この記事は何?
Justin Thaler先生が以下の論文を最近投稿したようなので、これを雑にまとめていく記事を書きます。タイトルの通り、sumcheckプロトコルの魅力が語られていく論文(Opinionated Survey)です。
https://eprint.iacr.org/2025/2041.pdf

part6は7章についてまとめます, zkVM、Joltについてです
TL;DR
- ダルくなってきたのでほぼLLMベースの記事です
- zkVMというのがあるんですね
- circuit-SATから、VM上での計算実行証明すればいいやん、ってことですね
- 前回の記事で紹介した要素技術(Twist, Shout)を活かしたzkVMの1つ、Joltが紹介されてます
ケーススタディ - zkVMsとJolt(7章)
zkVM(Zero-Knowledge Virtual Machine)とは
- 汎用SNARKエンジン
- 低レベルプログラムの正しい実行を証明
- 通常、特定のISA(命令セットアーキテクチャ)のアセンブリまたはバイトコードで記述
How?
- (circomとかで)回路を記述する代わりに任意の高級プログラミング言語でコードを記述
- VMのバイトコードにコンパイル
- バイトコードの正しい実行証明を自動生成
注意: Zero-knowledgeの誤称
- 「Zero-knowledge」はしばしば誤称
- 多くのzkVMsは、VM実行のための非ゼロ知識SNARKである
- これに限らずzk~Rollupとかもそう
zkVMの利点
1. 使いやすさ(Ease of use)
- 開発者は通常のコードを書くだけでよい
- 算術回路を作成する必要がない
2. 既存のツールチェーン活用(Pre-existing tooling)
- 高級プログラミング言語から低レベル表現(回路またはVMバイトコード)への最適化された、バグのないコンパイラの開発は膨大な作業
- RISC-Vのような標準ISAをターゲットとするzkVMは:
- すでに十分な精査と最適化を受けた既存のコンパイラを再利用可能
よくある誤解:zkVMは遅い?
一般的な誤解
- zkVMは「Circuit-SAT SNARKs」(手作りの回路に直接適用されるSNARKs)より遅いはず
- なぜなら:
- zkVM証明者は仮想CPUをシミュレート
- 元の計算を慎重に回路化した場合よりも、はるかに多くの内部ステップが必要
- 別途作成した算術回路はハードウェアASICのように単一タスクに特化
- CPUは柔軟性の代償として、毎サイクルfetch-decode-executeの追加作業を行う
実際はそうではない
理由:
すべての追加作業が高度に構造化され、サイクル全体で同一に繰り返される
VMの繰り返し構造の特徴
-
同じ少数の命令を何度も実行
- 数百万、数十億、数兆回のfetch、decode、execute
-
同じ小さなレジスタセットから毎サイクル読み書き
-
正しい実行を強制する制約システム
- 短く、固定され、サイクル全体で再利用される
-
VM内部で発生する値は小さな整数
- レジスタ、アドレス、即値
- 理由: 標準VMのネイティブデータ型は32または64ビットのみ
Sum-checkプロトコルによる最適化
SNARK証明者の利点
- Sum-checkプロトコルの洗練された適用により、繰り返し構造を活用
- ネイティブ実行(実行証明なしでCPUで計算を単に実行)に対する証明のオーバーヘッドを最小化
Jolt zkVM
概要
Jolt[AST24]は標準RISC-Vアーキテクチャ向けのzkVM
- ターゲット: RV64IMAC
- RISC-V with 64-bit registers
- Multiplication extension、その他
繰り返し構造の最大限の活用
VMの各サイクルは以下のようにSNARK化される:
1. Fetch(フェッチ)
- VMがプログラムバイトコードから読み取り、実行する命令を決定
-
Shoutを使用(read-only memoryのmemory-checkerとして)
- この読み取りが正しく応答されたことを証明
2. Decode and Execute(デコードと実行)
- VMが最大2つのレジスタを読み取る
- 返された値に適切な命令を適用
- 結果を指定された出力レジスタに書き込む
- Twistを使用: レジスタの読み書きが正しく実行されたことを証明
- Shoutを使用(batch-evaluation argumentとして): 命令実行が正しいことをチェック
3. RAM Access(RAMアクセス)
- 命令がLoadまたはStoreの場合、VMがメインメモリ(RAM)から読み書き
- Twistの2つ目のインスタンスを使用: メモリアクセスが正しく処理されたことを証明
4. Constraint Checking(制約チェック)
- Joltはグローバルな正しさを強制
- VMの遷移制約が満たされていることをチェック
-
Spartanを使用: 約20個の小さな制約セットの充足を証明
- 各サイクルで同一に繰り返される構造
- Joltの変種Spartanはこの構造の活用に最適化されている
Joltアーキテクチャの概要図
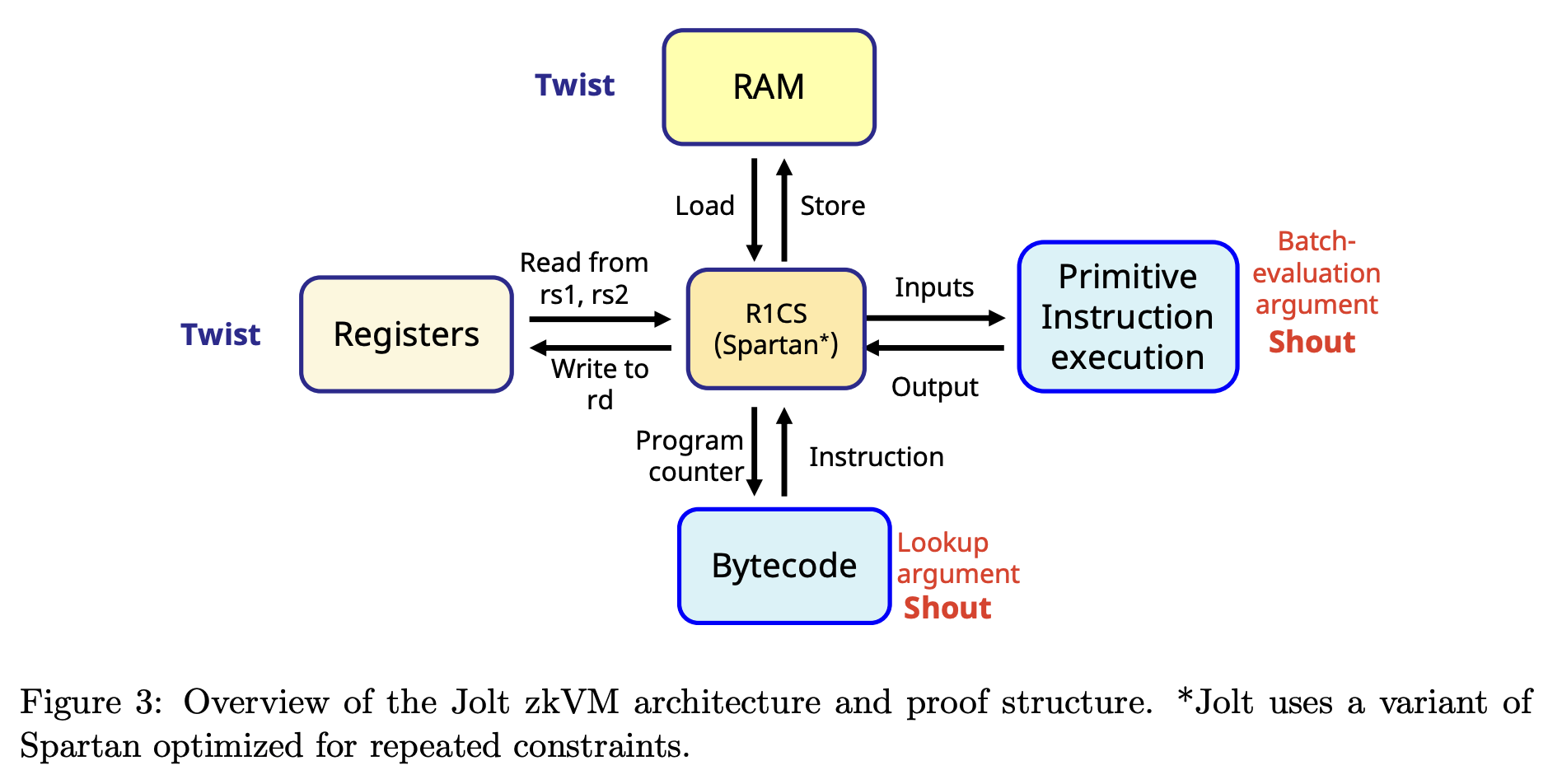
論文Figure 3より
- Joltは繰り返し制約に最適化されたSpartanの変種を使用
- 複数のTwistインスタンスが使用される
パフォーマンス
実世界のプログラムでの性能
証明サイズ: 約50 KB
証明者スループット: 一般的なCPUでMHzレンジ
- 高性能MacBook: 500,000+ RV64IMACサイクル/秒
- 32コアマシン: 1.5百万+ サイクル/秒[GMT+25]
性能特性:
- 証明者の速度は主にVMサイクル数に依存
- 実行される特定の計算への感度は低い
他のSNARKsとの比較
パフォーマンスレベル:
- 手動で最適化された算術回路に適用される人気のSNARKsと同等、多くの場合それ以上
Joltの優位性:
- Circuit-SAT SNARKsと異なり:
- ✅ 汎用
- ✅ 柔軟
- ✅ 使いやすい
教訓:
Sum-checkベースのSNARKsが構造を活用することで、速度とシンプルさの両方を達成できることを実証
理論的予測と実測の一致
パフォーマンスの事前予測
重要な点:
- Joltのパフォーマンスは経験的な驚きではなかった
- 証明者のワークロードの理論的会計によって事前に予測されていた[ST25]
具体的な計算
Jolt証明者の作業量:
- RV64IMACサイクルあたり約500回の体乗算(256ビット体上)
- 注:Dory評価証明コストの除外
- この推定値は、Dory評価証明などのコストを除外
- 小規模実行(数千万サイクル未満)では、証明者時間の大部分を占める可能性
- より大規模なワークロードでは無視できるレベルになる
- 注:Dory評価証明コストの除外
体乗算のコスト:
- 保守的な仮定の下で、1回の体乗算は約100 CPUサイクル[Xop]
期待される証明者コスト:
- VMサイクルあたり50,000 CPUサイクル
理論的スループット計算:
-
シングルスレッド4 GHzコアでの期待スループット: 約80,000 VMサイクル/秒
- 注: ハードウェアプラットフォームの制約
- GPU等のハードウェアプラットフォームでは、Sum-checkベースのSNARK証明者実行時に計算よりもメモリ帯域幅が制限要因になる可能性
- ボトルネックは異なるが、スループットは通常同じオーダーマグニチュード内に留まる
- 注: ハードウェアプラットフォームの制約
- 16スレッドでのスケーリング: 約1百万 VMサイクル/秒
結果: 観測されたパフォーマンスと密接に一致
工学的努力の重要性
実装の現実
認識すべき点:
- 実際のハードウェアは複雑
- このレベルのパフォーマンスに到達するには相当な工学的努力が必要
理論的基礎の重要な役割
理論が果たす役割:
-
正確な操作カウントなしでは:
- パフォーマンスチューニングは当て推量になる
- プロトコル設計者は、システムのどの部分が期待より遅いのか分からない
-
経験的ベンチマークの限界:
- 貴重ではあるが実装の成熟度を無視した比較は誤解を招く
- 最適でないベースラインとの比較も同様
結論:
正確な操作レベルのコスト分析は、トレードオフを理解し、実用的なSNARK設計を導くために不可欠