのパス"
validation_dir = "対象フォルダのパス"
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# テストデータは画像変換は行いませんが、正規化だけは実施します
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
# 画像サイズは(150, 150)
target_size=(150, 150),
# メモリに収まる数に設定します
batch_size=32,
# クラスが複数のため「categorical」に設定
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='categorical')
次に、学習データの前処理設定を行います。
上記の様に設定することで、学習時の画像に変換を加えることができます。一般的に、画像前処理を行うことで汎化性能が向上します。
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['acc'])
モデルのコンパイルを行います。
ここでは、「損失関数の設定」「オプティマイザーの設定」「メトリクスの設定」を行っています。
損失関数は、何を最小化したいかで用いるものも変わってきます。損失関数を工夫することで精度の向上を達成しているモデルが多いです。
オプティマイザーは、確率的勾配降下法の手法を選択します。確率的勾配降下法は、損失関数を最小化する際のアルゴリズムです。一般的には「Adam」が用いられています。
メトリクスは、学習時に表示される対象になります。今回は「acc(正解率)」のため、accがepoch毎に表示されます。
# 学習とvalidationのステップ数を、「学習(validation)データ総数//batch_size」で計算
STEP_SIZE_TRAIN = train_generator.n//train_generator.batch_size # 切り捨て除算
STEP_SIZE_VALID = validation_generator.n//validation_generator.batch_size
print("train_generator.n:", train_generator.n)
print("valid_generator.n:", validation_generator.n)
print("STEP_SIZE_TRAIN:", STEP_SIZE_TRAIN)
print("STEP_SIZE_VALID:", STEP_SIZE_VALID)
次は、trainとvalidationデータの1epoch内での学習回数を算出しています。
1epochの学習回数は、基本的には「総学習データ//バッチサイズ」となります。
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping
# modelの保存場所や保存条件の設定をします
modelCheckpoint = ModelCheckpoint(filepath = 'model_gptimg_vgg_fine.h5',
monitor='val_loss', #validationデータの損失を、モデルの保存根拠とします
verbose=1, #
save_best_only=True,
save_weights_only=False,
mode='min',
period=1)
early_stopping = EarlyStopping(monitor='val_loss', patience=20, verbose=0, mode='auto')
次は、モデル保存の設定(ModelCheckpoint)とアーリーストッピング(EarlyStopping)の設定をします。
ModelCheckpointでは、モデル保存場所やどんな条件の場合にモデルを更新するかなどを決定します。
ModelCheckpointとearly_stoppingはとても便利だと思います。
引数詳細は、はtfの公式(https://www.tensorflow.org/api_docs/python/tf/keras/Model) やkerasの公式(https://keras.io/ja/models/sequential/) を参照してみて下さい。
EarlyStoppingは、monitor='val_loss'がpatience='20'epoch数に改善しなければ、モデルの学習を終了するという設定ができます。この設定によって、学習データに対する過学習を防ぐことができます。
では、5epoch程学習します。
history = model.fit_generator(
train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=5,
validation_data=validation_generator,
validation_steps=STEP_SIZE_VALID,
callbacks=[modelCheckpoint, early_stopping])
結果は下記のようになりました。
Epoch 1/5
12/12 [==============================] - ETA: 0s - loss: 1.7788 - acc: 0.4896
Epoch 1: val_loss improved from inf to 0.57381, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_vgg_fine.h5
12/12 [==============================] - 5s 355ms/step - loss: 1.7788 - acc: 0.4896 - val_loss: 0.5738 - val_acc: 0.7396
Epoch 2/5
12/12 [==============================] - ETA: 0s - loss: 0.6745 - acc: 0.7717
Epoch 2: val_loss improved from 0.57381 to 0.16765, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_vgg_fine.h5
12/12 [==============================] - 5s 326ms/step - loss: 0.6745 - acc: 0.7717 - val_loss: 0.1676 - val_acc: 0.9479
Epoch 3/5
12/12 [==============================] - ETA: 0s - loss: 0.3036 - acc: 0.8886
Epoch 3: val_loss improved from 0.16765 to 0.14237, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_vgg_fine.h5
12/12 [==============================] - 4s 335ms/step - loss: 0.3036 - acc: 0.8886 - val_loss: 0.1424 - val_acc: 0.9479
Epoch 4/5
12/12 [==============================] - ETA: 0s - loss: 0.2364 - acc: 0.9212
Epoch 4: val_loss did not improve from 0.14237
12/12 [==============================] - 4s 315ms/step - loss: 0.2364 - acc: 0.9212 - val_loss: 0.1672 - val_acc: 0.9479
Epoch 5/5
12/12 [==============================] - ETA: 0s - loss: 0.1794 - acc: 0.9293
Epoch 5: val_loss did not improve from 0.14237
12/12 [==============================] - 4s 316ms/step - loss: 0.1794 - acc: 0.9293 - val_loss: 0.1460 - val_acc: 0.9583
最初から正解率が高い結果になりました。
では、1部の重みを学習可能に設定します。
# モデルlayerの確認
layer_names = []
for layer in model.layers[1:-3]:
print(layer.name)
layer_names.append(layer.name)
# vggモデルのtrainableを1部trueに
idx = layer_names.index('block4_conv1')
print(idx)
model.trainable = True
for layer in model.layers[:idx]:
layer.trainable = False
# trainableの確認
for l in model.layers:
print(l.name, l.trainable)
ここでは、layerの名前を確認してインデックス(idx)を確認しています。その「idx」を用いて、モデルのtrainableを設定しています。
では、再度学習を開始します。
# filepathは、事前に学習したモデルを指定するように
modelCheckpoint = ModelCheckpoint(filepath = 'model_gptimg_vgg_fine.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='min',
period=1)
early_stopping = EarlyStopping(monitor='val_loss', patience=20, verbose=0, mode='auto')
history = model.fit_generator(
train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=100,
validation_data=validation_generator,
validation_steps=STEP_SIZE_VALID,
callbacks=[modelCheckpoint, early_stopping])
100epoch指定しましたが、途中でearly_stoppingで学習が終了しました。
Epoch 1/100
12/12 [==============================] - ETA: 0s - loss: 0.1260 - acc: 0.9674
Epoch 1: val_loss improved from inf to 0.12846, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_vgg_fine.h5
12/12 [==============================] - 4s 360ms/step - loss: 0.1260 - acc: 0.9674 - val_loss: 0.1285 - val_acc: 0.9688
Epoch 2/100
12/12 [==============================] - ETA: 0s - loss: 0.1286 - acc: 0.9609
Epoch 2: val_loss did not improve from 0.12846
12/12 [==============================] - 4s 330ms/step - loss: 0.1286 - acc: 0.9609 - val_loss: 0.1372 - val_acc: 0.9688
Epoch 3/100
12/12 [==============================] - ETA: 0s - loss: 0.1156 - acc: 0.9674
Epoch 3: val_loss did not improve from 0.12846
12/12 [==============================] - 4s 310ms/step - loss: 0.1156 - acc: 0.9674 - val_loss: 0.1364 - val_acc: 0.9583
Epoch 4/100
12/12 [==============================] - ETA: 0s - loss: 0.1170 - acc: 0.9647
Epoch 4: val_loss did not improve from 0.12846
12/12 [==============================] - 4s 315ms/step - loss: 0.1170 - acc: 0.9647 - val_loss: 0.1364 - val_acc: 0.9583
・
・
・
Epoch 26/100
12/12 [==============================] - ETA: 0s - loss: 0.0853 - acc: 0.9740
Epoch 26: val_loss did not improve from 0.07809
12/12 [==============================] - 4s 342ms/step - loss: 0.0853 - acc: 0.9740 - val_loss: 0.2164 - val_acc: 0.9479
Epoch 27/100
12/12 [==============================] - ETA: 0s - loss: 0.0579 - acc: 0.9755
Epoch 27: val_loss did not improve from 0.07809
12/12 [==============================] - 4s 339ms/step - loss: 0.0579 - acc: 0.9755 - val_loss: 0.2078 - val_acc: 0.9583
学習結果の推移を確認します。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
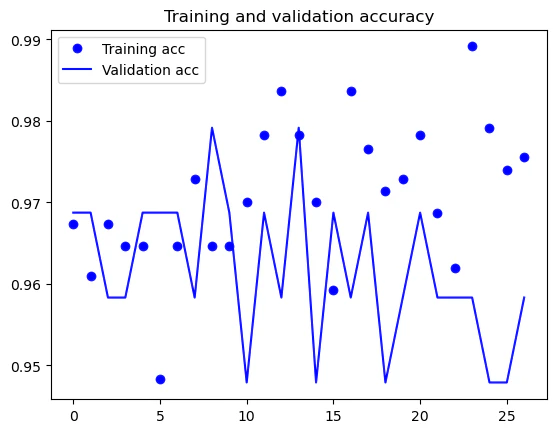
正解率は95%~99%の推移のため少し見にくいですが、学習データの正解率は向上していますが、validationデータの正解率は横ばいです。
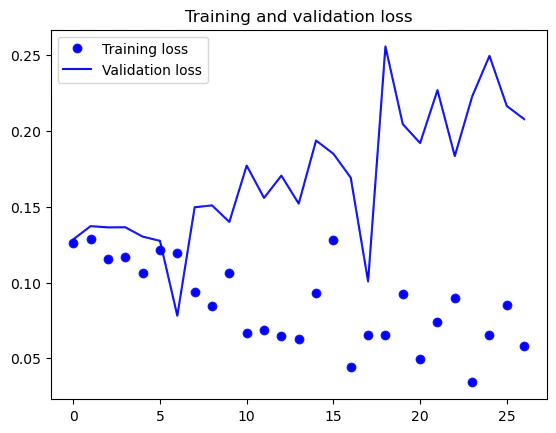
lossを確認すると、training lossは単調現象しているのに対し、validation lossは単調増加の傾向が見られます。これは、過学習の傾向なのでパラメータやモデルなどを変えて再度学習すべきですが、今回はこのモデルを用いて評価します。
評価の前に、Resnet50の例も載せておきます。
流れはVGGと同等なため、説明は省きます。
# use VGG
from keras.applications import ResNet50V2
conv_base = ResNet50V2(weights='imagenet',
include_top=False,
input_shape=(224, 224, 3))
x = conv_base.output
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(256, activation='relu')(x)
x = keras.layers.Dense(5, activation='softmax')(x)
model = keras.Model(inputs=conv_base.input, outputs=x)
model.summary()
# 利用するモデルのtrainableを全てFalseに
conv_base.trainable = False
from keras.preprocessing.image import ImageDataGenerator
train_dir = 対象フォルダのパス
validation_dir = 対象フォルダのパス
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['acc'])
modelCheckpoint = ModelCheckpoint(filepath = 'model_gptimg_resnet50v2_fine.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='min',
period=1)
early_stopping = EarlyStopping(monitor='val_loss', patience=20, verbose=0, mode=auto)
history = model.fit_generator(train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=5,
validation_data=validation_generator,
validation_steps=STEP_SIZE_VALID,
callbacks=[modelCheckpoint, early_stopping])
Epoch 1/5
12/12 [==============================] - ETA: 0s - loss: 3.2070 - acc: 0.8696
Epoch 1: val_loss improved from inf to 0.00002, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_resnet50v2_fine.h5
12/12 [==============================] - 12s 694ms/step - loss: 3.2070 - acc: 0.8696 - val_loss: 2.0970e-05 - val_acc: 1.0000
Epoch 2/5
12/12 [==============================] - ETA: 0s - loss: 0.9242 - acc: 0.9783
Epoch 2: val_loss improved from 0.00002 to 0.00000, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_resnet50v2_fine.h5
12/12 [==============================] - 7s 572ms/step - loss: 0.9242 - acc: 0.9783 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 3/5
12/12 [==============================] - ETA: 0s - loss: 0.8181 - acc: 0.9837
Epoch 3: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 514ms/step - loss: 0.8181 - acc: 0.9837 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 4/5
12/12 [==============================] - ETA: 0s - loss: 0.0546 - acc: 0.9922
Epoch 4: val_loss did not improve from 0.00000
12/12 [==============================] - 7s 554ms/step - loss: 0.0546 - acc: 0.9922 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 5/5
12/12 [==============================] - ETA: 0s - loss: 0.3454 - acc: 0.9946
Epoch 5: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 504ms/step - loss: 0.3454 - acc: 0.9946 - val_loss: 0.0000e+00 - val_acc: 1.0000
5epochの段階でvalidationの正解率が100%ですね。。。
追加学習は不要ですが、念のため実施します。
layer_names = []
for layer in model.layers[5:-5]:
print(layer.name)
layer_names.append(layer.name)
idx = layer_names.index('conv5_block1_preact_bn')
print(idx)
model.trainable = True
for layer in model.layers[:idx]:
layer.trainable = False
# trainableの確認
for l in model.layers:
print(l.name, l.trainable)
modelCheckpoint = ModelCheckpoint(filepath = 'model_gptimg_resnet50v2_fine.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='min',
period=1)
early_stopping = EarlyStopping(monitor='val_loss', patience=20, verbose=0, mode='auto')
history = model.fit_generator(
train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=100,
validation_data=validation_generator,
validation_steps=STEP_SIZE_VALID,
callbacks=[modelCheckpoint, early_stopping])
Epoch 1/100
12/12 [==============================] - ETA: 0s - loss: 0.4054 - acc: 0.9918
Epoch 1: val_loss improved from inf to 0.00000, saving model to C:\Users\llstr\OneDrive\デスクトップ\train\chatgpt_img\model\model_gptimg_resnet50v2_fine.h5
12/12 [==============================] - 7s 612ms/step - loss: 0.4054 - acc: 0.9918 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 2/100
12/12 [==============================] - ETA: 0s - loss: 0.0516 - acc: 0.9946
Epoch 2: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 486ms/step - loss: 0.0516 - acc: 0.9946 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 3/100
12/12 [==============================] - ETA: 0s - loss: 1.1398 - acc: 0.9864
Epoch 3: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 531ms/step - loss: 1.1398 - acc: 0.9864 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 4/100
12/12 [==============================] - ETA: 0s - loss: 0.5204 - acc: 0.9891
Epoch 4: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 469ms/step - loss: 0.5204 - acc: 0.9891 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 5/100
12/12 [==============================] - ETA: 0s - loss: 0.0589 - acc: 0.9946
Epoch 5: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 468ms/step - loss: 0.0589 - acc: 0.9946 - val_loss: 0.0000e+00 - val_acc: 1.0000
・
・
・
Epoch 20/100
12/12 [==============================] - ETA: 0s - loss: 1.3574 - acc: 0.9922
Epoch 20: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 493ms/step - loss: 1.3574 - acc: 0.9922 - val_loss: 0.0000e+00 - val_acc: 1.0000
Epoch 21/100
12/12 [==============================] - ETA: 0s - loss: 0.1941 - acc: 0.9946
Epoch 21: val_loss did not improve from 0.00000
12/12 [==============================] - 6s 474ms/step - loss: 0.1941 - acc: 0.9946 - val_loss: 0.0000e+00 - val_acc: 1.0000
案の定、こちらも早期段階でEarlyStoppingがかかっています。
先ほどと同様に学習の推移を確認すると
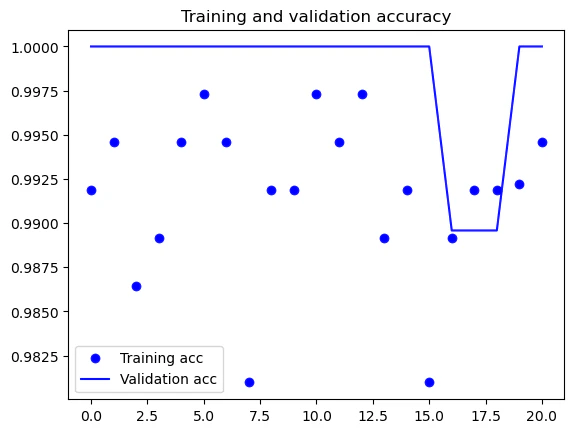
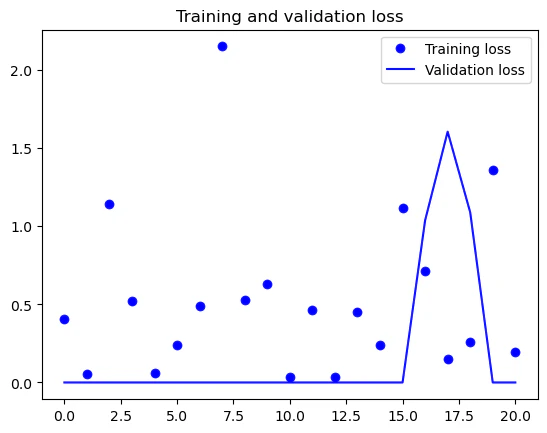
accはvalidationの方が高く、lossはvalidationの方が低い結果になっていることから、過学習は起きておらず上手く学習できているのではと思います。
テストデータで評価
crab(蟹)
crab_test1.jpg
|
crab_test2.jpg
|
deer(鹿)
deer_test1.jpg
|
deer_test2.jpg
|
dolphin(イルカ)
dolphin_test1.jpg
|
dolphin_test2.jpg
|
flamingo(フラミンゴ)
flamingo_test1.jpg
|
flamingo_test2.jpg
|
monkey(サル)
monkey_test1.jpg
|
monkey_test2.jpg
|
これら10枚を、それぞれのモデルで評価してみます。
# VGG
crab_test1.jpg
predict:1(deer)
crab_test2.jpg
predict:1(deer)
deer_test1.jpg
predict:1(deer)
deer_test2.jpg
predict:1(deer)
dolphin_test1.jpg
predict:2(dolphin)
dolphin_test2.jpg
predict:1(deer)
flamingo_test1.jpg
predict:3(flamingo)
flamingo_test2.jpg
predict:1(deer)
monkey_test1.jpg
predict:4(monkey)
monkey_test2.jpg
predict:4(monkey)
ちょこちょこ間違えていますね。。。
過学習の傾向が見えていたので仕方ないですが。
今回は詳細は割愛しますがGrad-Camでも確認してみました。
※Grad-Camについては下記記事などを参考にして下さい。
転移学習・ファインチューニングとは【Python】
https://dajiro.com/entry/2020/06/26/234720
AIは建物のどこを見て築年代を予測するのか|Grad-CAMによる画像判断根拠の可視化
https://club.informatix.co.jp/?p=15061#:~:text=Grad%2DCAM%E3%81%AF%E5%8F%AF%E8%A6%96%E5%8C%96%E6%89%8B%E6%B3%95,%E3%81%95%E3%81%9B%E3%82%8B%E3%81%93%E3%81%A8%E3%81%8C%E3%81%A7%E3%81%8D%E3%81%BE%E3%81%99%E3%80%82
heatmap = make_gradcam_heatmap(入力画像, 判定モデル, last_conv_layer_name=最後の畳み込み層の名前, pred_index=入力画像の推論ラベル)
と与えることで、モデルが画像のどの辺りを見て推論結果を出したかの判断根拠を、ヒートマップとして確認することができます。
crab(蟹)
crab_test1.jpg
|
crab_test2.jpg
|
deer(鹿)
deer_test1.jpg
|
deer_test2.jpg
|
dolphin(イルカ)
dolphin_test1.jpg
|
dolphin_test2.jpg
|
flamingo(フラミンゴ)
flamingo_test1.jpg
|
flamingo_test2.jpg
|
monkey(サル)
monkey_test1.jpg
|
monkey_test2.jpg
|
Grad-Camの使い方としては、判定したい対象が赤色や黄色箇所と重なっていれば妥当そう(特徴を学習できていそう)と考えることができます。しかし、前提として推論結果が正しくなければ意味がないため、推論結果が正しいかどうかとGrad-Camの結果両方を加味して判断します。
今回、正解しているサルは妥当そうですが、蟹の右の画像(crab_test2.jpg)やフラミンゴの右の画像(flamingo_test2.jpg)は推論結果が間違えており、Grad-Camの結果を見ても対象以外の箇所にも反応しているように見えます。今回は過学習をしたモデルで判定したため、推論結果もGrad-Camの結果も妥当ではないものが確認できました。
では次に、過学習はしていないResNetの結果を見てみましょう。
# ResNet
crab_test1.jpg
predict:0(crab)
crab_test2.jpg
predict:0(crab)
deer_test1.jpg
predict:1(deer)
deer_test2.jpg
predict:1(deer)
dolphin_test1.jpg
predict:2(dolphin)
dolphin_test2.jpg
predict:2(dolphin)
flamingo_test1.jpg
predict:3(flamingo)
flamingo_test2.jpg
predict:3(flamingo)
monkey_test1.jpg
predict:4(monkey)
monkey_test2.jpg
predict:4(monkey)
なんと、全て正解していますね。
このように、学習時の正解率と損失の推移を見ることはとても重要で、推移によって過学習か否かの判断が可能です。
(VGGは過学習していますが、本来は「early_stopping」で回避すべきものなので、「early_stopping」する「epoch」数が「20」では多かったと考えられます。。。)
では、最後にGrad-Camを見てみましょう!
crab(蟹)
crab_test1.jpg
|
crab_test2.jpg
|
deer(鹿)
deer_test1.jpg
|
deer_test2.jpg
|
dolphin(イルカ)
dolphin_test1.jpg
|
dolphin_test2.jpg
|
flamingo(フラミンゴ)
flamingo_test1.jpg
|
flamingo_test2.jpg
|
monkey(サル)
monkey_test1.jpg
|
monkey_test2.jpg
|
VGGの結果と比べると、ResNetの方が対象に対して反応していることが分かります。
deer_test1.jpgやflamingo_test2.jpgは、複数いる中の正面を向いている対象のみに反応し、それ以外には反応していません。これは、多種多様な方向を向いている画像を学習データに加えれば解消するかもしれません。しかし、複数の対象を認識したいのであれば、CNNではなく「YOLO」などの「物体検出」を用いた方が適していると思います。
終わりに
とりあえず画像生成して何かしようと思い、本記事のようなことを行いましたが、予想通りしっかり学習できましたね。目視でも本物の写真と違いが分からないレベルなので、当たり前かもしれませんが。。。
とにかく、生成モデルは凄いですね!
一層、「diffusion model」を理解して動かしたいと思いました。これも何番煎じか分かりませんが、「diffusion model」も記事にできればと思います。
それでは、本記事が何かの参考になれば幸いです。