EMNIST-lettersを学習させました。
— mbotsu (@mb_otsu) September 17, 2020
CODE: https://t.co/D3bP7tHq9U
DEMO: https://t.co/8c20CEzLpC pic.twitter.com/gr66WGkQRi
EMNISTは2017年にNISTが公開したデータセットになります。
-
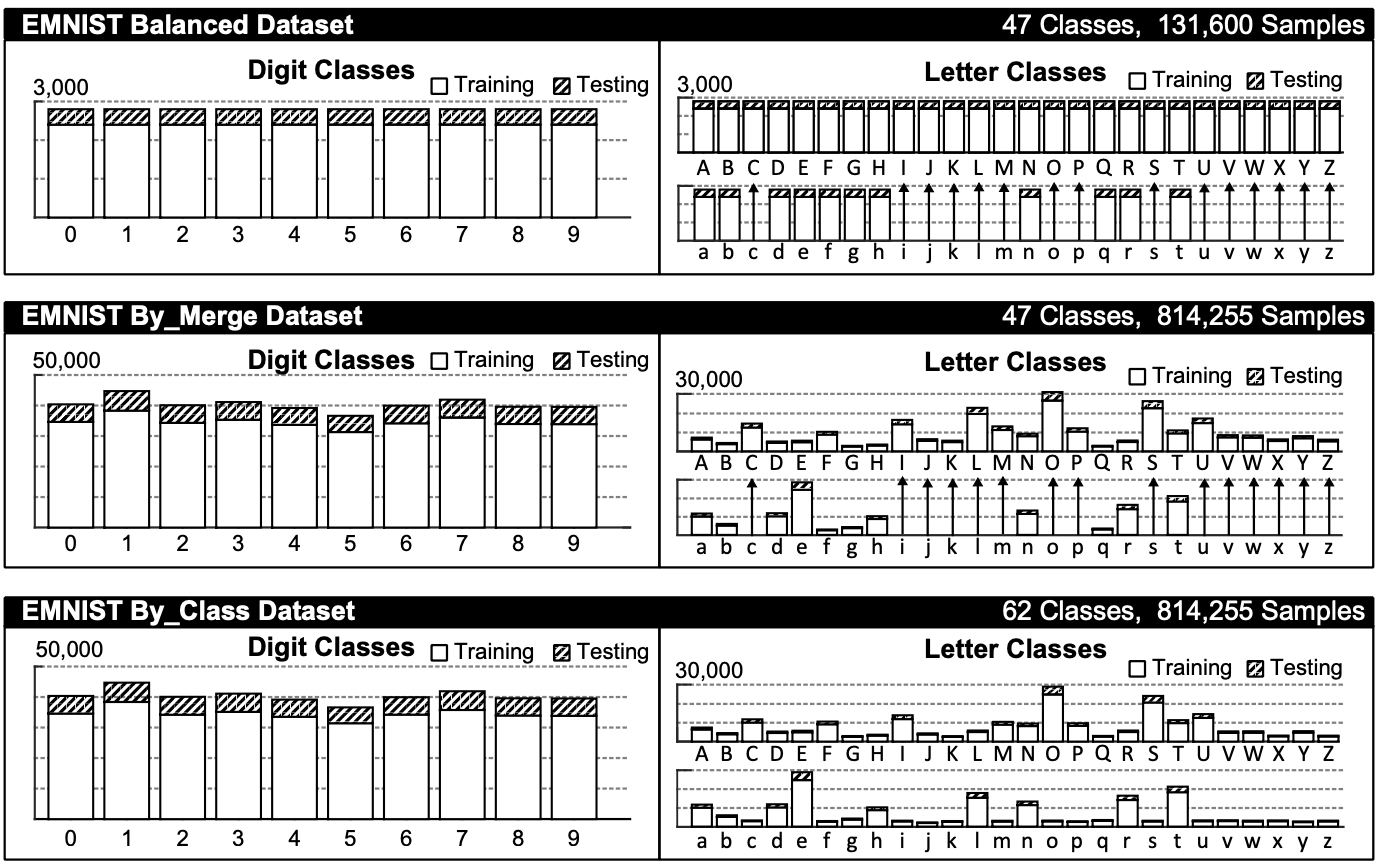
EMNIST ByClass: 814,255 characters. 62 unbalanced classes.
-
大文字(26) + 小文字(26) + 数字(10)
-
EMNIST ByMerge: 814,255 characters. 47 unbalanced classes.
-
EMNIST Balanced: 131,600 characters. 47 balanced classes.
- ByMergeとBalanced
大文字(26) + abdefghnqrt(11) + 数字(10)
大文字と被るcijklmopsuvwxyzを省いたもの。
ブレンド具合は下記図を参照
- ByMergeとBalanced
-
EMNIST Letters: 145,600 characters. 26 balanced classes.
-
大文字と小文字のセット(26)
-
EMNIST Digits: 280,000 characters. 10 balanced classes.
-
EMNIST MNIST: 70,000 characters. 10 balanced classes.
-
DigitsとMNISTは元のMNISTと互換性のある手書き数字
はまりどころ
- TensorFlowのデータセットでうまく認識しない?
当初、TensorFlowのデータセットを使ったのですが手書き文字が認識しませんでしたので元のEMNIST-lettesのデータを使いました。
これについては結論は出ていませんがラベルに対してデータ数が少ないのが原因かもしれません。んー
| train | test | Label | |
|---|---|---|---|
| EMNIST-lettes | 124,800 | 20,800 | 26 |
| TensorFLow | 88,800 | 14,800 | 37 |
- EMNIST-lettesはラベルが1から始まる問題
byclassは0から始まりますがlettersは1から始まりました。
トレーニングにはtf.data.Dataset.from_tensor_slicesを使いましたので、0から始めないとラベル数が正しく扱えませんので調整を行いました。
x_train, y_train = extract_training_samples("letters")
np.unique(y_train)
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26], dtype=uint8)
y_train = y_train - 1
np.unique(y_train)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25], dtype=uint8)
全体の処理
基本的な処理はKerasを使用したMNISTでのニューラルネットワークのトレーニングを参照しました。
WEBでの表示やモデルはHow to distribute a Tensorflow model as a JavaScript web appを参照しました。
今回試したコードはGitHubに上げています。
以上。後に調べる方の参考になればと思います。
後日譚 (2020/10/02)
EMNIST:手書きアルファベット&数字の画像データセットにtfdsのデータはtransposeが必要とあったので試してみたら認識するようになった。
実験ノート
https://gist.github.com/mbotsu/bf4d16df4020b9c3630e0ccae32d5a88