はじめに
ここでは私が今進めている
レンダリング画像をVLM解析し、プロシージャルリギング用タグを自動生成する
ワークフローの冒頭部分に当たる
PDGのUSD Render Files TOP nodeを使って
バッチレンダリング、対象のhipファイルを開かずに大量レンダリングをし
その画像をVLMで辞書データ化するまでのワークフローを紹介します。

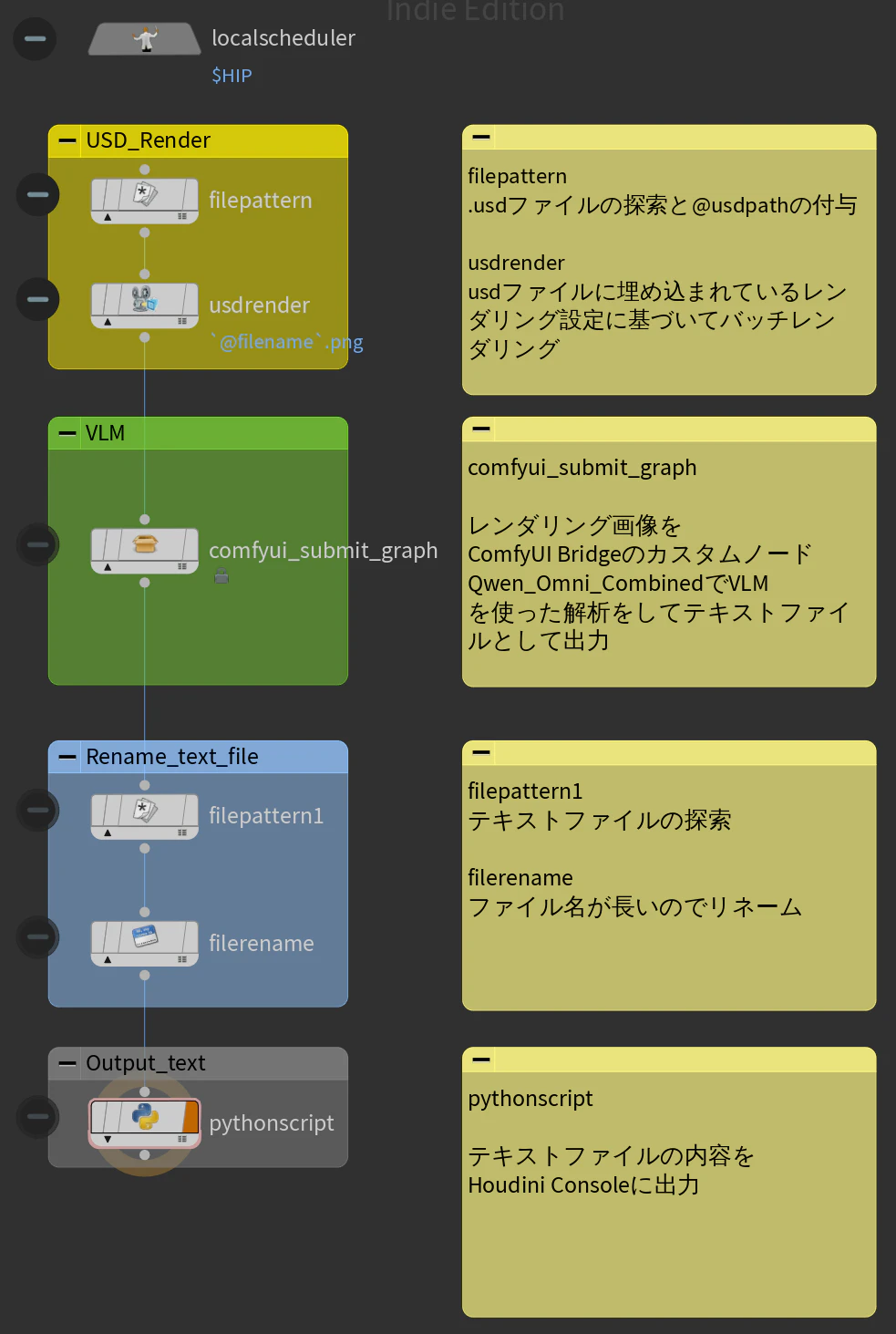
全体ワークフローの略図と注意
キャラクター画像のバッチレンダリング
↓
VLM 今回はここまで
↓
タグ(JSON)
↓
プロシージャルリギング
ComfyUI Bridgeの導入や、PDGを使ったファイルのリネーム方法ついてはこちらを参考にしてください
*注意
2026.06.02現在、Houdini Production Build 21.0.671で正常動作を確認
私の環境ではHoudini Production Build 21.0.700以降では
ComfyUIのノードにエラーが発生し
PDGのComfyUI Submit Graph TOPが動作しないことを確認
LLMとVLMとは
LLM(Large Language Model)は、大量のテキストを学習し、人間のように文章を理解・生成できるAIです。ChatGPTなどが代表例で、主にテキストを入力としてテキストを出力します。
テキスト
↓
LLM
↓
テキスト
一方、VLM(Vision Language Model)は画像を理解できるLLMです。画像とテキストを入力として受け取り、その内容を説明したり、画像内の特徴を抽出したりできます。
画像 + テキスト
↓
VLM
↓
テキスト
ここでは画像説明だけでなく、
{
"character_present": true,
"character_type": "human",
"eyes": true,
"nose": true,
"mouth": true,
"ears": true
}
のような構造化データを出力させます。
必要なComfyUIカスタムノード
ComfyUI-Qwen-Omni
ComfyUI-Qwen-Omniに含まれる、Qwen Omni Combinedを使います

Qwen Omni CombinedのPrompt
あくまで一例
画像を解析し、JSONのみを出力してください。
ルール:
- 同じ情報を複数のキーに書かない
- 同じ内容を繰り返さない
- JSON以外を出力しない
- 生成に40秒以上かかるときはスキップ
{
"スタイル": "",
"キャラクター": {
"種類":""
"雌雄": "",
"毛の色": "",
"衣服": ""
},
"背景": {
"植物": [],
"建物": []
}
}
結果
{
"スタイル": "自然風",
"キャラクター": {
"種類": "犬",
"雌雄": "雌",
"毛の色": "茶白",
"衣服": ""
},
"背景": {
"植物": [
{
"種類": "花",
"色": "白,黄,紫"
},
{
"種類": "草木",
"色": "緑"
}
],
"建物": []
}
}
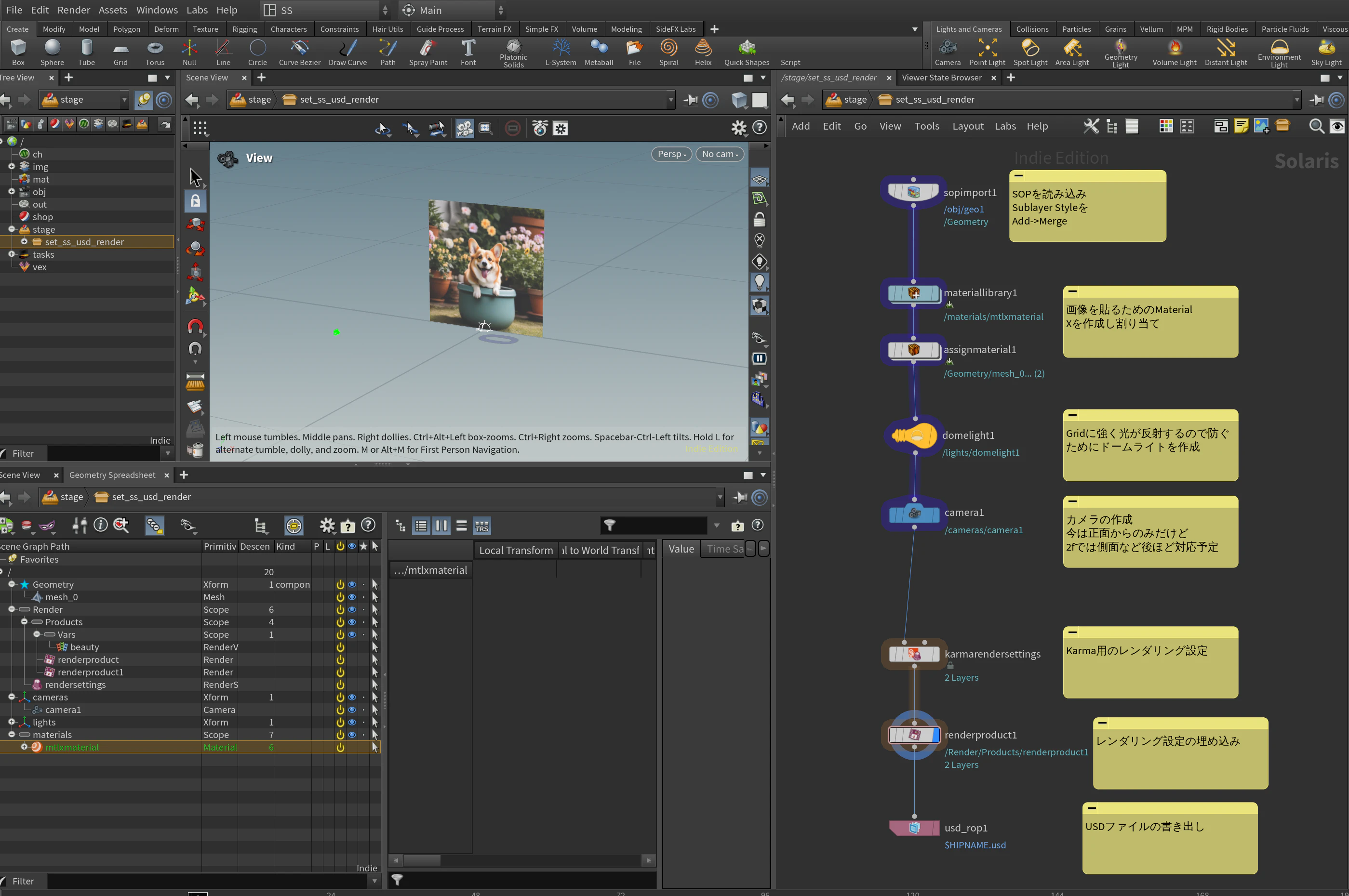
STEP1.バッチレンダリングするためのUSDファイルの書き出し
SOP
実際にはキャラクターのモデル
今回はgridをUV展開し、
SolarisにはSOPのマテリアルは使わないので必要ないですが、確認用のマテリアルをつけてます
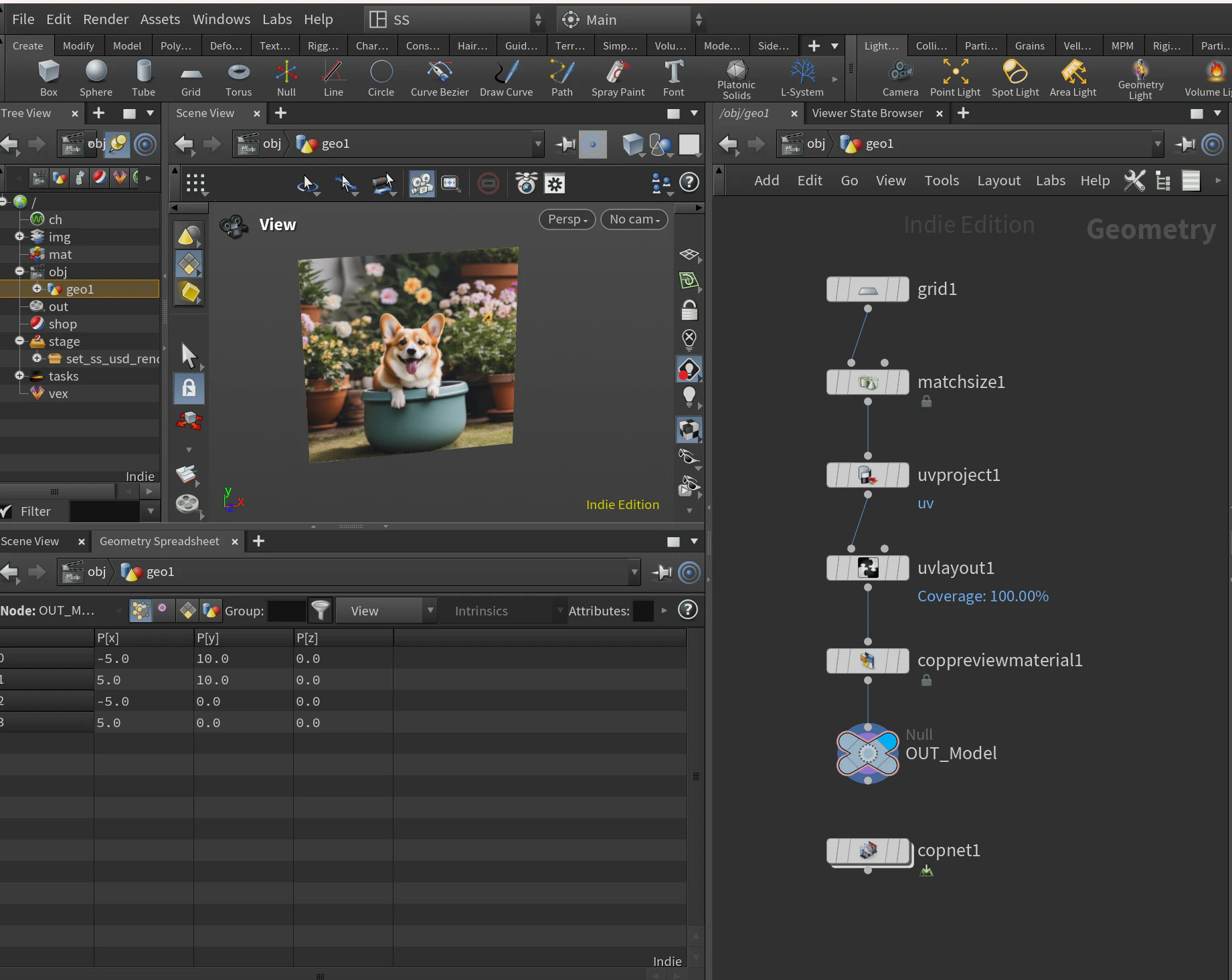
Solaris
複数のキャラクターに対して共通で使うため、HDAの中でUSDファイルを出力する仕組みを作りHDAをロックをしておきます。
一つのHDAを更新したら、共通で使っている他のhipファイルのHDAも自動で更新されるようにするためです。
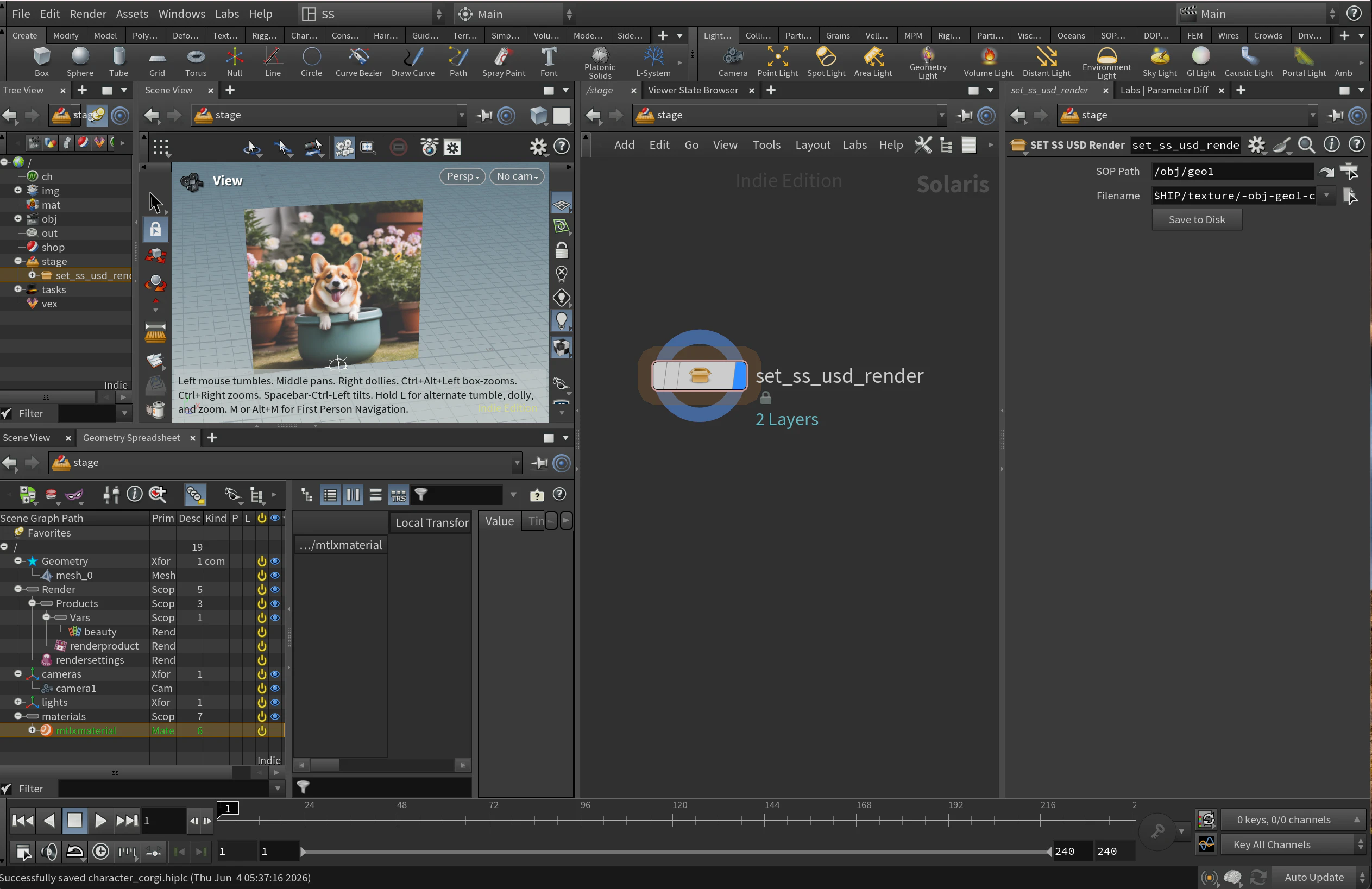
HDAの中身
Solarisに関して、まだ分かってないことが多いですが
なんとかレンダリングするための設定を埋め込んだUSDファイルの書き出しをしました
STEP2.TOPネットワークの構築
HDAにボタンを作成しておいてボタンを押したら、ここの処理が実行されるようにしておくと視覚的に処理が追いやすくなって便利です
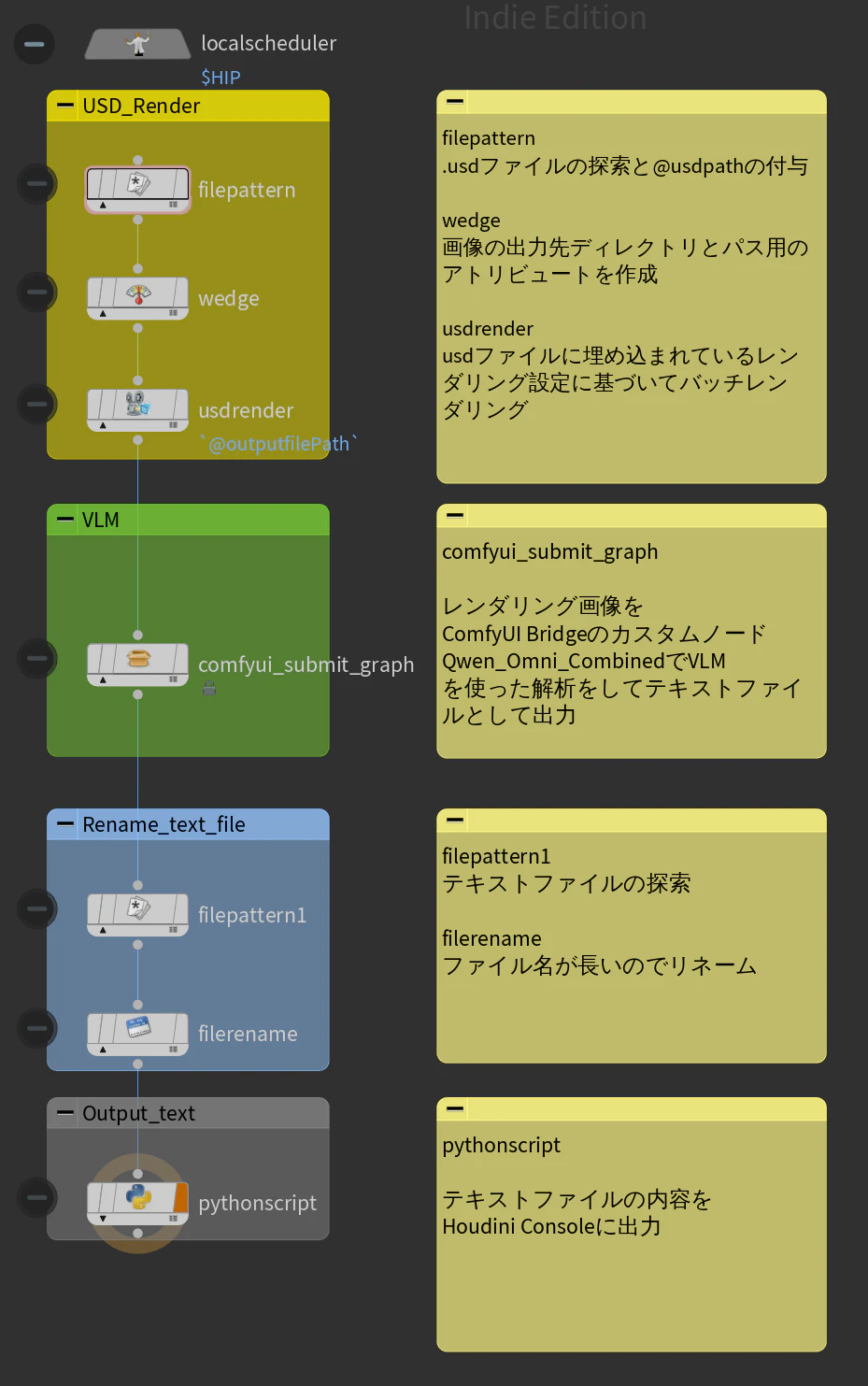
pythonscript
並列処理されるのでこういう書き方になります
file = work_item.inputFiles[0].path
with open(file, "r", encoding="cp932") as f:
text = f.read()
# コードブロック除去
text = text.replace("```json", "")
text = text.replace("```", "")
text = text.strip()
print(work_item.attribValue("filename"))
print(text)
最後に
VLMを使ったワークフローの構築に、取り組み始めたばかりですが
画像をHoudiniですぐに使えるデータに変換できるのは大きなメリットだと感じています。
引き続きVLMを活用し
今まで人の目に頼っていた作業を、どんどん自動化していきたいです。