Structured 3D Latents for Scalable and Versatile 3D Generation (Xiang, 2025)

3行要約
- ✨ 本研究は、多様な3D表現形式に対応する高品質なアセット生成のためのStructured Latent (SLAT)という新しい統一ラテント表現を提案します。
- 🧩 SLATは、スパースな3Dグリッド上のローカルラテントにDINOv2などの強力な視覚特徴を統合し、Radiance Fields、3D Gaussians、meshesへの多様なデコードを可能にします。
- 🚀 Rectified Flow Transformersに基づく生成モデルは、SLATを用いてテキストや画像から高品質な3Dアセットを高速に生成し、詳細な編集機能も提供します。
論文解説: TRELLIS - 構造化潜在空間が拓くスケーラブルで多様な3D生成
概要
AI Generated Content (AIGC) の分野で、2D画像生成は目覚ましい進歩を遂げましたが、3D生成は多様な表現形式(メッシュ、点群、ボクセル、NeRF、3D Gaussiansなど)が存在するため、標準的なパラダイムの確立と品質向上が課題でした。特に、高品質な形状と質感の両方を詳細に捉え、さらに様々な出力形式に対応できる汎用的な手法は限られていました。
本論文で提案される TRELLIS は、この課題に対処するため、Structured LATent (SLAT) と呼ばれる新しい統一的な3D潜在表現と、それを活用した生成パイプラインを提案します。SLATは、スパースな3Dグリッド上に詳細なローカル潜在情報を格納することで、形状と質感の両方を包括的に表現します。これにより、テキストや画像プロンプトから、高品質かつ多様な形式(3D Gaussians、Radiance Fields、メッシュ)の3Dアセットを生成することを可能にしました。
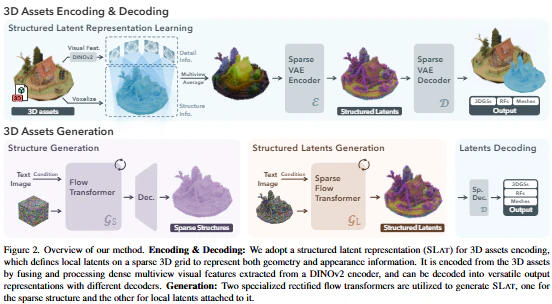
提案手法の処理の流れ
TRELLISは大きく「SLAT表現の学習」と「SLATを用いた3Dアセットの生成」のプロセスから構成されます。
-
SLAT表現の学習 (Encoding & Decoding):
- まず、学習用の高品質な3Dアセットを用意します。
- アセットの周囲から複数の視点で画像をレンダリングし、学習済みビジョン基盤モデルDINOv2 [65] を用いて詳細な視覚特徴を抽出します。
- アセット表面と交差するボクセルを「アクティブなボクセル」とし、そこに多視点画像から集約したDINOv2特徴を付与します。これにより、スパースな3Dボクセル特徴
fが得られます。 - TransformerベースのSparse VAE (Encoder E) を用いて、このスパースな3D特徴
fをStructured Latent (SLAT)zに符号化します。SLATは、アクティブなボクセルの位置{p_i}と、各ボクセルに対応するローカル潜在ベクトル{z_i}のセットとして定義されます。
$$z = {(z_i, p_i)}_{i=1}^L, \quad z_i \in \mathbb{R}^C, p_i \in {0, 1, \dots, N-1}^3$$
ここで、$L$はアクティブボクセルの数、$N$はグリッド解像度(デフォルトは64)、$C$は潜在ベクトルの次元です。アクティブボクセルは約20K個程度($N^3 = 64^3 \approx 262K$よりも大幅に少ない)とスパースです。 - SLAT
zは、学習済みの複数のデコーダー(DGS, DRF, DM)によって、それぞれ3D Gaussians [33]、Radiance Fields [59]、メッシュ [74] といった異なる3D表現に復号化されます。 - エンコーダーとデコーダーは、元の3Dアセットからの再構成精度を最大化するようにエンドツーエンドで学習されます。特に、3DGSデコーダー(DGS)が高い忠実度と効率性から主に用いられ、他のデコーダーはエンコーダーを固定して別途学習されます。
(論文Figure 2左側を参照)
-
SLATを用いた3Dアセットの生成:
- テキストまたは画像プロンプトを入力として受け取ります。
- 生成は、SLATの構造に合わせて2段階のRectified flowモデルを用いて行われます。
- 第1段階: スパース構造の生成 (GSモデル): プロンプトに基づき、Rectified flow Transformer (GS) がアクティブボクセルの位置を示すスパースな3D構造を生成します。内部では効率のため、スパースなバイナリグリッドを低解像度の密な特徴グリッドに圧縮して扱います。
-
第2段階: ローカル潜在表現の生成 (GLモデル): 第1段階で生成されたスパース構造とプロンプトを入力として、別のRectified flow Transformer (GL) が、各アクティブボクセルに対応するローカル潜在ベクトル
{z_i}を生成します。
- 生成された ${p_i}$ と ${z_i}$ を組み合わせたSLAT
zを、学習済みのデコーダー(ユーザーが選択)に入力し、最終的な3Dアセット(3DGS、Radiance Fields、メッシュ)を出力します。
(論文Figure 2右側を参照)
関連研究との比較

TRELLISは、既存の主要な3D生成手法(Shap-E, LGM, InstantMesh, 3DTopia-XL, LN3Diff, GaussianCubeなど)と比較して、以下の点で優位性を示しています。
- 表現形式の汎用性: SLATは、形状と質感の両方を統一的に表現できるため、様々な出力形式に対応可能です。多くの既存手法は特定の形式に特化しており、汎用性に欠けます(Sec 1, 2)。
- 生成品質: 大規模な高品質データセット(約50万件)とGPT-4o [1] による詳細なキャプション、そしてDINOv2特徴の活用により、形状・質感ともに高品質なアセットを生成できます。特に2D画像ベースの手法 [48, 68] に見られる多視点不整合による形状の歪みが少ないです(Fig 5, 15)。定量評価(表2)およびユーザー調査(図6, 表9)において、TRELLISは他の手法を大幅に上回る性能を示しています。
- 学習効率: 3Dデータを特定の形式にフィットさせる costly な前処理(フィッティング)が不要です(Sec 1)。
- 柔軟な編集: SLATの構造(構造と潜在表現の分離)と局所性(ボクセル単位)を利用することで、アセットの構造を維持したまま詳細を変更したり、特定の領域のみを編集したりするチューニング不要の編集機能を実現しています(Sec 3.4, Fig 1, 7, 17, 18)。これは多くの既存生成モデルにはない機能です。
- 生成モデル: 広く使われるDiffusionモデル [29, 79] ではなくRectified flowモデル [44] を採用しており、アブレーション研究(表4)で良好な結果が得られています。
限界と今後の課題
論文では、いくつかの限界と今後の課題も挙げられています(Sec E)。
- 2段階生成パイプラインの効率性: SLATの生成が2段階で行われるため、全体としての生成速度が、単一段階で完結する手法に比べて遅くなる可能性があります。将来的には、パイプラインの統合や各段階のモデルの推論速度の最適化が課題となります。
- 画像からの生成におけるライティング分離: 画像プロンプトから生成する場合、元の画像に含まれるライティング効果が生成される3Dアセットに焼き付いてしまうことがあります。これを防ぐためには、学習時によりロバストなライティングデータ拡張を行うことや、モデルに物理ベースレンダリング(PBR)用の材質特性を予測させるようにすることが考えられます。
結論
TRELLISは、Structured Latent (SLAT) という革新的な表現と、大規模データ、Rectified flowモデル、そして基盤モデルからの強力な特徴を組み合わせることで、高品質、汎用性、編集性を兼ね備えた3D生成を実現しました。既存手法の多くの課題を克服し、3Dアセット生成の分野を大きく前進させる可能性を秘めた研究です。今後の研究によって、さらなる効率化やライティングの問題が克服されれば、より広範なアプリケーションでの活用が期待されます。