はじめに
この記事では、書籍「実践XAI[説明可能なAI] 機械学習の予測を説明するためのPythonコーディング」を参考にして、LIMEによる機械学習モデルの局所的・大域的説明の方法および簡単な理論を解説します。
LIMEの理論
LIMEはLocal Interpretable Model-agnostic Explanationsの略で、
論文「“Why Should I Trust You?”Explaining the Predictions of Any Classifier」にて提案された手法です。
LIMEのお気持ち
LIMEでは何をやっているかをひとことで表すと
「複雑なAIを説明する、簡単な(解釈可能な)AIを作る」
ということになります。
もう少し具体的に言うと、
「複雑なモデルを説明するために、それを局所的に近似する線形モデルを学習させ、回帰係数で解釈する」
となります。
LIMEを数式使って説明
モデル$f$があって、インスタンス$x$に対する予測値$f(x)$の説明が欲しい、とします。
LIMEでは説明対象$x$の近傍で$f$を近似する説明器$g$を作ることを目指します。
$g$は線形回帰モデルとします。
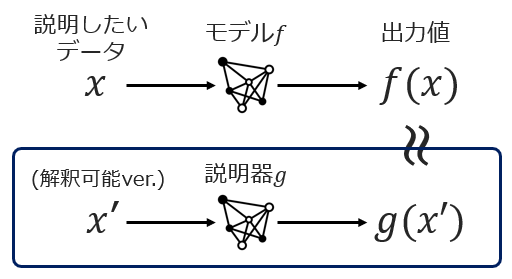
ただし注意なのが、$g$の入力は$f$の入力とは違うということです。
上図にあるとおり、$g$の入力は解釈可能な入力となっています。
これはどういうことか、自然言語処理を例に考えてみます。
モデル$f$を学習させる際、「単語ベクトル」を入力として与えることが多いですね。
$$\text{apple} = (0.1,1.5,0.6,0.2,\cdots, 1.1)$$
しかし単語ベクトルを我々人間が見たとて、意味を解釈することは困難です。
なので説明器$g$の入力として単語ベクトルを採用した場合、たとえ線形モデル$g$を構築して回帰係数を手に入れることができたとしても、回帰係数の意味を解釈することができなくなってしまいます。
そこで、モデル$f$の学習で使った特徴量$x$とは別に、説明器$g$で使う用の特徴量$x'$を用意します。
$x'$は解釈可能な表現、つまり
$$\text{apple} = (0,1,0,0,\cdots,0)$$
のようなOne-hot表現とします。
まとめると、
- モデル$f$を説明対象$x$のまわりで近似する説明器$g$を構築する。
- $g$には線形モデルなどの解釈性の高いモデルを用いる。
- $g$で使う特徴量は解釈可能な表現(One-hot)とする。
です。
LIMEを使ってみる
Pythonライブラリlimeを使ってみましょう。
limeはpipでインストールできます。
pip install lime
以下は、limeの公式チュートリアル[1]を参考にして実装の解説していきます。
例1:テキスト分類(2クラス分類)
Notebookはこちら→Basic usage, two class. We explain random forest classifiers.
各テキストが「無神論者(atheism)」か「キリスト教徒(christian)」のどちらが書いたものかを予測するタスクです。
まずはLimeTextExplainerをインポートしてインスタンス化します。
引数class_namesには、クラス名の配列を入れます。
from lime.lime_text import LimeTextExplainer
explainer = LimeTextExplainer(class_names=class_names)
# class_names = ['atheism', 'christian']
次に説明器を作成します。
exp = explainer.explain_instance(
data_row,
classifier_fn,
num_features=10,
num_samples=5000)
引数の意味は以下のとおりです。
-
data_row:説明対象のインスタンス。(numpyの2次元配列) -
classifier_fn:確率値を返すモデル関数。(sklearnのモデルなら.predict_proba) -
num_features:説明可視化で表示する特徴量の最大個数。 -
num_samples:近傍点の個数。
説明を可視化するには、次を実行します。
exp.show_in_notebook()

左にはモデルの予測結果が表示されています(atheismの確率が59%、christianの確率が41%)。
中央には、説明器$g$の回帰係数が表示されています。
一番上は「Posting」が0.16となっています。$g$の特徴量はOne-hotであることを思い出すと、
単語「Posting」があることによって、確率値に+0.16の寄与をしている
と見ることができます。
右にはテキストとハイライトが表示されています。
中央の寄与度をハイライトで可視化したもので、色が濃ければ寄与が大きいことを表します。
例2:画像分類
Notebookはこちら→Images - basic
各テキストが「無神論者(atheism)」か「キリスト教徒(christian)」のどちらが書いたものかを予測するタスクです。
まずはLimeImageExplainerをインポートしてインスタンス化します。
また、superpixel生成のためにmark_boudariesもインポートしておきます。
from lime.lime_image import LimeImageExplainer
from skimage.segmentation import mark_boundaries
explainer = LimeImageExplainer()
次に説明器を作成します。
exp = explainer.explain_instance(
image,
predict_fn,
hide_color=0,
num_samples=1000)
引数の意味は以下のとおりです。
-
image:説明対象のインスタンス。 -
predict_fn:確率値を返すモデル関数。 -
hide_color:塗りつぶされないスーパーピクセルの色。 -
num_samples:近傍点の個数。
説明を可視化するには、次を実行します。
import matplotlib.pyplot as plt
label = 286
temp, mask = explanation.get_image_and_mask(
label,
positive_only=False,
num_features=10,
hide_rest=False)
plt.imshow(mark_boundaries(temp, mask))

指定したラベルはlabel=286(Egyptian cat)ですが、
ちゃんと猫の部分にpositive(緑色)の反応が出ています。
逆に犬の部分にはnegative(赤色)の反応をしていることがわかります。
例3:回帰タスク
Notebookはこちら→Simple regression
有名なbostonデータセットを使った住宅価格予測タスクです。
まずはLimeTabularExplainerをインポートしてインスタンス化します。
from lime.lime_tabular import LimeTabularExplainer
explainer = LimeTabularExplainer(
train,
feature_names=feature_names,
class_names=['price'],
categorical_features=categorical_features,
mode='regression')
次に説明器を作成します。
i = 1
exp = explainer.explain_instance(
test[i],
predict_fn,
num_features=5)
説明を可視化するには、次を実行します。
exp.show_in_notebook()

左にはモデルの予測結果が表示されています。
両側にminとかmaxがありますが、よくわかりません。
(各近傍点に対して予測値を出し、その予測値の最大・最小を表しているっぽいですが自信はありません)
中央には、説明器$g$の回帰係数が表示されています。一番上は「6.99<LSTAT<=...」となっています。
ちなみにこの「6.99」はどこから出てきているかというと、四分位点からです(デフォルトでは)。
LimeTabularExplainer()の引数discretizerを指定することで変更することができて、
-
discretizer='quartile':四分位点 -
discretizer='decile':十分位点 -
discretizer='entropy':決定木の閾値
の中から選ぶことができます。
右には説明対象インスタンス自体の値が色付きで表示されています。
付録
ここでは、書籍「実践XAI」における説明やコードの不備、および私からのツッコミを付録として載せておきます。前回記事でも紹介しているので参考にしてください。
A:【誤植】LIMEは画像データには適用できない??
p.75表3-4のLIMEの「制限」のところにこんな記述があります。
大域的な説明が直感的でない。画像データには適用できない。
これはウソですね。
上で見たように、画像をスーパーピクセルに分割することでLIMEを適用することができます。
余談ですがその上にSHAPの「制限」として
明白ではない
とだけ書いてありますが、意味不明です。何が明白ではないのでしょうか…。そもそもあなたの文章が明白ではない。 主語を書いてほしい。
B: pip installで大文字
p.158でpip installのコマンドが書いてあるのですが…
!pip install Lime
なんと大文字始まりで書いてありました。
これじゃエラー吐くだろ、と思ったのですが、実際試してみると普通にインストールしてくれました。
いやぁ~勉強になりますね~![]()
C: 謎のファイル名
p.160のコードを見てください。
plt.savefig('[exp.as_pyplot_figure() for exp in sp_obj.sp_explanations].png', dpi=300)
何でしょう、このファイル名。こんな名前をつける人は初めて見ました。
D: trainデータでモデルを評価している
第7章では、CountVectorizeしたりストップワード除去したりTFIDF使ったりして、いろいろモデルを学習させています。
しかし問題なのが、モデル精度の検証方法です。
モデルを評価する関数はp.164に記載されているのですが、これを見ると訓練データで評価しているように見えます。
手元できちんとtrainとtestを分けて同じようにモデルを組み、精度を検証したところ、本に書いてあるような精度は出ていませんでした。
参考記事
[1] limeのGithubレポジトリ
https://github.com/marcotcr/lime
[2] lime公式ドキュメント
https://lime-ml.readthedocs.io/en/latest/lime.html