RigNet: Neural Rigging for Articulated Characters (ZHAN, 2020)
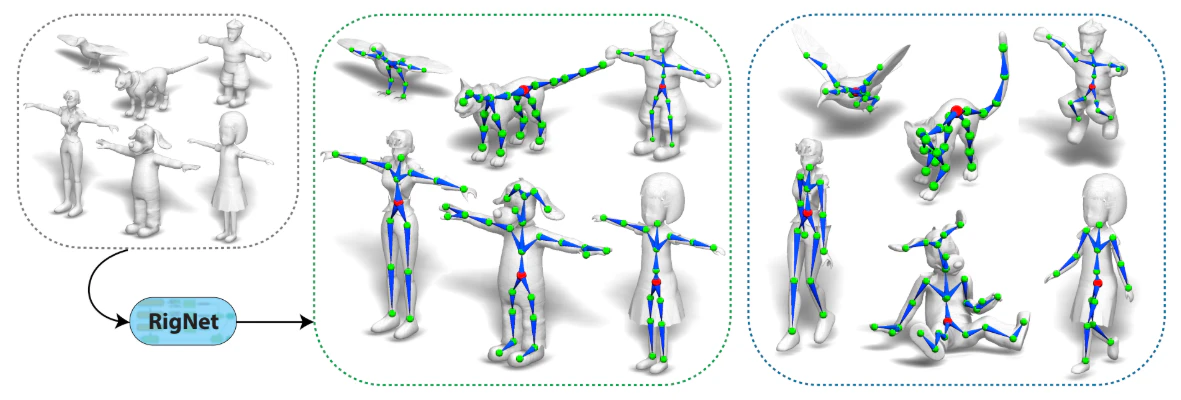
3行要約
- RigNetは、3Dキャラクターメッシュからアニメーションリグ(骨格とスキンウェイト)を自動生成する、エンドツーエンドの深層学習手法です。
- 本手法は、グラフニューラルネットワークを用いて関節位置を予測し、その接続確率から最小全域木アルゴリズムで骨格を構築し、さらに骨格に応じたスキンウェイトを算出するモジュール式のアーキテクチャを採用しています。
- 既存の手法と比較して、多様なキャラクターに対し、関節配置、骨格トポロジー、およびスキン変形において、よりアニメーターの期待に沿う高精度なリギング結果を生成することを示しています。
Q:何が問題で、それをどのように解決したのか、わかりやすく説明してください
A:
この論文は、3Dキャラクターをアニメーション化するために不可欠な「リギング」というプロセスにおける課題を扱っています。リギングとは、3Dモデルにアニメーション用の「スケルトン(骨格)」を作成し、そのスケルトンに合わせてモデルの表面(「スキン」)がどのように変形するかを定義する「スキンウェイト」を設定する作業です。
問題点:
従来、このリギング作業は、アニメーターが手作業で行う必要があり、非常に時間と労力がかかり、高度な専門知識を要していました。また、ゲームや映画、VR/AR、ソーシャルメディアなど、多様な高品質のアニメーション対応キャラクターに対する需要が急速に高まっており、手作業ではその需要に応えきれないという課題がありました。
これまでの自動リギング手法には、固定されたスケルトンテンプレートを3Dモデルに当てはめるものがありましたが、キャラクターの形状や関節構造がテンプレートと合わない場合に失敗する可能性がありました。また、人間や手など特定の形状クラスに特化したポーズ推定手法とは異なり、汎用的なキャラクターに対応できる自動リギング手法が求められていました。
RigNetによる解決策:
RigNetは、このような課題を解決するために、入力された3Dキャラクターモデルからアニメーションリグを自動生成するエンドツーエンドの深層学習ベースの手法を提案しています。この手法は、与えられた3Dキャラクターメッシュから、そのキャラクターの関節構造に合ったアニメーションスケルトンとスキンウェイトを生成します。
RigNetは以下の3つの主要な段階で構成されています。
-
関節位置の予測 (Skeletal joint prediction):
- 入力メッシュをGraph Neural Network (GMEdgeNet) で処理し、各頂点を潜在的な関節位置へ変位させます。
- 同時に、各頂点が関節位置の特定にどれだけ重要かを示す「ニューラルメッシュアテンション」マップを学習します。
- このアテンションマップと変位した頂点群を用いて、微分可能なクラスタリング手法(平均シフト法)により、関節位置を自動的に検出します。
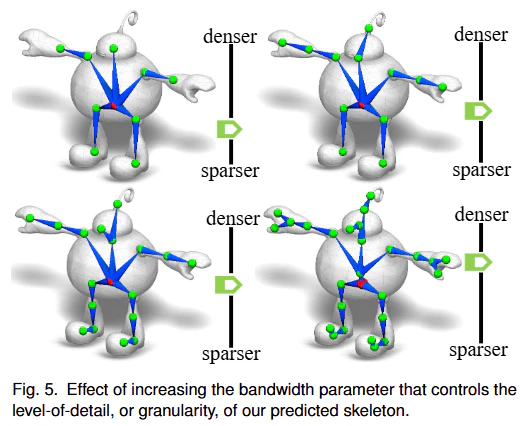
- ユーザーは、単一のパラメータ(帯域幅)を調整することで、出力されるスケルトンの詳細レベル(関節の密度)を制御できます。
-
接続性の予測 (Skeleton connectivity prediction):
- 予測された関節(ジョイント)のペアが、骨(ボーン)として接続される確率を学習するニューラルモジュール「BoneNet」を使用します。BoneNetは、グローバルな形状ジオメトリ、スケルトンジオメトリ、および関節ペアの情報を統合して確率を予測します。
- これらの確率と、RootNetで予測されたルートジョイント(根となる関節)を用いて、最小全域木(MST)アルゴリズム(Prim’s algorithm)を適用し、ツリー構造のアニメーションスケルトンを形成します。
-
スキニングの予測 (Skinning prediction):
- 予測されたスケルトンに基づいて、各メッシュ頂点に対するスキンウェイト(どのボーンから影響を受けるかを示す値)を生成します。
- このモジュールもGMEdgeNetをベースとしており、メッシュ頂点とボーン間のボリューメトリック測地距離を考慮したスケルトン認識型メッシュ表現を使用します。
RigNetの利点:
RigNetは、事前に定義されたスケルトンテンプレートに依存せず、キャラクターの形状クラスや構造に関する仮定を置かないため、人型、四足歩行動物、魚、ロボットなど、非常に多様なキャラクターに対応できます。大規模で多様なリグ付きモデルのデータセットで学習することで、アニメーターの期待に応えるスケルトンとスキンウェイトを生成し、定量的な比較において既存の手法よりも優れた結果を示しています。
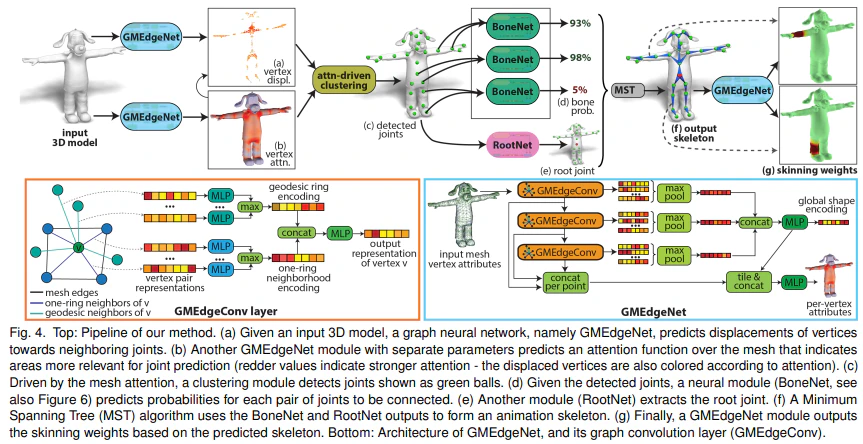
Q:この論文の概要を教えてください
A:
本論文「RigNet: Neural Rigging for Articulated Characters」は、3Dキャラクターモデルからアニメーションリグを自動的に生成するエンドツーエンドの深層学習手法、RigNetを提案します。従来の、事前定義されたスケルトンテンプレートにフィットさせる手法や、特定の形状クラス(例:人間や手)に特化した姿勢推定アプローチとは異なり、RigNetは入力キャラクターの形状クラスや固定された骨格構造に制約されず、多様なキャラクターに対応します。本手法は、入力メッシュ表現に直接作用し、アニメーターの期待に沿うジョイント配置、トポロジー、およびスキニングウェイトを予測します。
RigNetのアーキテクチャは、以下の3つの主要モジュールで構成されます。
-
Skeletal joint prediction(骨格関節予測):
このモジュールは、アニメーションスケルトンを構成するジョイントの3D位置を予測します。まず、グラフニューラルネットワーク(Graph Neural Network; GNN)であるGMEdgeNetを用いて、入力メッシュの頂点位置を近隣の候補ジョイント位置へ変位させます。この変位は、メッシュ表面上の特定の領域がジョイントの位置特定により関連することを学習する「ニューラルメッシュアテンション(neural mesh attention)」関数によって重み付けされます。より高いアテンション値を持つ領域は、ジョイントが存在する可能性が高いことを示します。変位した頂点は候補ジョイント位置の周りに集中する傾向があり、本手法では、このニューラルメッシュアテンションを利用した微分可能なクラスタリングスキームを用いて、ジョイントの位置を抽出します。クラスタリングにはmean-shiftアルゴリズムの変種が採用され、アテンションが密度推定に影響を与えます。ユーザーは帯域幅パラメータを調整することで、出力スケルトンの詳細度(level-of-detail)を制御できます。例えば、帯域幅を小さくすると、より多くのジョイントが生成され、スケルトンの詳細度が増します。3Dキャラクターが持つ両側対称性を考慮し、クラスタリング前に変位した点とアテンションマップを対称化することで、堅牢性を高めています。GMEdgeNetのコアである
GMEdgeConv層は、[Wang et al. 2019]のEdgeConvオペレーターを拡張したものです。メッシュの1-ring近傍と、中心点から測地線距離で定義されるボール内の頂点の両方を考慮したグラフ近傍を使用します。それぞれの近傍に対して異なるMulti-Layer Perceptron (MLP) を学習し、その出力を連結してさらに別のMLPで処理することで、トポロジーとジオメトリの両方を考慮した特徴表現を学習します。トレーニングでは、予測されたジョイントと正解ジョイント間の対称Chamfer距離を最小化する損失関数
$$ \mathcal{L}_{\text{JP}}(\mathbf{w}_a, \mathbf{w}_d, \eta) = \frac{1}{|E|}\sum_{e=1}^{|E|} \min_j ||\mathbf{t}_e - \hat{\mathbf{t}}_j|| + \frac{1}{|\hat{J}|}\sum_{j=1}^{|\hat{J}|} \min_e ||\mathbf{t}_e - \hat{\mathbf{t}}_j|| $$
を使用します。ここで $\mathbf{t}_e$ はクラスタリング後の頂点位置、$\hat{\mathbf{t}}_j$ は正解ジョイント位置、$\mathbf{w}_a, \mathbf{w}_d$ はアテンションモジュールと変位モジュールのパラメータ、$\eta$ は帯域幅です。さらに、クラスタリング前の変位した点に対するChamfer距離損失
$$ \mathcal{L}'_{\text{JP}}(\mathbf{w}_d) = \frac{1}{|E|}\sum_{e=1}^{|E|} \min_j ||\mathbf{q}_e - \hat{\mathbf{t}}_j|| + \frac{1}{|\hat{J}|}\sum_{j=1}^{|\hat{J}|} \min_e ||\mathbf{q}_e - \hat{\mathbf{t}}_j|| $$
と、アテンションウェイトに対するクロスエントロピー損失
$$ \mathcal{L}_{\text{attn}}(\mathbf{w}_a) = \sum_{e} \hat{m}_e \log a_e + (1 - \hat{m}_e) \log(1 - a_e) $$
も使用されます。$\mathbf{q}_e$ は変位した点、$\hat{m}_e$ は正解ジョイントに近い頂点を示すバイナリマスク、$a_e$ は予測アテンション値です。
-
Skeleton connectivity prediction(骨格接続予測):
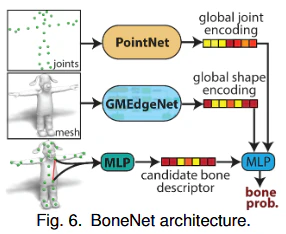
抽出されたジョイント群がどのように骨で連結されるべきかを決定します。このモジュール(BoneNet)は、各ジョイントペアを骨で接続する確率 $\mathcal{P}_{i,j}$ を出力します。BoneNetは、グローバル形状ジオメトリ(GMEdgeNetから抽出)、グローバルスケルトンジオメトリ(ジョイント群を点群と見なしPointNetで処理)、およびジョイントペアの記述子(ジョイント位置、ユークリッド距離、候補骨がメッシュ外部にある割合)を結合して特徴量を生成します。これらの特徴量に基づいて、2層のMLPとシグモイド関数により接続確率が計算されます。
$$ \mathcal{P}_{i,j} = \sigma(\text{MLP}(\mathbf{f}_{i,j}, \mathbf{g}_S, \mathbf{g}_J; \mathbf{w}_c)) $$
ここで $\mathbf{f}_{i,j}$ はジョイントペア記述子、$\mathbf{g}_S$ はグローバル形状表現、$\mathbf{g}_J$ はグローバルジョイント表現、$\mathbf{w}_c$ はBoneNetの学習パラメータです。
これらの接続確率の負の対数 $-\log \mathcal{P}_{i,j}$ をエッジコストとして、Prim'sアルゴリズムによる最小全域木(Minimum Spanning Tree; MST)を構成することで、ツリー構造のアニメーションスケルトンを抽出します。MSTの開始点となる根ジョイント(root joint)も、RootNetと呼ばれる別のニューラルモジュールによって予測されます。RootNetは、グローバル形状表現、グローバルジョイント表現、およびジョイント位置と両側対称面からの距離を含むジョイント表現を入力として、softmax関数により根ジョイント確率を予測します。
トレーニングでは、正解の隣接行列と予測確率の間のバイナリクロスエントロピー損失を最小化します。クラス不均衡問題にはオンラインハードサンプルマイニングで対処します。
-
Skinning prediction(スキニング予測):
予測されたアニメーションスケルトンに基づいて、各メッシュ頂点に対するスキニングウェイトベクトルを生成します。このモジュールは、まずスケルトン対応メッシュ表現を構築します。これは、各メッシュ頂点と骨との間の体積測地線距離を計算し、その距離が近い順に最大$K=5$本の骨の情報をエンコードした特徴ベクトルから構成されます。具体的には、頂点位置と、各頂点に最も近い$K$本の骨の開始・終了ジョイント3D位置および測地線距離の逆数を連結した特徴ベクトル $\mathbf{h}_e$ が使用されます。このスケルトン対応メッシュ表現をGMEdgeNetで処理し、MLPとsoftmax関数を通して、各頂点に対するスキニングウェイトベクトル $\mathbf{s}_e$ を出力します。softmaxにより、各頂点に対するウェイトは正であり、総和が1になります。
$$ \mathbf{S} = \text{softmax}(\text{MLP}(\text{GMEdgeNet}(\mathbf{H}; \mathbf{w}_s))) $$
ここで $\mathbf{H}$ はスケルトン対応メッシュ表現、$\mathbf{w}_s$ はスキニングネットワークの学習パラメータです。
トレーニングでは、正解スキニングウェイトと予測スキニングウェイト間のクロスエントロピー損失
$$ \mathcal{L}_{\text{Skin}}(\mathbf{w}_s) = \frac{1}{|E|}\sum_{e}\sum_{k} \hat{S}_{e,k} \log S_{e,k} $$
を最小化します。
本手法は、多様なキャラクターを含む「ModelsResource-RigNetv1」データセットで学習・評価されました。定量的評価では、ジョイントおよび骨のChamfer距離、骨格のIoU、Precision/Recall、ツリー編集距離(TreeEditDist)、スキニングウェイトのPrecision/Recall、L1-norm、変形後の平均/最大距離などの複数の指標を用い、既存のPinocchio、[Xu et al. 2019]、NeuroSkinning、GeoVoxelなどの手法と比較して、全ての指標で優れた性能を示しています。また、アブレーションスタディにより、アテンションモジュール、測地線近傍を含むGMEdgeConv、および骨格・形状表現の組み合わせが、RigNetの性能に大きく寄与していることが示されました。
RigNetは、トレーニングデータとは異なる構造を持つキャラクター(例:複数の尾を持つ四足動物)に対しても合理的なスケルトンを生成できる高い汎化能力を示します。これにより、カジュアルユーザーや初心者、あるいは大量の3Dキャラクターを自動でリグする必要があるシナリオにおいて、キャラクターアニメーションの民主化に貢献すると考えられます。今後の研究としては、ステージ間での損失の直接的な逆伝播、メッシュ解像度・接続性に対する不変性の改善、スケルトン形態や解像度をインタラクティブに制御するためのより豊かなパラメータ空間の探索などが挙げられます。
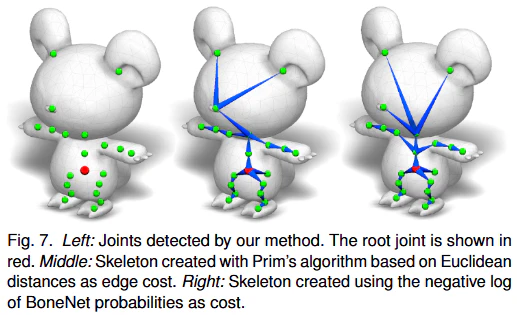
Q:関連手法との比較について詳しく説明してください
A:
RigNetは、自動リギングという複雑なタスクにおいて、既存の多くの関連手法と比較して優れた性能を示しています。ここでは、主な関連手法とRigNetがどのように異なるか、そしてその優位性について詳しく説明します。
RigNetが比較対象としている関連手法は、大きく分けて「スケルトン予測(骨格生成)」と「スキニング予測(スキンウェイト生成)」の2つのカテゴリに分類できます。
1. スケルトン予測に関する比較
RigNetは、入力3Dキャラクターモデルに対して、そのキャラクターに特化したスケルトンのトポロジーとジョイント配置を予測します。
比較対象手法:
-
Pinocchio [Baran and Popović 2007]:
- 手法の概要: これは、自動リギングの先駆的な手法であり、事前に定義されたスケルトンテンプレート(例: 人型、四足歩行型など)を3Dモデルにフィッティングさせることでスケルトンを生成します。
-
RigNetとの違い・優位性:
- テンプレート依存性: Pinocchioはテンプレートに依存するため、入力形状がテンプレートと互換性がない場合(例: 尾や服など、テンプレートにないパーツを持つモデル)には、不自然なスケルトンを生成したり、フィッティングが失敗したりする可能性があります。
- 汎用性: RigNetはテンプレートを使用せず、学習ベースで多様なキャラクター(人型、四足動物、鳥、魚、ロボット、おもちゃなど)に対応できる汎用性を持っています。
- 定量評価: スケルトン予測の定量評価では、RigNetはPinocchioを全ての指標(CD-J2J, CD-J2B, CD-B2B, IoU, Precision, Recall)で上回っています。
-
Xu et al. [Xu et al. 2019]:
- 手法の概要: この手法は、3Dポーズ推定アプローチにインスパイアされており、3Dキャラクターをボクセル表現に変換し、ボリューメトリックなネットワークを用いてスケルトンを学習します。ただし、スキニングは行いません。
-
RigNetとの違い・優位性:
- 入力表現: Xu et al.はボクセル表現を使用するのに対し、RigNetはメッシュ表現に直接作用します。
- 情報損失: ボクセル化は、肘や膝などの正確なジョイント検出に役立つ表面の細かい特徴を失わせたり、入力形状のトポロジーを変更したり、近似誤差を蓄積させたりする可能性があります。RigNetはこれらの情報損失なしに、より正確なジョイントを予測します。
- 定量評価: RigNetはXu et al.のモデルと比較しても、スケルトン予測の全ての定量指標で優れた結果を示しています。
2. スキニング予測に関する比較
RigNetは、予測されたスケルトンに基づいて、メッシュ頂点ごとにスキンウェイトベクトルを生成します。
比較対象手法:
-
Bounded-Biharmonic Weights (BBW) [Jacobson et al. 2011]:
- 手法の概要: これはジオメトリベースのスキニング手法で、メッシュを四面体化し、ボリューメトリックなバイハーモニック関数に基づいてスキンウェイトを計算します。
-
RigNetとの違い・優位性:
- 解剖学的考慮: BBWのようなジオメトリベースのアプローチは、メッシュ内に含まれる解剖学的な考慮事項(例えば、アニメーターが意図する脊椎の位置や皮膚の柔軟性/剛性)を考慮することが困難です。
- データ駆動: RigNetはデータ駆動型のアプローチであるため、アニメーターが作成したリグに含まれる解剖学的な洞察を学習し、反映させることができます。
- 定量評価: RigNetはBBWと比較して、Precision, Recall, L1-norm, 平均変形距離、最大変形距離といったスキニングの全ての定量指標で大幅に優れた結果を示しています。
-
NeuroSkinning [Liu et al. 2019]:
- 手法の概要: この手法も学習ベースで、Graph Convolutionを使用してメッシュ近傍内のエッジウェイトを学習し、頂点の特徴を隣接頂点の特徴の重み付き組み合わせとして出力することでスキニングを試みます。
-
RigNetとの違い・優位性:
- 特徴表現: RigNetは、メッシュ内および測地線上の近傍におけるエッジ特徴表現を学習し、メッシュトポロジー、ローカルおよびグローバル形状ジオメトリからの表現を組み合わせます。
- ボーンカテゴリの不要性: NeuroSkinningとは異なり、RigNetは学習時やテスト時にジョイントのカテゴリ分けを必要としません。
- エンドツーエンドソリューション: 最も重要な点として、NeuroSkinningは部分的なスキニングソリューションであるのに対し、RigNetはスケルトンとスキニングの両方を予測する完全なエンドツーエンドソリューションを提供し、より優れた結果を達成しています。
- 定量評価: RigNetはNeuroSkinningを全てのスキニング定量指標で上回っています。
-
GeoVoxel [Dionne and de Lasa 2013]:
- 手法の概要: これはジオメトリベースの手法で、ボリューメトリック測地距離に基づいて頂点に対するボーンの影響を計算することでスキンウェイトを出力します。
-
RigNetとの違い・優位性:
- パラメータ調整: GeoVoxelは、最適な結果を得るために、各テスト形状ごとにパラメータ(影響するボーンの最大数、ウェイトプルーニング閾値、ドロップオフパラメータなど)を手動で調整する必要があり、これは手間がかかる作業です。
- 学習ベースの適応性: RigNetは学習ベースであり、骨と頂点-スケルトン間の固有距離を組み合わせることで、関節部位の分離がより良いスキンニングを生成します。
- 定量評価: RigNetはGeoVoxelと比較しても、全てのスキニング定量指標で優れた性能を発揮しています。
総じて、RigNetは、既存の自動リギング手法が抱えていたテンプレート依存性、情報損失、解剖学的考慮の欠如、手動パラメータ調整の必要性といった課題を、エンドツーエンドの深層学習アプローチ、特にメッシュグラフに直接作用するGraph Neural Networkと、ニューラルメッシュアテンション、微分可能なクラスタリング、豊富な特徴表現の組み合わせによって克服しています。これにより、多様な3Dキャラクターに対して、アニメーターの期待に沿う高品質なリグを自動生成することが可能になっています。
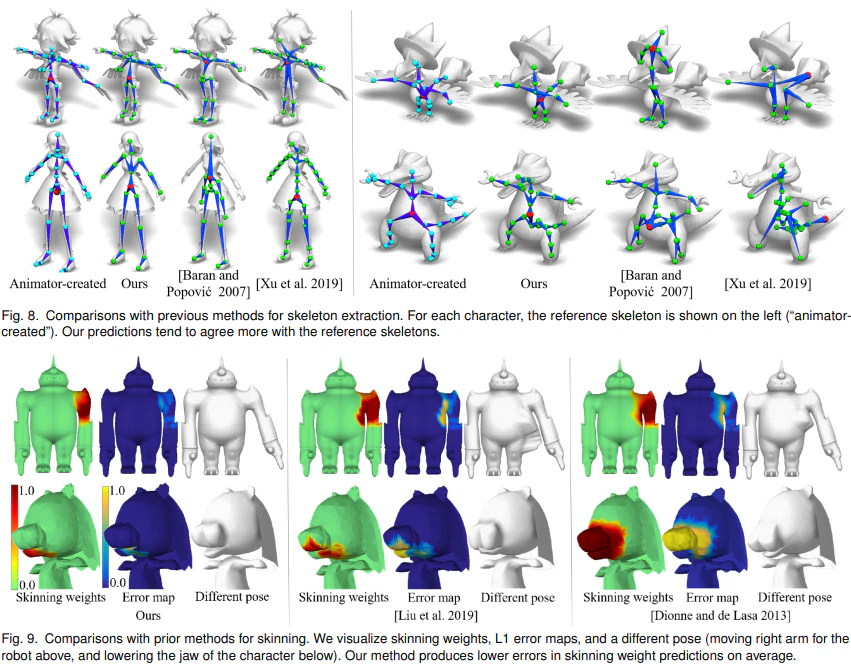
Q:提案手法の限界と今後の課題はなんですか?
A:
RigNetの提案手法にはいくつかの限界があり、それらが今後の研究の興味深い方向性を示唆しています。
RigNetの限界:
-
段階的な学習プロセス (Per-stage training):
RigNetは現在、関節予測、ボーン接続、スキニング予測の各段階を個別に学習しています。理想的には、スキニングのロス(損失関数)をネットワーク全体のすべての段階に逆伝播させることで、関節予測の精度をさらに向上させることができます。しかし、ボリューメトリック測地距離の微分やスケルトン構造の推定といった複雑なタスクを微分可能にするのは、非常に困難な課題です。 -
メッシュ表現への依存と不変性 (Invariance to mesh resolution and connectivity):
RigNetは、メッシュ表現に直接作用するGraph Neural Network (GNN) を使用していますが、異なるメッシュの解像度や接続性に対する不変性は保証されていません。これは、入力メッシュのテッセレーション(網目の細かさ)にネットワークが敏感になる可能性があることを意味します。 -
不適切なジョイント予測 (Undesirable joint predictions):
ごく稀に、腕に余分なジョイントが配置されるなど、望ましくない予測が生じる場合があります。 -
データセットの限界と特定のパーツのリグの欠如 (Dataset limitations and missing helper joints):
学習に用いたデータセットは、1つのモデルに対して1つのリグしか含まれていません。多くの場合、足、指、服、アクセサリーといった小さなパーツのボーンが含まれていないリグも存在するため、学習済みモデルがこれらのジョイントを正確に予測しにくいという問題があります。
今後の課題と研究の方向性:
-
エンドツーエンドの微分可能システム (End-to-end differentiable system):
上記の「段階的な学習プロセス」の限界を克服し、スキニングの品質がジョイントとボーンの配置に直接影響を与えるような、完全にエンドツーエンドで微分可能なリギングパイプラインを構築することが重要です。 -
メッシュ不変性の強化 (Enhancing mesh invariance):
メッシュの解像度やトポロジーの違いに、よりロバストなネットワークアーキテクチャを探求することが考えられます。例えば、スペクトルグラフ畳み込みのような他のメッシュニューラルネットワークの性能を調査することも有益かもしれません。 -
データセットの拡充とマルチモーダルなマッピング (Enriching datasets and multi-modal mapping):
より多様なリグ(特に小さなパーツやヘルパージョイントを含むもの)でデータセットを充実させることで、モデルの予測能力が向上する可能性があります。ただし、これによりマッピングがよりマルチモーダルになる可能性も考慮する必要があります。 -
多段階リファインメントとインタラクティブな制御 (Multi-resolution refinement and interactive control):
スケルトンを粗いレベルから細かいレベルへと洗練させていく多段階(マルチレゾリューション)のアプローチは、非常に有効かもしれません。また、現在の帯域幅パラメータが1つの制御方法を提供する一方で、スケルトンの形態や解像度をインタラクティブに制御するための、より豊かなパラメータ空間を探求することも興味深い研究方向です。 -
点群データへの拡張 (Extension to point cloud data):
現在のメッシュベースの入力に加えて、点群データからのスケルトン抽出にも本手法を拡張することは、点群認識や再構成タスクにおいて新たな応用を生み出す可能性があります。
これらの限界を克服し、今後の課題に取り組むことで、RigNetのような自動リギング技術はさらに進化し、3Dコンテンツ制作の民主化に大きく貢献するでしょう。
Q:この手法の最も大きな欠点は何ですか?
A:
RigNetの提案手法の最も大きな欠点は、学習プロセスが各モジュールで独立しており、完全なエンドツーエンドでの最適化が行われていない点です。
論文では、各段階(ジョイント予測、接続性予測、スキニング予測)が独立して学習されていると明確に述べられています。
この「per-stage training (段階的な学習)」は、以下の点で大きな欠点となります。
-
スキニング品質がジョイント/ボーン予測にフィードバックされない:
最も重要な問題は、最終的なリギングの目的である「高品質なスキニング結果(キャラクターが自然に変形すること)」が、スケルトンのジョイント位置や接続性の学習に直接反映されないことです。論文では、「理想的には、スキニングのロスをネットワークの全ての段階に逆伝播させることで、ジョイント予測を改善できる」と述べていますが、現状ではこれが実現できていません。
もしスキニングの質がジョイントとボーンの配置に直接影響を与えるように学習できれば、よりアニメーションに適したリグが生成されるはずです。 -
微分可能なパイプラインの複雑さ:
このエンドツーエンドの最適化が実現できない理由として、論文では「ボリューメトリック測地距離の微分やスケルトン構造推定の微分が難しいタスクであるため」と説明しています。 RigNetは、ジョイント予測段階で微分可能なクラスタリング手法を導入していますが、全体のパイプラインを微分可能にすることは依然として大きな技術的課題です。 -
部分最適化の可能性:
各モジュールが独立して最適化されるため、それぞれのモジュールは自身が担当するタスク(例: ジョイントの正確な位置特定、ボーン接続の正確な予測など)を最適化します。しかし、これらの部分的な最適化が、最終的な目標である「高品質でアニメーションに適したリグ全体」の最適化につながるとは限りません。例えば、ジョイント位置が数学的に正確でも、アニメーションの観点から自然な動きを妨げる場合があり得ます。
この欠点は、RigNetが「学習ベースの自動リギングにおける最初のステップ」と位置づけられている理由でもあり、今後の研究の最も重要な方向性の一つとして挙げられています。