Packing Input Frame Context in Next-Frame Prediction Models for Video Generation (Zhang, 2025)
3行要約
- 🤔 本研究は、次フレーム予測ベースの動画生成におけるForgetingとDriftingの問題に対処するため、FramePackという新しいニューラルネットワーク構造を提案します。
- 💡 FramePackは入力フレームを重要度に応じて圧縮し、Transformerのコンテキスト長を動画長に関わらず一定に保つことで、多数のフレームを効率的に処理できるようにします。
- ✅ また、双方向コンテキストや逆時間順序での生成を含むAnti-driftingサンプリング手法を提案し、これによりエラーの蓄積を防ぎ、動画の品質向上を実現します。
Q:この論文の概要を教えてください
A:
本論文は、ビデオ生成における次フレーム(または次フレームセクション)予測モデルが抱える「忘却 (forgetting)」と「漂流 (drifting)」という2つの重要な問題に対処するための、FramePackと呼ばれるニューラルネットワーク構造と、抗漂流サンプリング手法を提案しています。「忘却」は、モデルが過去のフレームを十分に記憶できず、時間的な一貫性を維持できなくなることを指します。「漂流」は、エラーが反復的に蓄積・伝播することで、視覚的品質が時間とともに劣化していく問題(exposure biasとも呼ばれます)です。これらの問題はトレードオフの関係にあり、一方を改善しようとすると他方が悪化する傾向があります。忘却に対処するために多くのフレームをエンコードすることは、Transformerのattention計算量が動画長に対して二次増加(またはFlashAttnのような準二次最適化でも増大)するため、すぐに計算が非現実的になります。動画フレームには大きな時間的冗長性があるため、効率的な圧縮システムが必要です。
FramePackは、忘却問題に対処するために、入力フレームをその重要度に応じてプログレッシブに圧縮する構造です。これにより、入力フレーム数に関わらず、Transformerのコンテキスト長が固定の上限に収束します。結果として、計算ボトルネックを画像拡散モデルと同程度に保ちつつ、大量のフレームを処理することが可能になり、学習時のビデオバッチサイズも大幅に増加させることができます。フレームの重要度は、単純な時間的な近接性(予測ターゲットに近いフレームほど重要)に基づくと仮定しています。フレーム $F_i$ のコンテキスト長 $\phi(F_i)$ は、VAEエンコードとTransformerのpatchifying適用後、$\phi(F_i) = L_f \lambda^{-i}$ と定義されます。ここで $L_f$ は非圧縮時のフレームあたりのコンテキスト長、$\lambda > 1$ は圧縮パラメータです。このフレームごとの圧縮は、Transformerの入力層にあるpatchifyカーネルサイズを操作することで実現されます。全体のコンテキスト長 $L$ は、 $S$ 個の未知のフレームと $T$ 個の入力フレームの場合、$L = S \cdot L_f + L_f \cdot \sum_{i=0}^{T-1} \lambda^{-i}$ となり、$T \to \infty$ で $L$ は $S \cdot L_f + \frac{\lambda}{\lambda - 1} L_f$ に収束し、入力フレーム数 $T$ に不変な計算ボトルネックを実現します。本論文では主に $\lambda=2$ の場合を議論しますが、特定の項を複製することで任意の圧縮率を表現できます。patchifying操作は typically 3D カーネル $(p_f, p_h, p_w)$ で行われ、同じ圧縮率でも異なるカーネルサイズが可能です。異なる圧縮率に対応する入力投影には独立したパラメータを使用し、事前学習済みモデルから補間して初期化します。動画の末尾(最小単位サイズ以下のフレーム)の処理には、削除、1ピクセル追加、グローバル平均プーリングの3つのオプションがあります。異なる圧縮カーネルでエンコードされた入力のRoPE (Rotary Position Embedding) アライメントのため、RoPEの位相を平均プーリングでダウンサンプリングし、圧縮カーネルに合わせます。FramePackには、幾何級数以外の圧縮スケジュールや、時間次元での圧縮、最初のフレームを最重要視するなどのフレーム重要度の定義変更を含む、様々なバリアントが提案されています。
漂流問題に対処するため、本論文は抗漂流サンプリング手法を提案しています。これは、因果予測チェーンを断ち切り、双方向のコンテキストを取り入れることで実現されます。従来のバニラサンプリング(未来フレームを順次予測)に対し、提案手法には2つの主要なバリアントがあります。1つは、最初のイテレーションで開始と終了のセクションを同時に生成し、その後のイテレーションでその間のギャップを埋める方法(Bi-directional sampling)。もう1つは、フレームを逆時間順序で生成する方法(Inverted temporal sampling)です。逆時間順序サンプリングでは、各生成ステップが既知の高品質なフレーム(Image-to-Videoにおける入力フレームなど)に近づこうとするため、特にImage-to-Video生成において有効です。これらのサンプリング方法は、FramePackと同様に任意の長さの動画を生成可能であり、RoPEのランダムアクセス(非連続的な時間インデックスのスキップ)をサポートするように変更が必要です。
実験では、既存のビデオ拡散モデル(HunyuanVideo, Wan)をFramePackでファインチューニングできることを示しています。次フレームセクション予測は、フルビデオ拡散に比べて各推論ステップでの3Dテンソルサイズが小さいため、よりフローシフト値の小さいバランスの取れた拡散スケジューラーで訓練することが可能となり、これがリアルな動画に近いシャープでクリーンな結果をもたらすことが観察されました。13B HunyuanVideoモデルを使用し、480p解像度の場合、8xA100-80Gノードでバッチサイズ64での学習が可能であり、これは画像拡散モデルに匹敵するバッチサイズです。評価は、Clarity, Aesthetic, Motion, Dynamic, Semantic, Anatomy, Identity といったグローバルメトリクス、開始フレームと終了フレーム間での品質差 $|M(V_{start}) - M(V_{end})|$ で定義される漂流メトリクス $\Delta M_{drift}$ 、および人間のA/Bテストに基づくELOスコアとランキングで行われました。
Ablation studyの結果、提案する逆時間順序サンプリング方法が、Global metricsの7つのうち5つと、全てのDrifting metricsで最良の結果を達成しました。人間評価でも、逆時間順序サンプリングが最も高いELOスコアを示しました。バニラサンプリングでDynamicスコアが高いのは、漂流による品質劣化がダイナミックに見えるためと推測されます。同じサンプリングカテゴリー内での詳細なFramePack構成の差は比較的小さいことが分かりました。既存手法(Repeating image-to-video, Anchor frames, Causal attention, Noisy history, History guidance)との比較では、提案手法(f1k1_x_g9_f1k1f2k2f16k4)がGlobal metricsの3つ、全てのDrifting metrics、および人間評価で最良の結果を示しました。
結論として、FramePack構造はプログレッシブ圧縮により入力コンテキスト長を固定の上限に収束させ、抗漂流サンプリング手法は双方向コンテキストによりエラー蓄積を防ぎます。これにより、計算ボトルネックを維持したまま、より長いビデオ生成が可能となります。本手法は既存のビデオ拡散モデルと互換性があり、学習バッチサイズを増加させ、推論品質を向上させることができます。様々な圧縮バリアントにも対応可能です。
Q:提案手法の処理の流れを順序だてて説明してください
A:
この研究で提案されているFramePackは、ビデオ生成における「忘却(Forgetting)」と「ドリフト(Drifting)」という主要な課題に対処するためのものです。 FramePack構造は忘却を防ぐために、アンチドリフトサンプリング手法はドリフトを防ぐために設計されており、これらを組み合わせて長尺動画生成を効率的かつ高品質に行います。
以下に、主要な処理の流れを説明します。
1. FramePack構造による入力フレームのパッキング
FramePackの主な目的は、入力として与えられる過去フレームのコンテキスト長を、ビデオの長さに関わらず固定の上限に収束させることで、Transformerの計算コストを抑えつつ、大量のフレームを扱えるようにすることです。
- 入力フレームの準備: 次に生成するフレームセクションの予測に必要な、過去のフレーム群($T$フレーム)を用意します。これらのフレームはまずVAEによってlatent表現に変換されます。
- 重要度の決定: 入力フレームをその重要度に基づいて並べ替えます。論文では、シンプルに時間的近接性(最近のフレームほど重要)を基準としていますが、アプリケーションによっては他の基準(例えば、image-to-videoでは最初のフレームが最も重要)も考えられます。フレームは重要度が高い順に$F_0, F_1, \dots, F_{T-1}$のように並べられます。
-
段階的圧縮の適用: 重要度の低いフレームほど、より高い圧縮率を適用します。これは主に、Transformerの入力層におけるpatchifyカーネルのサイズを操作することで実現されます。例えば、重要度に応じた各フレームのコンテキスト長 $\phi(F_i)$ は、圧縮パラメータ $\lambda > 1$ を用いて以下のように定義されます。
$\phi(F_i) = L_f \lambda^i$
ここで、$L_f$ は非圧縮時の1フレームあたりのコンテキスト長、$i$ は重要度の低い方からのインデックスです。これにより、全体のコンテキスト長は以下のように幾何級数的に増加し、Tが大きくなっても一定の値に収束します。
$L = S \cdot L_f + L_f \cdot \sum_{i=0}^{T-1} \frac{1}{\lambda^i} \rightarrow S \cdot L_f + \frac{\lambda}{\lambda - 1} \cdot L_f \quad \text{as } T \rightarrow \infty$
ここで、$S$ は生成する次フレームセクションのフレーム数です。 - RoPEの位置合わせ: 異なる圧縮率(異なるpatchifyカーネルサイズ)でエンコードされた入力に対して、Rotary Position Embedding (RoPE) の位相を、圧縮カーネルに合わせてダウンサンプリングすることで位置合わせを行います。
このFramePack構造により、モデルはより多くの過去フレームを効率的に参照できるようになり、「忘却」の問題を軽減します。

2. アンチドリフトサンプリング手法による生成
次フレーム(または次フレームセクション)を実際に生成する段階で、ドリフト(誤差の蓄積と伝播による品質劣化)を防ぐために、様々なサンプリング戦略を用います。論文では主に以下の3つの戦略が図2で示されています。
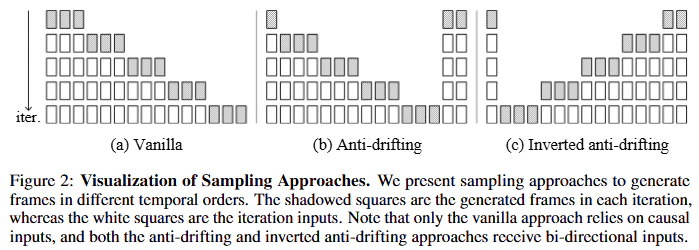
- バニラサンプリング (Vanilla Sampling, 図2a): これは最も単純な方法で、過去に生成されたフレームのみをコンテキストとして使用し、次のフレームを順番に生成していきます。これは直感的ですが、誤差が蓄積・伝播しやすく、長尺になるとドリフトが発生しやすいです。
- アンチドリフトサンプリング (Anti-drifting Sampling, 図2b): この方法では、最初の生成ステップで動画の最初と最後のフレームセクション(アンカーとなるendpoint)を同時に生成します。その後のステップでは、これらの固定されたアンカーフレームを参照しながら、間のフレームを埋めていきます。これにより、生成プロセスが未来の高品質なフレーム(アンカー)によって制約されるため、誤差の蓄積が抑制され、ドリフトが防がれます。過去と未来の双方向コンテキストを利用することが鍵となります。
- 反転アンチドリフトサンプリング (Inverted Anti-drifting Sampling, 図2c): これはアンチドリフトサンプリングの亜種で、特にimage-to-videoタスクに有効です。ユーザー入力である最初のフレームを高品質な基準点として扱い、そこから逆向き(過去へ向かう方向)にフレームを生成していきます。各生成ステップで、既知の高品質なフレーム(最初の入力フレームなど)を近似するように生成がガイドされるため、全体的な品質が高く保たれ、ドリフトが抑制されます。こちらも双方向コンテキストを利用します。
これらのアンチドリフトサンプリング手法は、FramePackによって効率的にパッキングされた入力フレームコンテキストを利用して実行されます。特に、アンチドリフトおよび反転アンチドリフトサンプリングでは、非連続な時間インデックスのフレーム(例えば、最初と最後のフレーム)を同時にTransformerへの入力として扱う必要があり、これに対応するためにRoPEの計算方法が修正されます。
まとめ
提案手法の処理の流れは、まずFramePack構造を用いて、ビデオの長さに関わらず大量の入力フレームを効率的な固定長コンテキストに圧縮・パッキングします。これにより、モデルが過去の情報をより長く「記憶」できるようになり、忘却を軽減します。次に、この効率化されたコンテキストを利用して、特にアンチドリフトサンプリングや反転アンチドリフトサンプリングといった未来のフレームを参照する戦略を用いることで、誤差の蓄積を防ぎ、ドリフトの発生を抑制しながら長尺ビデオを生成します。
FramePackとアンチドリフトサンプリングの組み合わせが、長尺ビデオ生成における忘却とドリフトという二律背反する課題に対して、効率的かつ高品質なソリューションを提供していると言えます。
Q:関連手法との比較について詳しく説明してください
A:
提案手法であるFramePackは、ビデオ生成の長期的なコヒーレンスを維持するための重要な課題である「忘却」と「ドリフト」に焦点を当てています。この論文では、FramePack構造に加えて、アンチドリフトサンプリング手法を組み合わせることで、既存の様々な関連手法と比較して優れた性能を示すことを実験的に検証しています (Table 2を参照)。
以下に、論文中で比較されている主要な関連手法と、それらに対するFramePackの優位性を詳しく説明します。
比較対象として挙げられている手法は、長尺ビデオ生成を可能にするもの、計算ボトルネックを削減するもの、あるいはその両方を目指すものです。これらはすべて、HunyuanVideoというベースモデルの上で、FramePackの代替として実装・評価されています。
-
Repeating image-to-video (画像-動画変換の繰り返し):
- 手法: これは最も単純なアプローチで、画像-動画変換モデルの推論を繰り返し実行して、連続する短い動画クリップを生成し、それらを繋ぎ合わせる方法です。
- 課題: この手法は、各クリップが独立して生成されるため、クリップ間の時間的な一貫性(例えば、被写体の一貫した動き、シーンの連続性、スタイルなど)を維持するのが非常に困難です。結果として、動画全体で見ると視覚的な断裂や不整合が頻繁に発生します。
- FramePackとの比較: Table 2を見ると、Repeating image-to-videoはすべてのグローバルメトリクス、ドリフトメトリクス、そして人間の評価(ELO)において最も低いスコアを示しています。FramePackは過去フレームコンテキストを効率的に利用し、サンプリング戦略で時間的な連続性を考慮するため、この単純な繰り返し手法とは根本的に異なり、遥かに高品質でコヒーレントな長尺動画を生成できます。
-
Anchor frames (アンカーフレーム):
- 手法: StreamingT2V [15] に似たアプローチで、特定フレーム(例えば最初のフレームや定期的に挿入されるキーフレーム)を高品質な「アンカー」として使用し、そのフレームを参照しながら他のフレームを生成することで、ドリフトを抑制しようとします。双方向コンテキストの一部を利用する考え方と関連します。
- 課題: アンカーフレームは時間的な一貫性のための有用な参照点を提供しますが、アンカー間のフレーム生成では依然として誤差が蓄積する可能性があります。また、過去の全コンテキストを効率的に扱うわけではないため、「忘却」の問題に対してFramePackほど包括的な解決策を提供できない可能性があります。
- FramePackとの比較: Table 2では、Anchor framesはRepeating image-to-videoやCausal attentionよりは優れていますが、FramePack(特にinverted anti-drifting variant)と比較すると、Clarity, Aesthetic, Semanticといったグローバルメトリクスや、すべてのドリフトメトリクス(∆Clarity_drift, ∆Motion_driftなど)で劣っています。FramePackは、アンカーフレームだけでなく、圧縮された形式でより多くの過去フレームコンテキスト全体を参照できるため、より堅牢な時間的コヒーレンスを維持できると考えられます。
-
Causal attention (因果的注意機構):
- 手法: CausVid [53] に似たアプローチで、Transformerの注意機構を因果的に制限します(未来のフレームを参照しない)。これはKVキャッシュを容易にし、推論速度向上に寄与しますが、過去フレームのみに依存する厳密な順方向生成になります。
- 課題: 過去にのみ依存する因果的な生成は、誤差の蓄積と伝播に非常に弱く、長尺になるとドリフトが顕著になります。論文の導入部でも述べられているように、これは「忘却」と「ドリフト」のジレンマにおけるドリフト側の問題が強調されるケースです。
- FramePackとの比較: Table 2を見ると、Causal attentionは多くのメトリクス、特にドリフトメトリクスでFramePackに大きく劣ります。FramePackのアンチドリフトサンプリングは、因果的な制約を破り、未来のフレーム(アンカー)を参照することでドリフトを積極的に抑制するため、因果的注意機構のモデルが抱えるドリフトの問題を回避できます。また、FramePackは注意機構自体を因果的にするわけではなく、入力コンテキストのパッキングとサンプリング戦略で長尺生成を可能にしています。
-
Noisy history (ノイズの多い履歴フレーム):
- 手法: DiffusionForcing [4] に似たアプローチで、過去のフレーム(履歴)のlatent表現に意図的にノイズを加えることで、モデルの履歴フレームへの依存度を低下させます。これにより、誤差の蓄積(ドリフト)を抑える効果が期待できますが、同時に過去の正確な情報へのアクセスが失われ、「忘却」が進む可能性があります。
- 課題: ドリフトは軽減されるかもしれませんが、履歴への依存を減らすことは時間的コヒーレンスを維持する上での制約となります。これは、導入部で述べられている「忘却」と「ドリフト」のトレードオフの一例です。
- FramePackとの比較: Table 2では、Noisy historyは他のいくつかのベースラインよりは優れていますが、FramePackと比較すると、ほとんどのグローバルメトリクスおよびすべてのドリフトメトリクスで劣っています。FramePackは、履歴を効率的にパッキングして「忘却」を防ぎつつ、サンプリング戦略で「ドリフト」を抑制するため、単純に履歴への依存度を下げるアプローチよりも、ジレンマをより良く解決していると言えます。
-
History guidance (履歴に基づくガイダンス):
- 手法: HistoryGuidance [34] に似たアプローチで、Classifier-Free Guidance (CFG) の枠組みを利用し、ノイズを加えた履歴フレームを無条件側(unconditional side)の入力として使用します。これにより、条件側(conditional side)は履歴フレームをより強く参照するように誘導され、記憶を強化(忘却を軽減)しようとします。しかし、これにより誤差の伝播が速まり、ドリフトが悪化する可能性があります。
- 課題: これは「忘却」を軽減しようとすると「ドリフト」が悪化するというトレードオフの顕著な例です。強いガイダンスは履歴への依存を高めますが、履歴に誤差が含まれるとその誤差も強く反映されてしまいます。
- FramePackとの比較: Table 2では、History guidanceはIdentityメトリクスでFramePackと競合する性能を示していますが、Clarity, Aesthetic, Semanticなどのグローバルメトリクス、そしてすべてのドリフトメトリクスではFramePackに劣っています。FramePackは、履歴への依存を適切に管理し(パッキング)、生成プロセス自体に未来の情報を取り込む(アンチドリフトサンプリング)ことで、履歴ガイダンスが抱える強い履歴依存によるドリフト悪化のリスクを回避しつつ、高いコヒーレンスを実現していると考えられます。
総合的な比較結果:
Table 2および論文の考察によると、提案手法であるFramePackとアンチドリフトサンプリング(特にinverted anti-drifting variant "f1k1_x_g9_f1k1f2k2f16k4")は、比較対象のすべての手法を上回る結果を示しています。具体的には:
- グローバルメトリクス: FramePackはClarity, Aesthetic, Semanticの3つのグローバルメトリクスで最高スコアを達成しています。他の手法はせいぜい1つか2つのメトリクスでFramePackと同等かそれ以下です。
- ドリフトメトリクス: FramePackはすべてのドリフトメトリクス(∆Clarity_drift, ∆Motion_drift, ∆Semantic_drift, ∆Anatomy_drift)で最も低いスコア(すなわち、ドリフトが最も少ない)を達成しています。これは、FramePackの主要な貢献の一つである「アンチドリフトサンプリング」の有効性を明確に示しています。
- 人間の評価: 人間のA/Bテストに基づくELOスコアでも、FramePackは最も高いスコアを獲得し、他の手法よりも人間の知覚においても優れていることが確認されています。
この結果は、FramePackが提案する「入力コンテキストの効率的なパッキングによる忘却の軽減」と「双方向コンテキストを利用したアンチドリフトサンプリングによるドリフトの抑制」という組み合わせが、従来の様々なアプローチよりも、長尺ビデオ生成における根本的な課題に対してより効果的に対処できることを強く示唆しています。特に、厳密な因果性や履歴への依存度操作に頼るのではなく、未来の情報を参照するサンプリング戦略を組み合わせている点が、ドリフト抑制において大きな利点となっています。
Q:提案手法の限界と今後の課題はなんですか?
A:
提案手法FramePackは、長尺ビデオ生成における忘却とドリフトの問題に対して非常に有望な解決策を提示していますが、他の研究手法と同様に、いくつかの限界と今後の課題が存在します。論文の内容やビデオ生成技術全般の現状を踏まえて、以下にそれらを整理します。
提案手法の限界
-
「重要度」の定義の限界:
- 論文では、 FramePackにおけるフレームの「重要度」を主に時間的な近接性(最近のフレームほど重要)に基づいて定義しています。これはシンプルで効果的ですが、すべてのシナリオで最適とは限りません。例えば、遠い過去に登場した特定のオブジェクトが後になって再登場する場合、そのオブジェクトが登場する古いフレームは時間的には遠くてもセマンティックな重要度は高いかもしれません。現在のFramePackの設計は、このような非局所的な、意味的な重要度を捉えるには限定的かもしれません。
- 図1でいくつかのバリアント(最初のフレームを重要視するなど)は示されていますが、より複雑な、内容に基づいた重要度の判断や、異なるタスク(例:特定のキャラクターのトラッキング、複雑なシーン遷移)に合わせた最適な重要度スケジュールの自動決定などは課題として残ります。
-
圧縮による潜在的な情報損失:
- FramePackは、重要度の低いフレームに対してパッチ化カーネルサイズを大きくすることで圧縮を実現しています。これによりコンテキスト長を固定化できますが、高い圧縮率が適用されるフレームでは、細かい視覚的ディテールや微妙な動きの情報が失われる可能性があります。論文の評価では全体の品質は向上していますが、特定の細かい点で圧縮の影響が出ないか、さらなる検証が必要です。
-
アンチドリフトサンプリングの複雑性と依存性:
- アンチドリフトサンプリング(図2b, 2c)は、未来のフレーム(アンカー)に依存したり、生成順序を反転させたりします。これによりドリフトは抑制されますが、最初のアンカーフレームや目標フレームの質が最終的な動画品質に大きく影響します。もし最初のアンカーの生成に失敗したり、image-to-videoで入力画像が低品質だったりした場合、その影響が動画全体に及ぶ可能性があります。
- また、未来のフレームを参照するサンプリングは、厳密な因果的なインタラクション(例:特定の時間におけるユーザー入力への反応)を必要とするアプリケーションにおいては、設計上の制約となる可能性があります。
-
動的表現のトレードオフの可能性:
- Table 1の実験結果で、バニラサンプリングが最も高い「Dynamic」スコアを示しています。論文ではこれをドリフトによるものと解釈していますが、アンチドリフトサンプリングがドリフトを抑える一方で、動画全体のダイナミズムや動きの多様性にわずかに影響を与える可能性も否定できません。非常に動きの激しいシーンや予測不能な動きを含む動画の生成において、アンカーによる制約が表現力を制限するケースがあるかもしれません。
-
極めて長尺な動画生成の実際的な課題:
- FramePackは理論上コンテキスト長を固定することで「任意の長さ」のビデオを扱えるとしていますが、推論時間の合計は生成するフレーム数に比例して増加します。また、数十秒や数分といったレベルを超えて、数十分、数時間の「映画」のような長尺動画を生成する場合、コンテキスト固定だけでは解決できない、より高レベルな課題(後述の物語性など)が発生します。論文でも実際には「十分な時間範囲を設定する」といった記述があり、実用上の長さには限界があることを示唆しています。
今後の課題
-
高レベルな長尺コヒーレンスの実現:
- FramePackとアンチドリフトサンプリングは、低レベルおよび中レベルの時間的コヒーレンス(動きの滑らかさ、短期的なオブジェクトの一貫性など)の維持に貢献しますが、長時間の動画におけるキャラクターの永続性、複雑なオブジェクトのインタラクション、環境の一貫性、そして物語全体の論理的な流れといった、より高レベルなコヒーレンスを保証するものではありません。例えば、キャラクターが一度画面外に出てから再登場する際に、その外見や状態が完全に維持されるか、などは依然として難しい問題です(関連研究 [17, 21, 23] はこの課題に取り組んでいます)。
- ストーリーや物語性を考慮した長尺ビデオ生成には、FramePackのようなフレームレベルのコヒーレンス機構に加えて、物語計画(story planning)やシーン構成を扱う高レベルな制御機構との連携が必要です(関連研究 [16, 21, 23, 29, 30])。
-
きめ細かい長尺制御の向上:
- ユーザーが長尺動画生成において、特定の時間帯に特定のイベントを発生させたり、オブジェクトの軌道を細かく指定したりといった、きめ細かい制御を行うことは依然として大きな課題です(関連研究 [12] はこの方向性で進んでいます)。FramePackは入力コンテキストの効率化という基盤を提供しますが、それ自体が直接的な制御インターフェースを提供するわけではありません。
-
FramePackバリアントの体系的な探索と最適化:
- 論文ではいくつかの FramePack バリアント(図1)が紹介されていますが、特定のタスクやデータセットに対して最適な圧縮スケジュールや重要度割り当てを見つけるための体系的な方法論はまだ確立されていません。異なるカーネルサイズや重複率の組み合わせが、どのような種類の動画生成にどのような影響を与えるのか、より詳細な分析とガイドラインが必要です。
-
様々なアーキテクチャへの応用と汎化:
- FramePackはDiffusion Transformer (DiT) ベースのモデル(Wan, HunyuanVideo)で実装・検証されています。この「重要度に応じた入力コンテキストの圧縮」という考え方が、他のビデオ生成アーキテクチャ(例:ViD-GPT [26] のようなGPTスタイルのautoregressiveモデル、異なるVAEや拡散プロセスを持つモデル)にも同様に有効であるか、汎用性を検証・証明することが課題となります。
-
学習効率とデータ要件:
- FramePackはバッチサイズを向上させ学習効率を高めますが、高品質な長尺動画生成モデルの学習には依然として大量の高品質なビデオデータと計算リソースが必要です。データ収集パイプライン [13] や、効率的な学習手法 [18] と組み合わせることで、より広範な研究者やクリエイターが利用可能になるような進歩が期待されます。