HumanRig: Learning Automatic Rigging for Humanoid Character in a Large Scale Dataset(Chu, 2023)
3行要約
- 3Dキャラクターアニメーションにおける自動リギングは、大規模で統一されたデータセットの不足と、複雑なAI生成メッシュを扱う上での課題に直面していました。
- 本研究は、11,434のAI生成Tポーズメッシュと統一されたスケルトントポロジーを含む大規模データセット「HumanRig」を構築し、Prior-Guided Skeleton Estimator (PGSE)とMesh-Skeleton Mutual Attention Network (MSMAN)を統合した革新的な自動リギングフレームワークを提案します。
- このデータ駆動型アプローチにより、既存手法を上回る品質と汎用性で、粗密な3Dスケルトン関節の回帰と堅牢なスキニング推定を実現し、アニメーション業界のリギングパイプラインの自動化を促進します。
Q:何が問題で、それをどのように解決したのか、わかりやすく説明してください
A:
問題点
まず、この研究が解決しようとしている問題は、主に以下の3点に集約されます。
-
3Dキャラクターのリギングが非常に大変な作業であること:
- 3Dヒューマノイドキャラクターをアニメーションさせるためには、「リギング」という作業が必要です。これは、キャラクターの内部に骨格(スケルトン)を構築し、その骨がメッシュ(キャラクターの表面)のどの部分にどれくらい影響を与えるか(スキニングウェイト)を設定する工程です。
- 従来、このリギングは、熟練したアーティストが手作業で行うため、非常に時間と労力がかかり、コストも高かったです。
-
自動リギングの学習に必要なデータが不足していること:
- 近年、AIによって3Dモデルを生成する技術が急速に発展し、多くのキャラクターモデルが簡単に作れるようになりました。しかし、これらを自動でリギングするための、大規模で高品質なデータセットが不足していました。
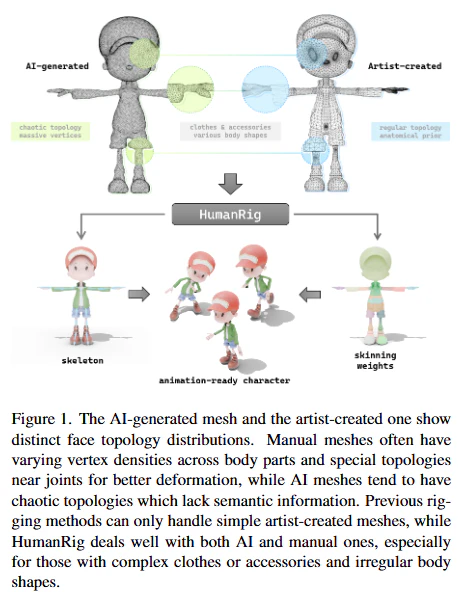
- 既存のデータセットは、規模が小さかったり、スケルトンの構造が統一されていなかったり、リアルな人体形状に限定されていたり、あるいは手作業で作成された単純なメッシュしか含まれていませんでした。特に、AIが生成するような、複雑なトポロジー(頂点や面のつながり方)を持つメッシュや、多様な体型、服装のキャラクターに対応できるデータがありませんでした(図1参照)。
-
既存の自動リギング手法が、複雑なAI生成メッシュに対応できないこと:
- これまでのデータ駆動型自動リギング手法の多くは、GNN(グラフニューラルネットワーク)を用いてメッシュの幾何学的特徴を学習していました。
- しかし、AIが生成するメッシュは、頂点や面のつながり方が不規則で、エッジ情報(辺の情報)が必ずしも意味のあるセマンティック情報(意味的な情報)を含んでいません。このため、GNNベースの手法では、多様な体型、複雑な衣服やアクセサリーを持つAI生成メッシュに対して、正確なスケルトンの構築やスキニングウェイトの予測が困難でした。
解決策
本研究は、これらの課題を解決するために、**「HumanRig」という大規模なデータセットと、「革新的なデータ駆動型自動リギングフレームワーク」**を提案しました。
-
大規模で多様なデータセット「HumanRig」の構築:
- まず、AIの力を借りて、11,434個ものTポーズの3Dヒューマノイドメッシュを生成・収集しました。これらのモデルはすべて、業界標準の「Mixamoスケルトン」という統一された骨格に準拠してリギングされています。
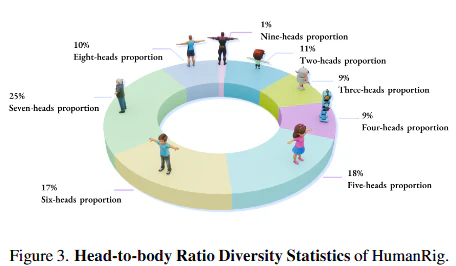
- このデータセットの最大の特徴は、AIが生成した多様な体型、頭身比、複雑な服装やアクセサリーを持つキャラクターを大規模に含んでいる点です(図3参照)。これにより、これまで不足していた「複雑なキャラクターに対応できる」訓練データが提供され、より汎用性の高い自動リギングモデルの学習が可能になりました。
-
複雑なメッシュにも対応する新しい自動リギングフレームワークの提案:
-
HumanRigデータセットを活用し、以下の3つの主要モジュールを組み合わせた新しい自動リギングフレームワークを開発しました(図4参照)。
-
a) Prior-Guided Skeleton Estimator (PGSE) — 事前情報ガイド付きスケルトン推定器:
- キャラクターの「正面画像」から2Dの骨格(2Dジョイント)を検出し、これをカメラ情報を使って大まかな3Dの骨格に投影します。
- これにより、最初から「この辺に骨があるだろう」という強力な事前情報が得られるため、ネットワークがゼロから3D骨格を学習するよりも、はるかに簡単に、かつ正確に初期の骨格位置を推定できるようになります。これは骨格構築の難易度を大幅に下げます。
-
b) U-shaped Point Transformer-based Mesh Encoder — ポイントトランスフォーマーベースのメッシュエンコーダー:
- 従来のGNNが「エッジ(辺)の情報」に依存していたのに対し、このエンコーダーは**「頂点(ポイント)の情報」と「3D空間的な距離関係」**に基づいて、メッシュの特徴を抽出します。
- AI生成メッシュの不規則なエッジ情報に左右されないため、よりロバストに、かつ詳細にキャラクターの形状特徴を捉えることができ、複雑な形状や衣服を持つモデルにも優れた汎化性能を発揮します。
-
c) Mesh-Skeleton Mutual Attention Network (MSMAN) — メッシュ・スケルトン相互アテンションネットワーク:
- メッシュから抽出された詳細な特徴と、骨格から抽出された特徴を、相互に注意(アテンション)を向けさせるメカニズムで統合します。
- これにより、メッシュは「この部分はどの骨格に近いか」というセマンティックな情報を、骨格は「この骨の周囲のメッシュはどんな形をしているか」というローカルな情報を、互いに高め合うことができます。結果として、3D骨格の精密な位置調整と、メッシュ頂点への正確なスキニングウェイトの割り当てを同時に、かつ協調的に最適化することが可能になります。
-
まとめ
この研究は、**「大規模で多様なデータセットの提供」と「複雑なメッシュに強い新しいモデルアーキテクチャ」**という2つの柱で、従来の自動リギングが抱えていた問題を克服しました。これにより、AIが生成したキャラクターであっても、より効率的かつ高品質にアニメーション可能な状態にリギングできるようになり、アニメーション制作の現場に大きな変革をもたらす可能性を秘めています。
Q:この論文の概要を教えてください
A:
本論文は、3Dヒューマノイドキャラクターの自動リギングにおける、包括的なデータセットと堅牢なフレームワークの必要性に対処しています。特に、近年増加している複雑なAI生成メッシュに対応するための課題を解決することを目指しています。
本研究の主な貢献は二点です。
-
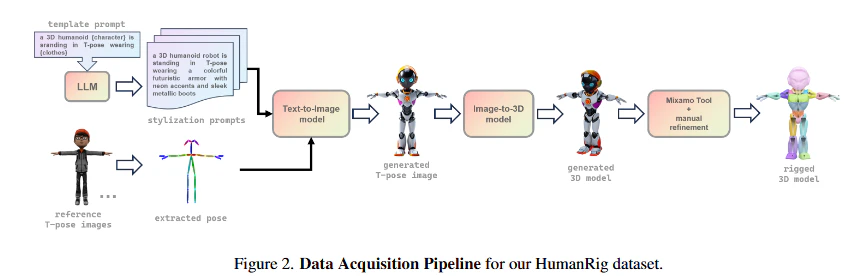
HumanRigデータセットの構築: 自動リギングに特化した初の、大規模なデータセット「HumanRig」を提案します。これは、11,434の細かくキュレーションされたT-poseメッシュを含み、全て均一なMixamoスケルトントポロジーに準拠しています。このデータセットは、AI生成モデルの複雑なトポロジー、多様なボディプロポーション、衣服やアクセサリー、不規則なボディ形状といった課題に対応できる多様性と規模を備えています。従来のデータセット(RigNetv1, SMPLなど)は、規模、多様性、または一貫したスケルトンの欠如といった制限がありました。
-
革新的な自動リギングフレームワークの提案: HumanRigデータセットを活用し、従来のGraph Neural Network(GNN)ベースの手法がAI生成メッシュの複雑なトポロジーに苦戦するという課題を克服する、データ駆動型自動リギングフレームワークを導入します。このフレームワークは、以下の主要モジュールで構成されます。
-
Prior-Guided Skeleton Estimator (PGSE): 2Dスケルトン関節の事前情報を用いて、3Dスケルトンの予備的な位置を推定します。まず、モデルの正面図からRTM-Pose [9]を用いて2Dスケルトン関節$P_{j2D} \in \mathbb{R}^{s \times 2}$を予測します。次に、カメラの射影行列の擬似逆行列$P_c \in \mathbb{R}^{4 \times 3}$とカメラ中心$X_c$を用いて、各2D関節$J_{2D}$を3D空間にレイとして逆投影します。
$$ \tilde{X}r (\mu; J{2D}) = P_c \tilde{J}_{2D} + \mu \tilde{X}c $$
ここで、チルダ記号は同次座標を示します。最後に、各レイとメッシュ表面の交点の中点として粗い3Dスケルトン$P{ske_c} \in \mathbb{R}^{s \times 3}$を決定します。これにより、リギングタスクの複雑さが大幅に軽減されます。 -
Mesh Encoder: 粗いスケルトンとメッシュから特徴量を抽出します。
- Skeleton Encoder: 粗い3Dスケルトンポイントを処理し、MLP(Multi-Layer Perceptron)ベースの3層ネットワークでスケルトン特徴量$f_s \in \mathbb{R}^{s \times c}$を抽出します。
- Point Transformer-based Mesh Encoder: 全ての頂点を抽出し、各頂点に3つの位置座標と粗いスケルトン$P_{ske_c}$に対する$s$個のユークリッド距離特徴を加えたスケルトンアウェアな頂点特徴$f_v \in \mathbb{R}^{m \times (3+s)}$を構築します。この特徴を入力として、U字型Point Transformer [30]が、深層メッシュ特徴量$f_m \in \mathbb{R}^{m \times c}$を抽出します。これは、GNNベースのエンコーダーと比較して、不規則なフェイストポロジーを持つAI生成メッシュに対して優れた汎化性能を発揮します。
-
Mesh-Skeleton Mutual Attention Network (MSMAN): Skeleton Encoderから得られたスケルトン特徴量$f_s$とMesh Encoderから得られたメッシュ特徴量$f_m$を、相互クロスアテンションメカニズムを通じて融合します。これにより、メッシュ頂点の意味的理解が深まり、スケルトン位置の精密な調整が可能になります。例えば、メッシュ特徴量を強化するために、マルチヘッドクロスアテンションを導入します。
$$ Q = f_s; K = f_m; V = f_m $$
$$ f_{m \to s} = \text{softmax} \left( \frac{QK^T}{\sqrt{d}} \right) V $$
ここで、$f_{m \to s} \in \mathbb{R}^{s \times c}$は強化されたスケルトン特徴量です。同様に、メッシュ特徴量にスケルトン特徴量を統合するために、$Q = f_m; K = f_s; V = f_s$を設定し、$f_{s \to m} \in \mathbb{R}^{m \times c}$を得ます。 -
Rigging HeadとTraining Loss: 最終的なスケルトン位置$P_{ske} \in \mathbb{R}^{s \times 3}$とスキニングウェイト$P_{skin} \in \mathbb{R}^{m \times s}$を予測するために、それぞれMLPベースのヘッドを使用します。スケルトン関節の予測にはMean Squared Error (MSE) Lossを、スキニング予測にはKullback-Leibler divergence lossを採用します。
$$ L_{skeleton} = \frac{1}{s} \sum_{i=1}^{s} (P_{ske_i} - G_{ske_i})^2 $$
$$ L_{skinning} = \frac{1}{m} \sum_{i=1}^{m} \sum_{j=1}^{s} P_{skin_{ij}} \log \frac{P_{skin_{ij}}}{G_{skin_{i,j}}} $$
総損失はこれらの組み合わせです: $L_{total} = L_{skinning} + L_{skeleton}$。
-
Prior-Guided Skeleton Estimator (PGSE): 2Dスケルトン関節の事前情報を用いて、3Dスケルトンの予備的な位置を推定します。まず、モデルの正面図からRTM-Pose [9]を用いて2Dスケルトン関節$P_{j2D} \in \mathbb{R}^{s \times 2}$を予測します。次に、カメラの射影行列の擬似逆行列$P_c \in \mathbb{R}^{4 \times 3}$とカメラ中心$X_c$を用いて、各2D関節$J_{2D}$を3D空間にレイとして逆投影します。
実験では、HumanRigデータセットがRigNetv1よりも優れた性能を示し、データセットの規模と多様性(頭身比率を含む)がモデルの性能向上に大きく貢献することを実証しました。また、PGSEとMSMANモジュールがスケルトン構築とスキニング予測の両方において重要な役割を果たすこと、そしてPoint TransformerベースのMesh EncoderがGNNベースのエンコーダーよりも優れていることをアブレーションスタディで示しました。これにより、提案手法が不規則な形状、詳細な衣服やアクセサリー、異なる頭身比率といった課題に効果的に対応し、従来の最先端技術を凌駕する高品質な自動リギングソリューションを提供することが確認されました。
本研究は、リギング研究におけるデータセット不足を解消し、アニメーション業界のより効率的で自動化されたキャラクターリギングパイプラインへの道を拓きます。今後の課題としては、指などの小さな身体パーツのスケルトンテンプレートの考慮や、四足動物や他のオブジェクトへの拡張が挙げられます。
Q:提案手法の処理の流れを順序だてて説明してください
A:
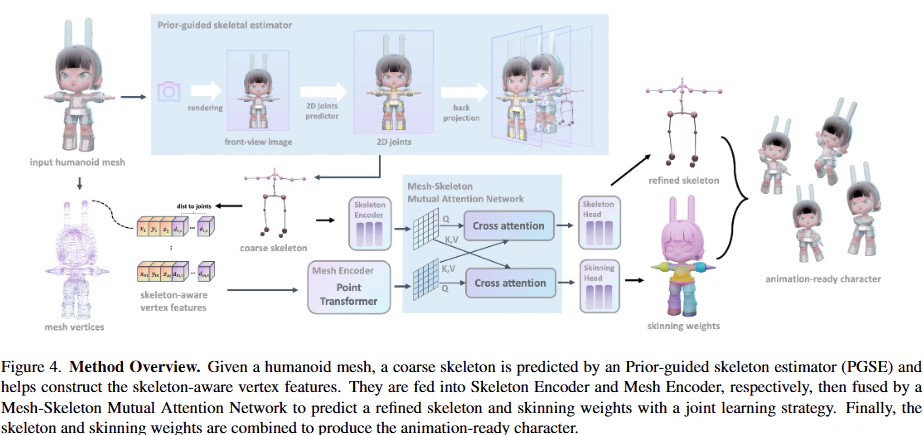
HumanRig 提案手法の処理フロー
このフレームワークは、入力された3Dヒューマノイドメッシュに対して、最終的にアニメーション可能な状態の3Dスケルトンとスキニングウェイトを出力することを目的としています。全体は、大きく以下のステップで構成されます。
- 入力データ準備
- 粗いスケルトンの推定(PGSE)
- スケルトン認識型頂点特徴の構築
- 特徴抽出(スケルトンエンコーダーとメッシュエンコーダー)
- 特徴の相互統合(MSMAN)
- リギングヘッドによる最終予測
- 損失計算と学習
それぞれのステップを詳細に見ていきましょう。
1. 入力データ準備
- 入力: アニメーションさせたいTポーズの3Dヒューマノイドメッシュ(頂点座標、面情報など)と、そのメッシュの正面から撮影した2D画像が準備されます。2D画像を生成する際には、カメラの内部・外部パラメーターも取得します。
2. 粗いスケルトンの推定 (Prior-Guided Skeleton Estimator: PGSE)
このステップでは、2D画像からの事前情報を用いて、大まかな3Dスケルトンの位置を推定します。
-
a. 2Dジョイントの予測:
- まず、入力された3Dメッシュの「正面ビュー画像」に対して、事前に訓練された2Dポーズ推定器(RTM-Pose [9])を適用します。
- これにより、画像内のキャラクターの身体部位に対応する2Dスケルトンジョイントの位置 $P_{j}^{2D} \in \mathbb{R}^{s \times 2}$ を高精度に予測します($s$ はスケルトンジョイントの数、この論文では22に統一)。
-
b. 2Dジョイントの3D空間へのバックプロジェクション:
- 次に、予測された各2Dジョイント $J^{2D}$ を、事前に用意されたカメラパラメーター(射影行列の擬似逆行列 $P_c \in \mathbb{R}^{4 \times 3}$ とカメラ中心 $X_c$)を使って、3D空間上の「レイ(光線)」として逆投影します。
- これは以下の式で表現されます($\tilde{X}_r(\mu; J^{2D})$ は3Dのレイ、$\tilde{J}^{2D}$ と $\tilde{X}_c$ はそれぞれの同次座標です)。
$$
\tilde{X}_r (\mu; J^{2D}) = P_c \tilde{J}^{2D} + \mu \tilde{X}_c
$$
このレイは、2Dジョイントが3D空間のどこかにある可能性のある線を示します。
-
c. 粗い3Dスケルトン位置の決定:
- 各レイと3Dメッシュ表面との「交点」を計算します。
- 通常、1つのレイはメッシュと複数の点で交差する可能性があります。PGSEでは、その最初と最後の交点の中間点を計算することで、対応する粗い3Dスケルトンジョイント $P_{ske}^{c} \in \mathbb{R}^{s \times 3}$ の位置を決定します。
- これにより、メッシュの内部にあり、かつキャラクターの解剖学的構造に沿った、初期の3Dスケルトン位置が推定されます。
3. スケルトン認識型頂点特徴の構築
- PGSEによって推定された粗い3Dスケルトン $P_{ske}^{c}$ は、後続のメッシュ特徴抽出の精度を高めるために活用されます。
- 各メッシュ頂点 $m$ に対して、その3D位置座標に加えて、粗い3Dスケルトンの各ジョイント $s$ からのユークリッド距離を特徴として追加します。
- これにより、各頂点の初期特徴 $f_v \in \mathbb{R}^{m \times (3+s)}$ は、$3$ 次元座標と $s$ 個の距離特徴(合計 $3+s$ 次元)を持つ、「スケルトン認識型」の頂点特徴となります。これは、頂点がどの骨格に近いかという局所的なセマンティック情報を提供します。
4. 特徴抽出(スケルトンエンコーダーとメッシュエンコーダー)
異なるタイプの入力に対して、それぞれ専用のエンコーダーを用いて特徴を抽出します。
-
a. スケルトンエンコーダー (Skeleton Encoder):
- PGSEで得られた粗い3Dスケルトンジョイント $P_{ske}^{c}$ を入力として受け取ります。
- これは**3層のシンプルなMulti-Layer Perceptron (MLP)**で構成されており、スケルトンの固定トポロジーと少ないジョイント数に対して効率的に機能します。
- 出力として、スケルトン特徴 $f_s \in \mathbb{R}^{s \times c}$ を生成します($c$ は特徴チャネル数)。
-
b. メッシュエンコーダー (Mesh Encoder):
- ステップ3で構築されたスケルトン認識型頂点特徴 $f_v$ を入力として受け取ります。
- ここでは、U字型Point Transformer [30] を採用しています。これは、従来のGNNとは異なり、メッシュのエッジ情報に依存せず、3D空間における点群(頂点)間の局所的な幾何学的相関とグローバルな幾何学的セマンティック情報を効果的に集約します。
- 特に、AI生成メッシュの不規則なエッジ構造に対して、より優れた汎化性能とロバスト性を示します。
- 出力として、深層メッシュ特徴 $f_m \in \mathbb{R}^{m \times c}$ を生成します。
5. 特徴の相互統合 (Mesh-Skeleton Mutual Attention Network: MSMAN)
このステップが、メッシュ特徴とスケルトン特徴を密接に連携させ、両方の精度を向上させる鍵となります。
-
a. メッシュ特徴のスケルトンによる強化:
- スケルトン特徴 $f_s$ を「クエリ (Query: $Q$)」として、メッシュ特徴 $f_m$ を「キー (Key: $K$)」と「バリュー (Value: $V$)」として、マルチヘッド相互アテンションメカニズムを適用します。
- これにより、メッシュ特徴に各頂点がどの身体部位に属するかというセマンティックな理解を付与し、スキニングウェイト予測の精度を高めます。
- 結果として、スケルトンによって強化されたメッシュ特徴 $f_{s \rightarrow m} \in \mathbb{R}^{m \times c}$ が得られます。
$$
Q = f_s; K = f_m; V = f_m \
f_{m \rightarrow s} = \text{softmax} \left( \frac{Q K^T}{\sqrt{d}} \right) V
$$
注: 論文の式(1), (2)では $f_{m \rightarrow s}$ となっていますが、文脈からメッシュ特徴がスケルトンによって強化される $f_{s \rightarrow m}$ と読み替えるのが自然です。ここでは $f_{m \rightarrow s}$ をスケルトン側の強化された特徴、 $f_{s \rightarrow m}$ をメッシュ側の強化された特徴として説明を続けます。
-
b. スケルトン特徴のメッシュによる強化:
- 同様に、メッシュ特徴 $f_m$ を「クエリ ($Q$)」として、スケルトン特徴 $f_s$ を「キー ($K$)」と「バリュー ($V$)」として、相互アテンションを適用します。
- これにより、スケルトン特徴にメッシュの局所的な形状情報を統合し、スケルトン位置の精密化に役立てます。
- 結果として、メッシュによって強化されたスケルトン特徴 $f_{m \rightarrow s} \in \mathbb{R}^{s \times c}$ が得られます。
$$
Q = f_m; K = f_s; V = f_s \
f_{s \rightarrow m} = \text{softmax} \left( \frac{Q K^T}{\sqrt{d}} \right) V
$$
注: 論文の記述に合わせて $f_{m \rightarrow s}$ と $f_{s \rightarrow m}$ の定義を修正しました。上記の説明では、MSMANが双方向で相互に特徴を強化することを示しています。
6. リギングヘッドによる最終予測
-
MSMANによって統合・強化された特徴は、それぞれ独立したMLPベースのヘッドに入力され、最終的なリギング結果を予測します。
-
a. スケルトン位置の予測:
- 強化されたスケルトン特徴 $f_{m \rightarrow s}$ を入力とし、MLPベースのヘッドが、最終的な精密化された3Dスケルトンジョイント位置 $P_{ske} \in \mathbb{R}^{s \times 3}$ を回帰します。
-
b. スキニングウェイトの予測:
- 強化されたメッシュ特徴 $f_{s \rightarrow m}$ を入力とし、MLPベースのヘッドが、各メッシュ頂点に対するスキニングウェイト行列 $P_{skin} \in \mathbb{R}^{m \times s}$ を予測します。これは、各頂点がどのスケルトンジョイントからどれだけ影響を受けるかを示す確率分布として扱われます。
7. 損失計算と学習
-
予測されたスケルトン位置 $P_{ske}$ とスキニングウェイト $P_{skin}$ は、グラウンドトゥルース(正解データ)と比較され、以下の損失関数を用いてネットワーク全体が学習されます。
-
a. スケルトン損失 ($L_{skeleton}$):
- 予測されたスケルトン位置と正解のスケルトン位置との間の平均二乗誤差 (MSE) を計算します。
$$
L_{skeleton} = \frac{1}{s} \sum_{i=1}^{s} (P_{ske_i} - G_{ske_i})^2
$$
ここで $G_{ske_i}$ は正解のスケルトンジョイント位置です。
- 予測されたスケルトン位置と正解のスケルトン位置との間の平均二乗誤差 (MSE) を計算します。
-
b. スキニング損失 ($L_{skinning}$):
- 予測されたスキニングウェイト分布と正解のスキニングウェイト分布との間のKLダイバージェンス損失を計算します。これは、分布間の距離を最小化します。
$$
L_{skinning} = \frac{1}{m} \sum_{i=1}^{m} \sum_{j=1}^{s} P_{skin_{i,j}} \log \frac{P_{skin_{i,j}}}{G_{skin_{i,j}}}
$$
ここで $G_{skin_{i,j}}$ は正解のスキニングウェイトです。
- 予測されたスキニングウェイト分布と正解のスキニングウェイト分布との間のKLダイバージェンス損失を計算します。これは、分布間の距離を最小化します。
-
c. 全体損失 ($L_{total}$):
- 最終的な学習には、スケルトン損失とスキニング損失の合計が用いられます。
$$
L_{total} = L_{skinning} + L_{skeleton}
$$
- 最終的な学習には、スケルトン損失とスキニング損失の合計が用いられます。
この一連のプロセスを通じて、HumanRigフレームワークは、AI生成の複雑な3Dヒューマノイドメッシュであっても、高品質なアニメーションに即座に利用できるスケルトンとスキニングウェイトを自動的に生成します。
Q:関連手法との比較について詳しく説明してください
A:
関連手法との比較
この論文では、自動リギングの2つの主要タスクである「スケルトン構築」と「スキニング」について、既存の手法と比較を行っています。
比較対象となる既存手法
-
データ駆動型手法:
- RigNet [25]: データ駆動型リギングの先駆けとなった手法で、メッシュのオフセット、アテンション、骨接続確率などを学習し、アテンションクラスタリングと最小全域木でスケルトンを構築します。
- NBS (Neural Blend Shapes) [11]: SMPLデータセット [13] を利用し、ニューラルブレンドシェイプを用いてスケルトン関節を学習します。固定のスケルトンテンプレート(SMPL)を使用します。
-
伝統的な幾何学的ベースの手法(スキニングのみ):
- Heat Diffusion [1]: メッシュの表面上の熱拡散をシミュレートし、骨からの距離に基づいてスキニングウェイトを割り当てます。
- GVB (Geodesic Voxel Binding) [5]: 測地線距離(メッシュ表面に沿った最短距離)に基づいてスキニングウェイトを計算します。
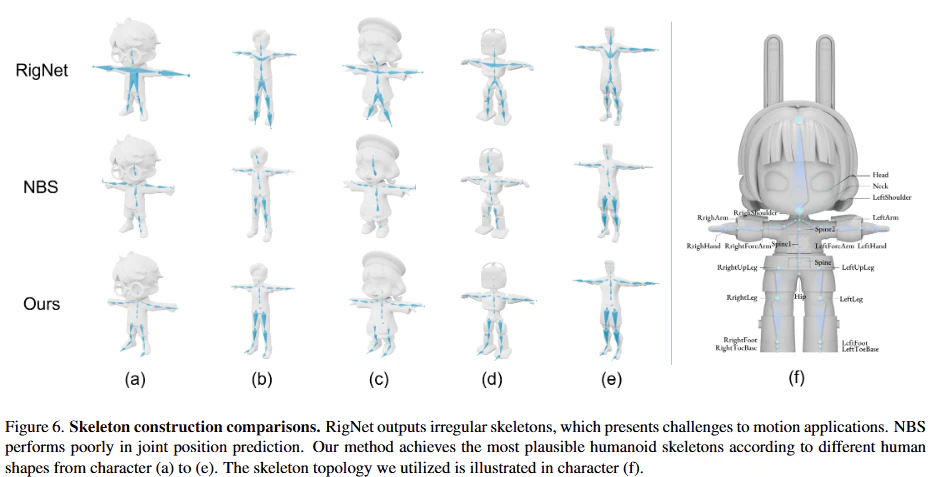
1. スケルトン構築の比較
HumanRigの優位性
- 最も解剖学的に妥当なスケルトン: 図6に示されているように、HumanRigは、多様な人間形状(リアルなキャラクターからカートゥーン、動物的なキャラクターまで)に対して、最も妥当で標準的な(Mixamo互換の)ヒューマノイドスケルトンを構築できます。これは、PGSEによる堅牢な2D事前情報の活用と、MSMANによるメッシュ・スケルトン特徴の相互統合による恩恵です。
- セマンティックなジョイント予測: HumanRigは、Mixamoスケルトンのような標準的なテンプレートに基づいているため、セマンティックな(意味のある)ラベルを持つ関節を予測します。これにより、予測されたスケルトンを直接アニメーションエンジンにプラグアンドプレイでき、モーションリターゲティング(別のキャラクターの動きを適用する作業)などのアニメーションタスクに適しています。
既存手法の課題
-
RigNet [25]:
- 不規則なスケルトン: RigNetは、ヒューマノイドスケルトンの事前情報(テンプレート)を組み込んでいないため、予測されるスケルトンが**不規則なトポロジー(骨のつながり方)**を持ち、特定のキーとなる関節が欠落することがあります。これにより、セマンティックなコンテキスト(意味的なつながり)を持たない骨配置となり、モーションタスクでの利用が困難です。
- 汎用性の欠如: 特に複雑なAI生成メッシュ(図6のキャラクター(a)~(e))に対しては、その能力が著しく低下します。
-
NBS (Neural Blend Shapes) [11]:
- 不正確なジョイント位置: NBSはSMPL [13] の固定スケルトンテンプレートを利用しますが、メッシュ特徴から直接ジョイント位置を回帰するという課題があるため、特に下肢などで不正確なジョイント位置を生成しがちです。
- 多様性への対応不足: SMPLデータセットのみで学習されているため、多様な頭身比を持つメッシュ(例えば、この論文のHumanRigデータセットに含まれるようなキャラクター)に対しては、汎化性能が不足します。
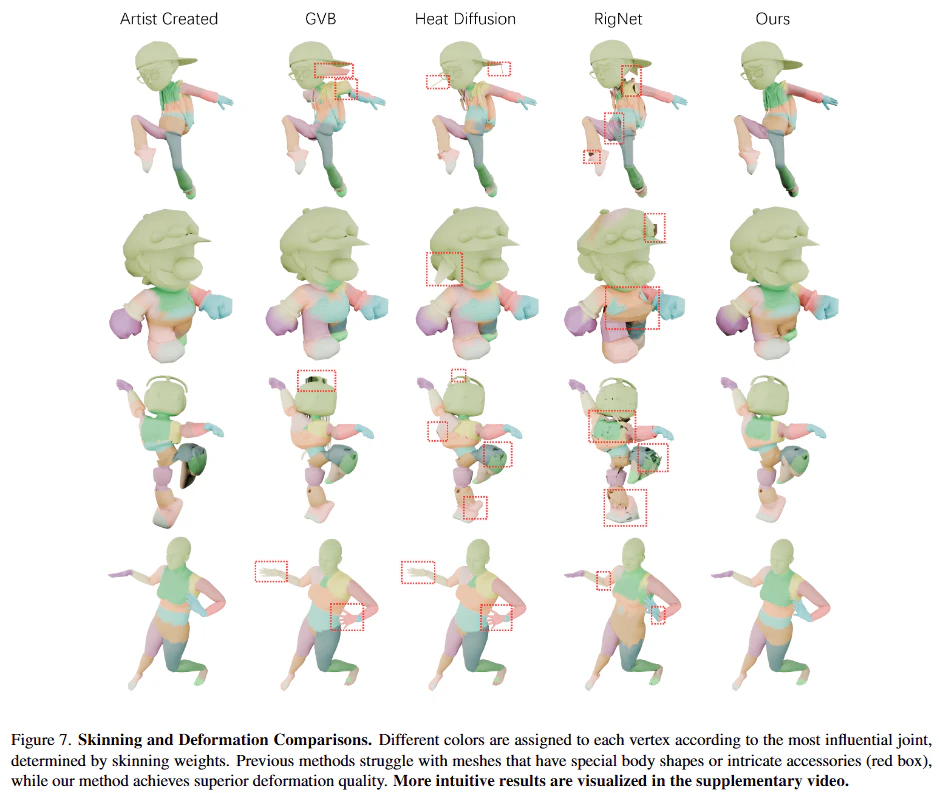
2. スキニングと変形品質の比較
HumanRigの優位性
- 優れた変形品質: 表5と図7に示すように、HumanRigは、Heat Diffusion、GVB、RigNetといった既存手法と比較して、**最も低い変形誤差(deformation error)**を達成しています。これは、アニメーション時のメッシュの「破綻」や「不自然な変形」が少ないことを意味します。
- 複雑なメッシュへの対応: HumanRigは、特殊な体型、複雑な衣服、アクセサリーを持つメッシュ(図7の赤枠部分など)に対しても、非常にリアルで滑らかなスキニングウェイトを生成し、ライフライクなアニメーションを維持できます。これは、Point Transformerベースのメッシュエンコーダーが、複雑なメッシュの頂点特徴を包括的かつ効率的に集約できるためです。GNNベースの手法が持つ、不規則なエッジ情報への脆弱性を克服しています。
- 多様なデータでの性能: RigNetv1-human(アーティスト作成メッシュ)とHumanRig(AI生成メッシュ)の両方のテストセットで最高の性能を示しており、幅広い種類のキャラクターモデルに対応できる汎用性の高さが証明されています。
既存手法の課題
-
RigNet [25]:
- 複雑なメッシュの非対応: RigNetは、5Kを超える頂点を持つ複雑なメッシュを処理できません。この論文のHumanRigデータセットは、これよりもはるかに多くの頂点を持つメッシュも含まれるため、RigNetはHumanRigデータセットでは評価できていません(表5の"N/A")。
- 品質の限界: 処理できるメッシュであっても、スキニングの精度や変形品質においてHumanRigに劣ります。
-
Heat Diffusion [1] と GVB [5]:
- 幾何学的制約: これらの伝統的な手法は、純粋にメッシュの幾何学的特性(距離など)に基づいてスキニングウェイトを割り当てます。このため、メッシュが不規則な形状であったり、複雑な服装をしている場合、解剖学的に正確な、または直感的なスキニングウェイトを生成することが困難です。例えば、メッシュの表面距離が近くても、実際には間に服がある場合など、不自然なウェイトが割り当てられることがあります。
- データ駆動型学習の恩恵の欠如: データから複雑なセマンティックな関係性を学習する能力がないため、HumanRigのようなデータ駆動型手法の柔軟性や精度には及びません。
まとめ
HumanRigは、新しい大規模データセットと、2D事前情報、Point Transformer、相互アテンションメカニズムを組み合わせた革新的なアーキテクチャにより、以下の点で既存手法を大きく上回っています。
- データセットの規模と多様性: 11,434個のAI生成メッシュと統一されたMixamoスケルトンにより、これまで不可能だった汎用性の高いモデル学習を実現。
- スケルトン構築の正確性と実用性: PGSEにより、多様な体型に対して解剖学的に妥当で、セマンティックな情報を持つ、アニメーションに即利用可能なスケルトンを生成。
- スキニング品質と変形性能の向上: Point TransformerベースのメッシュエンコーダーとMSMANにより、複雑な形状や衣服を持つAI生成メッシュに対しても、非常に高精度でリアルなスキニングと変形を実現。
これらの比較結果は、HumanRigが自動リギングの分野における、現在の最先端技術を上回る画期的な進歩であることを明確に示しています。
Q:提案手法の限界と今後の課題はなんですか?
A:
HumanRigの限界と今後の課題
1. 小さな身体部位への対応不足と、それに対応するデータセットのきめ細やかさ
-
論文で述べられている限界:
- 現在のスケルトンテンプレートは、指などの小さな身体部位を考慮していません。
- これは、より繊細なアニメーションを行うためには、データセットにおいて**よりきめ細やかなメッシュ(finer meshes)**を生成する必要があることを意味します。
-
詳細な考察と研究課題:
-
現在のMixamoスケルトンの制約: HumanRigが採用しているMixamoスケルトンは、一般的なボディモーションには十分ですが、指の独立した動き、顔の表情(目のまばたき、口の動きなど)、または非常に複雑な衣服のディテール(例えば、流れるような袖の動き)など、高精度なアニメーションを要求される細部には対応していません。
-
データセットとアノテーションの複雑化: 小さな部位をリギングするためには、その部位のメッシュが十分な解像度を持っているだけでなく、それに対応する詳細なスケルトンジョイント(例えば、各指に3つのジョイントなど)と、そのジョイントに対するスキニングウェイトをアノテーション(ラベル付け)する必要があります。これはデータ収集とアノテーション作業の複雑さを劇的に増加させます。
-
モデルアーキテクチャへの影響: 詳細な部位を扱うには、現在のPoint Transformerベースのエンコーダーがより高解像度の入力に対応できるか、あるいはマルチスケール(多段階解像度)のリギング戦略や、特定の身体部位に特化したサブネットワークを導入する必要があるかもしれません。例えば、全身のリギングとは別に、手の指や顔の表情筋に特化したマイクロリギングモジュールを統合するアプローチなどが考えられます。
-
新たな研究問い:
- 指や顔などの微細な部位に対して、自動的に適切なスケルトン階層を設計し、きめ細やかなスキニングウェイトを割り当てるデータ駆動型手法はどのように構築できるでしょうか?
- 高解像度データのアノテーションコストが高い現状で、教師なし学習や半教師あり学習を用いて、詳細なリギングを学習する方法はないでしょうか?
- 階層的またはマルチスケールのリギングフレームワークを構築し、粗い動きから細かい動きまでシームレスに対応できるようにするには、どのようなアーキテクチャが有効でしょうか?
-
2. 非ヒト型キャラクターや任意の物体への汎化性
-
論文で述べられている限界:
- 提案手法が、**四足歩行動物(quadruped)や任意の物体(any objects)**に拡張できるか、という点は今後の研究課題として挙げられています。
-
詳細な考察と研究課題:
-
ヒト型キャラクターへの特化: HumanRigは「Humanoid」キャラクターに特化しており、統一されたMixamoスケルトンを前提としています。ヒト型キャラクターは比較的共通の解剖学的構造と動きのパターンを持つため、モデル学習に適しています。
-
トポロジーと解剖学的構造の多様性: 四足動物や鳥、魚、さらにはロボットや家具といった「任意の物体」になると、スケルトンのトポロジー(骨のつながり方)や関節の自由度、動くべき部位が大きく異なります。例えば、四足動物には背骨、足、尾などがあり、その構造はヒト型とは根本的に違います。任意の物体となると、そもそも「スケルトン」という概念自体をどのように定義し、抽出するかが課題となります。
-
セマンティックな骨格の発見: 未知の物体に対して、どの部分が「関節」で、どの部分が「骨」として機能するべきかをAIが**自律的に「発見」**し、その物体に最適なスケルトンを構築する能力が必要です。これは現在の固定テンプレートベースのアプローチとは全く異なる、より高次元のセマンティック理解を要します。
-
新たな研究問い:
- 事前に定義されたテンプレートに縛られず、**入力された3Dメッシュからその形状と潜在的な機能(動く可能性のある部位)を分析し、最適なスケルトン構造とトポロジーを「学習・生成」**するフレームワークは可能でしょうか?
- 多様なカテゴリの物体リギングに対応するため、トポロジー適応型のGNNや、潜在空間でのスケルトン表現学習といった、より抽象的な特徴抽出と生成メカニズムが必要となるかもしれません。
- 「動くべき部位」というセマンティクスを、大規模な言語モデル(LLM)やマルチモーダルモデルと3D生成技術を組み合わせることで、テキスト記述やコンセプト画像から自動的に推論し、リギングに利用できる可能性はないでしょうか?
-
これらの課題は、HumanRigが現在の強みを維持しつつ、さらに広い応用範囲と高い汎用性を獲得するための重要なステップを示しています。特に、**「セマンティックな理解に基づく自律的なスケルトン生成」**は、キャラクターアニメーションだけでなく、ロボット工学や物理シミュレーションなど、幅広い分野に影響を与える可能性のある、非常に興味深い研究領域と言えるでしょう。