この記事はHowtelevision Advent Calendar 2022 17日目の記事です。
16日目はryo_fujiwaraさんの「外資就活チームのスクラム開発 ~この半期でチームで変えたこと~」 でした。
手始めに
これは数字アレルギーの文系非エンジニアが、「エンジニアの皆さんの手を借りず自身でデータを出せるようになりたい!」(エンジニアにはなるべく開発に専念いただきたい!)という思いから、元エンジニアの同僚の手を借りながら、なんとかかんとかRedushを使えるようになるまでを描いたお話です。
自己紹介
わたくしオカモトは、ハウテレビジョンのプロダクト開発部・外資就活開発チーム内で、事務方のもろもろの業務を担当しています。エンジニアの皆さんと席を並べて一緒に仕事をしてはいますが、上述の通り、超数字アレルギーです。
きっかけは
そんな、超ド文系・数字アレルギー人間が、なぜRedashを使うようになったのかをお話していきます。
皆さまもご存じの通り、仕事というものは、色んな部分に派生していくものです。
重複データを削除したいとか、古くなったデータを刷新したいとか、自分の担当範囲内でも色んな問題が出てきます。
最初はエンジニアさんにあのデータが欲しい、このデータを取りたいとお願いをしていたのですが、エンジニアの方に何でもかんでも頼み続けるのは少し気が引けてしまっていました。
そんな時、当時、同じチーム内にいた先輩から「Redashを使えば自分で取ってこられますよ」と教えていただきました。
なるほど、自分でデータを取れるようになればいいんですね!
IT企業の社員としては当たり前の考え方かもしれませんが、当時の私には目からうろこのご提案でした。
外国語かな
そんなわけで、Redashを使えるようになろうという挑戦が始まりましたが…。
Redash?
なんだっけ???
そういえば、入社時にそういうのに登録したような…?
という薄っすらぼんやりな記憶を引っ張り出し、Redashを開いてみるも、最初のページからちんぷんかんぷんでした。いったん、ページをそっと閉じたことは言うまでもありません…。
オカモト:えっと、これはなんでしょう…?
先輩:SQLを使ってクエリを作成して、データをダウンロードしてくることが出来るツールです。
お察しかと思いますが、ド文系人間は、この時点ですでに脳みそフリーズです。
SQLって何?
クエリを作成とは!?
仰ってることが、非エンジニアにとっては外国語です。全然理解できませんでした。
Resashの使い方もそうですが、そもそもSQLの式の書き方もわからないのです。
チームメイトが元エンジニアだった
さてどうしようか、と眉間にしわで横を見れば、チームメイトのワシヅカさん(前職エンジニア)。
そうです、ワシヅカさんは元エンジニアなのです!
見ればサクサク色んなデータ落としてきていらっしゃる!!
ワシヅカさん、私にRedashの使い方を教えてください🙇🏻 🙇🏻 🙇🏻!!!
というわけで、脳内にカラスが飛んでいるオカモトを見かねたチームメイト・ワシヅカさんによるRedashレクチャーが始まったのでございます。(ありがとうございます!!)
イメージと基本
ワシヅカさん曰く、「Excelを理解していれば同じ感じでイメージすればいいです。列と行で箱が並んでいて、それを指定して取ってくる感じです。」とのことでした。
なるほど。つまりこういうことでしょうか。

ビッグデータとExcelだと規模は違うものの、要するにこういうことらしいので、ピンポイントで指定してあげれば、ちゃんと欲しいデータを運んできてくれるのだそうです。すごいですね…。
ざっくりしたイメージは理解できました。
でも、じゃあ、どうお願いしたら、そのデータを運んできてもらえるのか。
そこが問題なのです。
私はSQL言語が全く書けません。
必要なのは、とある重複IDデータのリスト。それを一覧化したいというのが今回の挑戦です。
ワシヅカ:これらの命令文をくっつければOKです。
SELECT
- どの列(カラム)がほしい?
- 全部の列がほしいときは「*」を指定すればOK
FROM
- どのテーブルから?(イメージ:なんという名前のExcelシートから?)
WHERE
- ほしい列の条件は?
これだけ見ても、私には全くわかりません。
習うより慣れよ!とりあえずやってみれば、覚えられるだろうと、Redashを使ってみることにしました。
How to
- まずはCreateボタンをクリック。
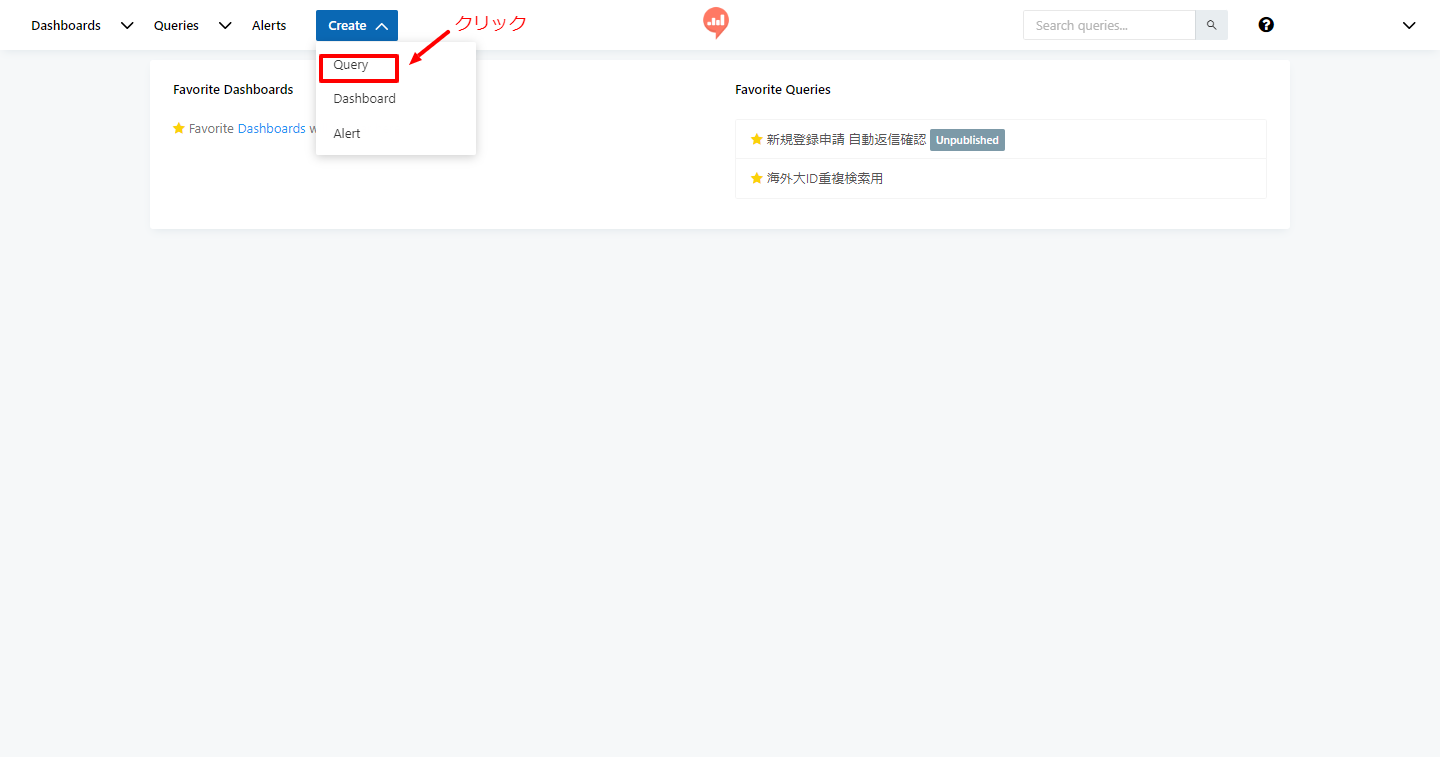
- そこからQueryを選びます。
- 1行目から入力していきます。
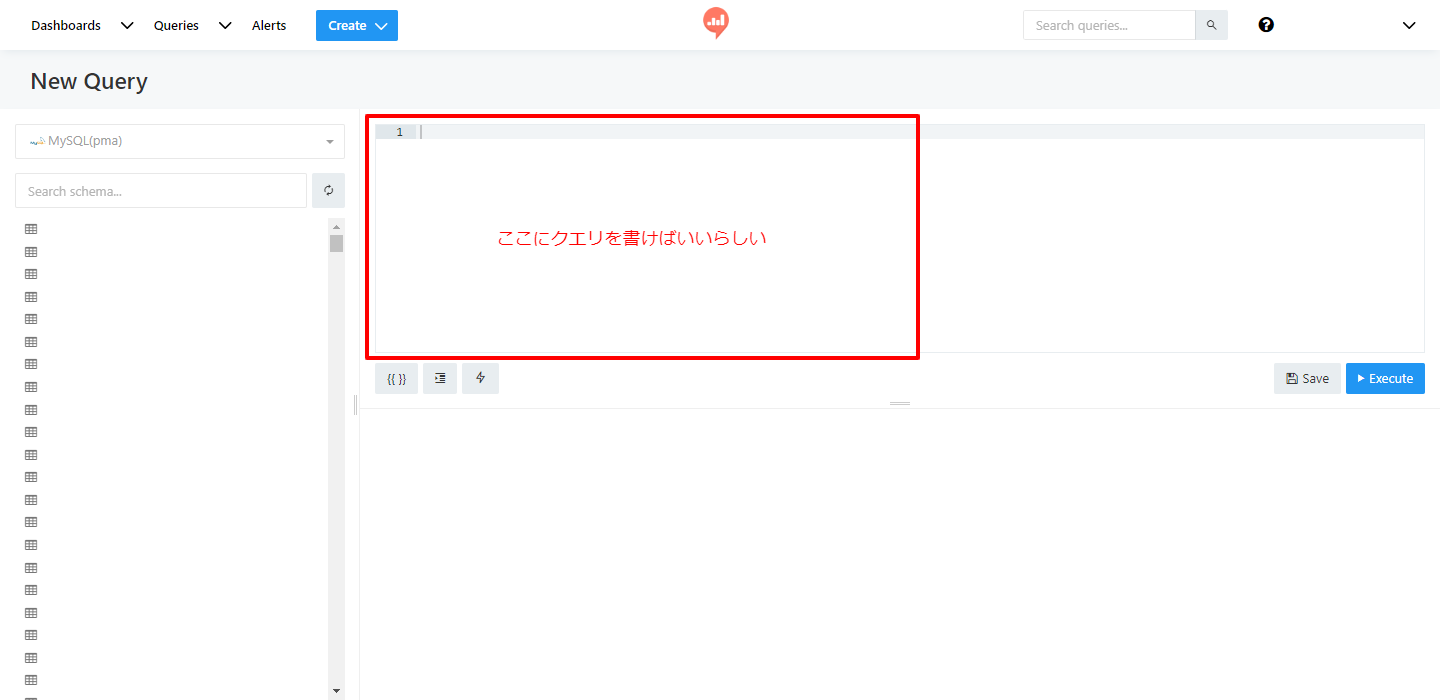
- 1行目はSELECT。ここでは欲しい列(カラム)を指定します。SELECTの後に半角スペース、そのあと列名です。今回は全部欲しいので、「*」を入力します。
- 2列目はFROM。どのテーブルから取ってきたいかを指定します。FROMの後に半角スペース、そのあとテーブル名します。
- 3列目はWHERE。欲しい列の条件を指定します。WHEREの後に半角スペース、そのあと列の条件を入力します。
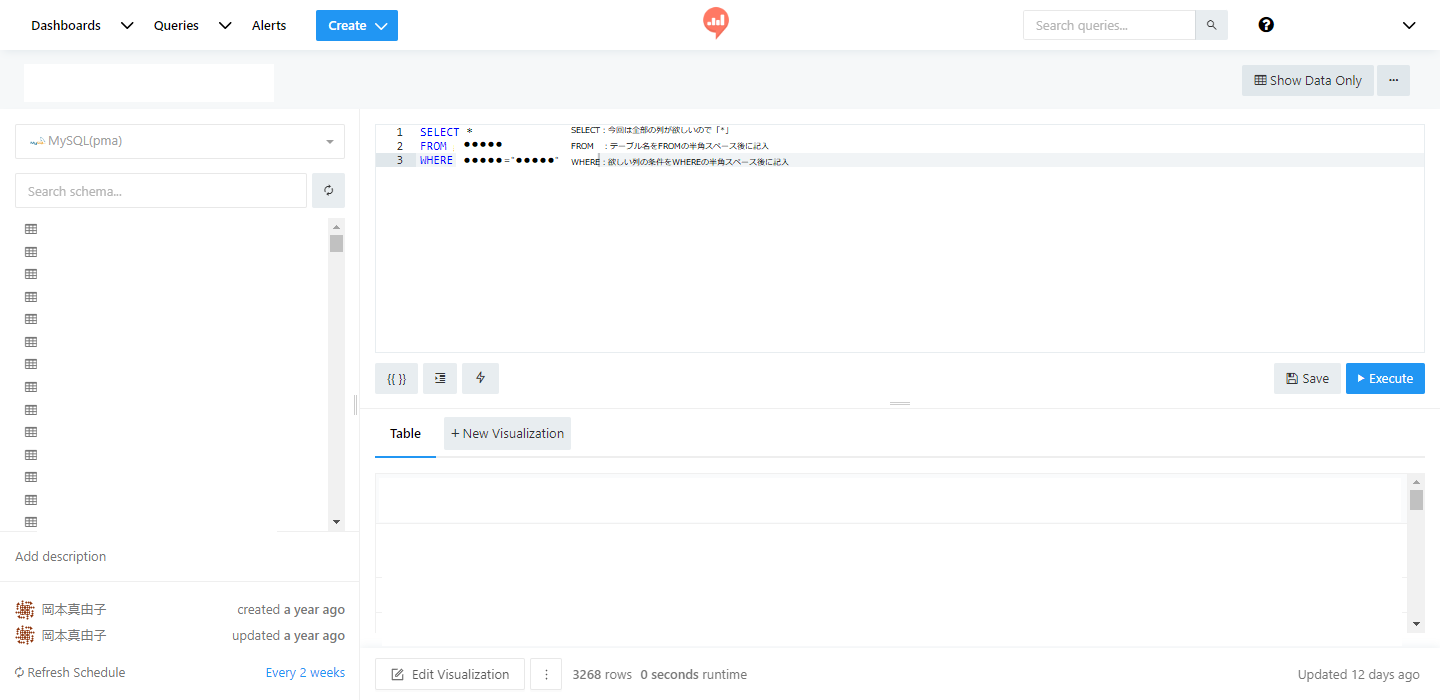
- 構文が出来上がったら、右下の”Execute”をクリックすると、下の段に欲しいデータが表示されます。
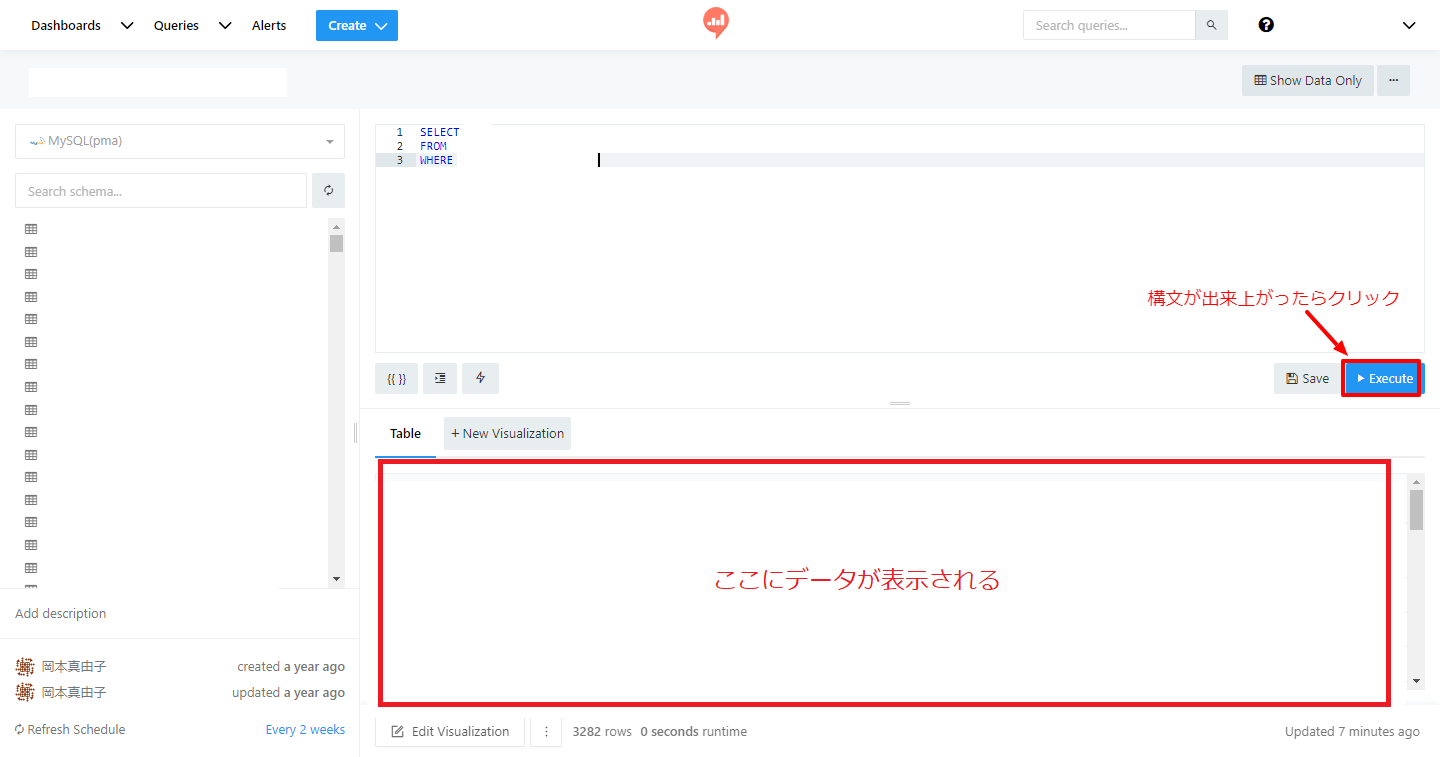
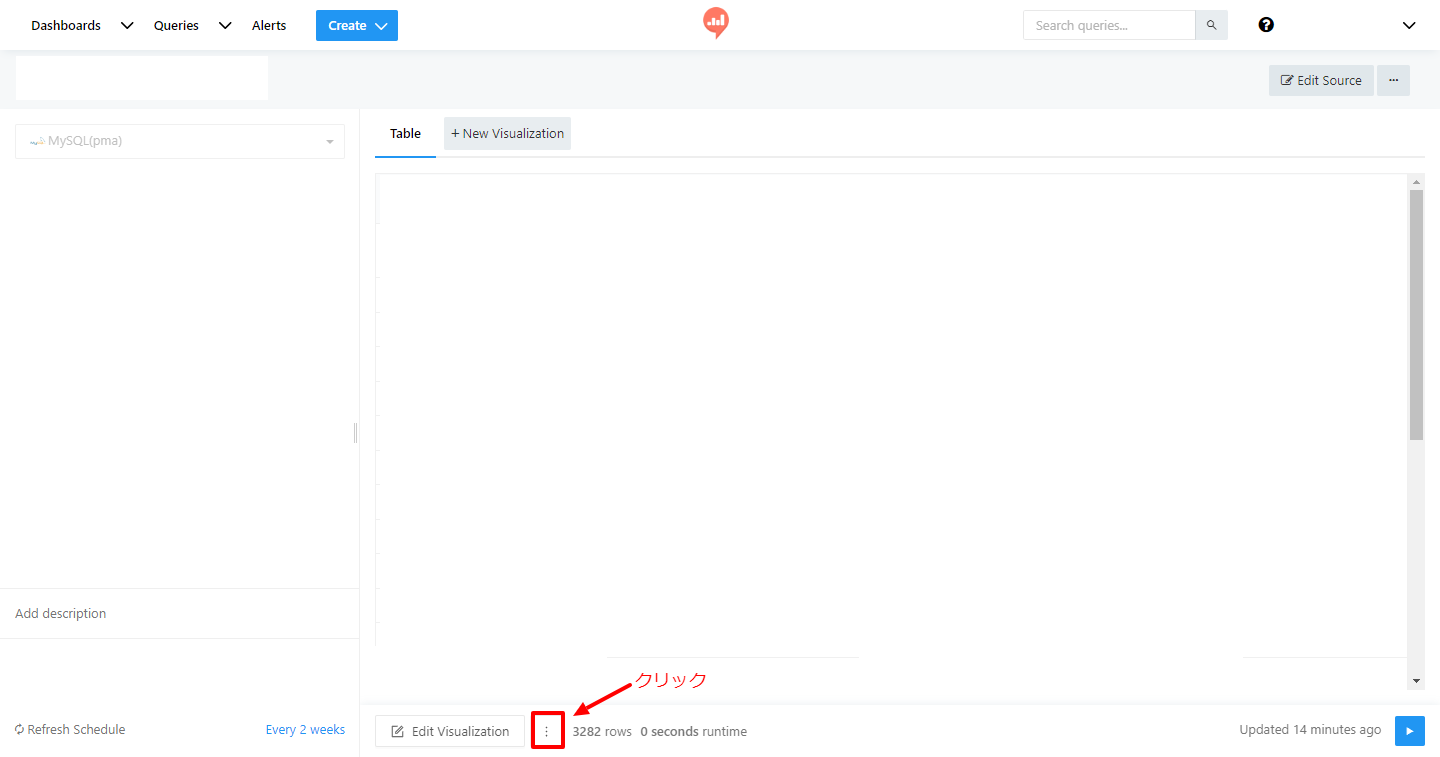
- ここからデータをダウンロードしたいので、今度は”Edit Visualization”の右横にある「…」をクリック→”Download as CSV File”を選べばOK
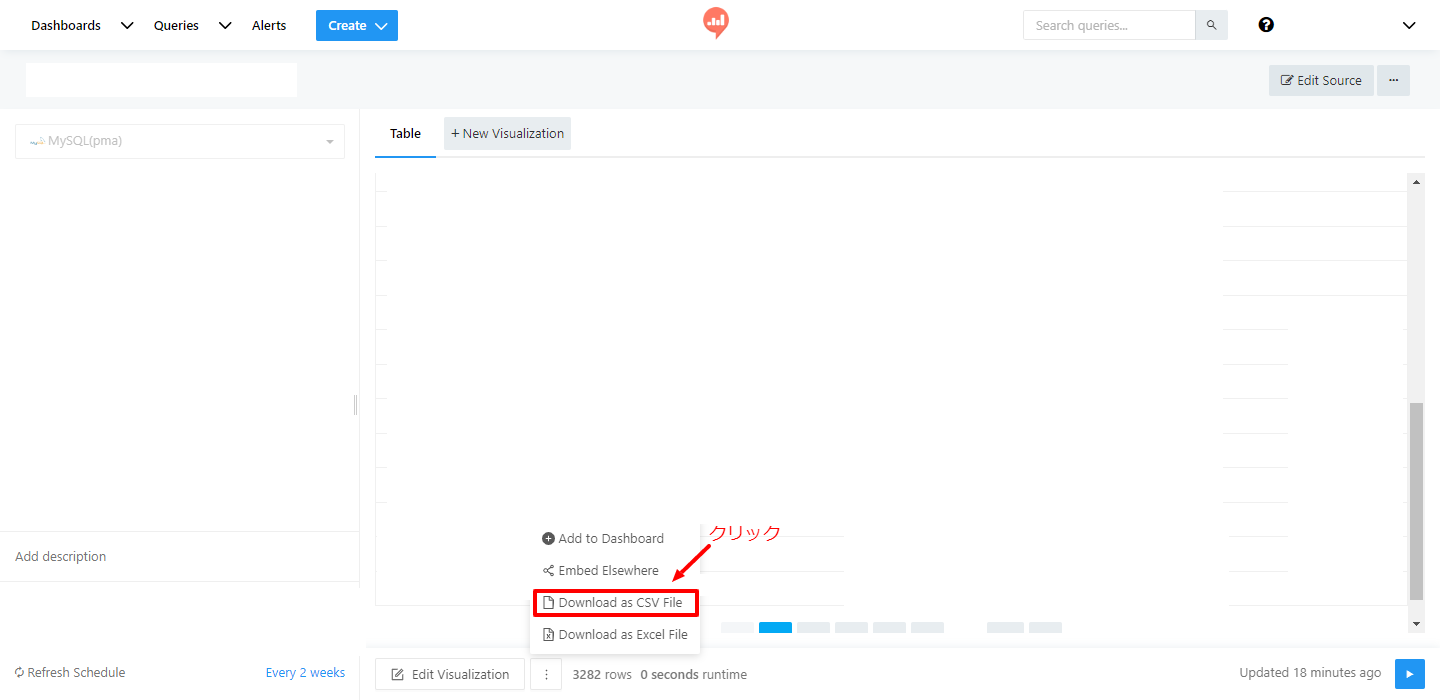
実際にやってみれば、きちんとデータを取ってくることが出来ました。物凄い感動です。
一度作ったクエリはお気に入りに保存しておけば、更新するだけで最新データが取って来られるとのことで、さっそく作ったばかりのクエリをにタイトルを付けて、お気に入りに保存するところまで完了しました。
なんと便利なツールなのでしょう!
というわけで、無事に重複データのリストを作ることができたのでした(ほとんどワシヅカさんのおかげです)。
無事に落としてきたデータは重複解消に使用し、今も定期的に同作業は行っています。
その後
その後、都度更新が必要なデータなどもあり、ちょくちょくRedashを使っています。
(個人的にオカモトは、SQLの超入門編をまとめてくださっている動画など見て、若干勉強もしてみたり、それをnotionにまとめてみたりもしています。)
他チームの文系職種の方々もそうですが、「わざわざエンジニアさんにお願いしなくても、自分で出来そうなことは自分でやる。エンジニアさんの時間を奪わない」がハウテレビジョンの文系職種の共通理念になっているような気がします。
そのうえで、さすがにこれは自分には難しいと感じる時は、ハウテレビジョンにはSQL質問用のslackチャンネルがあるので、「これで合っていますか?」と構文を投げます。そうすると、エンジニアさんが回答してくれるという仕組みです。このチャンネルの存在は、勉強にもなりますし、ありがたいかぎりです。
弊社の良いところは、職種による垣根が低いということです。
割とどんな方でもフランクにお話しくださるので、聞きたいことを気軽に聞くことができます。
悩んで呟けば、だいたい誰かレスして下さるのです。これはとても嬉しいポイントだと思います。
エンジニアも非エンジニアも仲良く一緒に生息できるハウテレビジョンをどうぞよろしくお願いします🤗。