(追記 2019.12.14)
Pillowは少なくとも Ver6以降(+raqmの0.7以降)では日本語縦書きが可能になっています。
本記事の内容は古いものなのでご注意下さいませ。
ようするに

という事を考えた次第です。
構成
主に使用しているライブラリは以下。
- xml.etree.ElementTree
- HTMLParser
- Pillow
生成画像の解像度や段組のレイアウトなどをxmlで記述します。特にベースにしているフォーマットはなくて、適当に決めたオリジナルなものです。それをパースするのにxmlライブラリを使用します。本文は基本プレーンテキストで記述して、ルビと傍点は文中にhtml体のタグで記載します。これをパースするのにHTMLParserを使用します。どちらか一方のライブラリで両方を対応出来そうな気もしますが、勉強を兼ねて両方使ってみようと思いそうなりました。
文字を描画するのは画像処理ライブラリのPillowを使用します。当然というか、仕方がない事ですが、Pillowは縦書きには全く対応していないので色々と試行錯誤(手抜き)をして縦書きします。
レイアウトと本文
レイアウトを決めるxmlと本文テキストは以下のような感じ。
<novel width="1920" height="960" margin_up="0.1" margin_bottom="0.1" margin_left="0.05" margin_right="0.05">
<columnchain name="Main" fontsize="36" direction="VERTICAL" linespace="2.0" color="#101000">
<column refp="UP_RIGHT" reflh="MARGIN_RIGHT" reflv="MARGIN_UP" offsetx="LIVEAREA_H:0" offsety="LIVEAREA_V:0" sizew="LIVEAREA_H:1.0" sizeh="LIVEAREA_V:1.0"/>
</columnchain>
<text columnchain="Main" src="yosuruni.xml" />
</novel>
4歳になったうちの子は、かなり字が読めるようになってきた。これからたくさん本を読ませようと思っているが、自分はいままで読書をあまりしてこなかったので、どのような本を選んであげれば良いのかわからなかった。
色々と考えた結果、自分で物語を書いて、それを読ませれば良いのだという事に気が付いた。そもそも本をろくに読んだことがないというのに、物語が書けるのかという事になるが、そこは「おしり」とか「うんこ」とかを適当に書いておけば間違いないだろう。4歳だから。
ところで、メモ帳アプリなんかで書き始めてみると、横書きでは全く<d>らしくない</d>。やはり縦書きでなければ、「読み物」としての<r val="ふんいき">雰囲気</r>が感じられず、見いていて楽しくない。そこで、縦書き可能なエディタを探してみたが、これと思えるものが見つからなかった。
こうなったら作るしかない。エディタのようなアプリは無理だが、プレーンテキストを縦書き画像に変換するツールぐらいなら出来るのではないか……
レイアウトでは、columnchain要素の中のcolumn要素を増やすと段組が増えていき、columnの記述順に本文が流し込まれます。
それぞれレイアウトと本文テキストは基本的には以下のルーチンで解析します。
import xml.etree.ElementTree as ET
# xmlを解析して要素木を得る
tree = ET.parse(xml_path)
# ルート要素を得る。novel要素が得られる
novel_element = tree.getroot()
# ここでnovel要素の属性を参照して設定値を得る
# novel要素内のcolumnchain要素を得る
for cc_element in novel_element.iter("columnchain"):
# ここでcolumnchain要素の属性を参照して設定値を得る
# columnchain要素内のcolumn要素を得る
for c_element in cc_element.iter("column"):
# ここでcolumnc要素の属性を参照して設定値を得る
# novel要素内のtext要素を得る
for text_element in novel_element.iter("text"):
# ここでtext要素の属性を参照して設定値を得る
from html.parser import HTMLParser
class TextParser(HTMLParser):
def __init__(self):
super().__init__()
def handle_starttag(self, tag, attrs):
if tag == "ruby" or tag=="r":
# ルビタグの開始を検知
if tag == "dot" or tag=="d":
# 傍点タグの開始を検知
def handle_endtag(self, tag):
if tag == "ruby" or tag == "dot" or tag == "r" or tag == "d":
# タグの終りを検知
def handle_data(self, data):
# タグ内データの取得。本文そのもの、あるいはルビ(読み仮名文)を得る
class Text():
def __init__(self, source):
parser = TextParser()
parser.feed(source)
実行&出力結果
例えば以下は縦長のレイアウトで3段組。(例なので解像度を低くしています。320x720で文字が12ポイント)
<novel width="320" height="720" margin_up="0.1" margin_bottom="0.1" margin_left="0.05" margin_right="0.05">
<columnchain name="Main" fontsize="12" direction="VERTICAL" linespace="2.0" color="#101000">
<column refp="UP_RIGHT" reflh="MARGIN_RIGHT" reflv="MARGIN_UP" offsetx="LIVEAREA_H:0" offsety="LIVEAREA_V:0" sizew="LIVEAREA_H:1.0" sizeh="LIVEAREA_V:0.3"/>
<column refp="UP_RIGHT" reflh="MARGIN_RIGHT" reflv="MARGIN_UP" offsetx="LIVEAREA_H:0" offsety="LIVEAREA_V:0.35" sizew="LIVEAREA_H:1.0" sizeh="LIVEAREA_V:0.3"/>
<column refp="UP_RIGHT" reflh="MARGIN_RIGHT" reflv="MARGIN_UP" offsetx="LIVEAREA_H:0" offsety="LIVEAREA_V:0.7" sizew="LIVEAREA_H:1.0" sizeh="LIVEAREA_V:0.3"/>
</columnchain>
<text columnchain="Main" src="yosuruni.xml" />
</novel>
$ python NovelFE.py yosuruni_layout.xml
これで以下の画像が出力される。

解像度が低いと微妙に文字の位置揺れ起きて気になる、、、。
縦書き描画
前述のようにPillowでは横書きは出来ますが、縦書きが出来ません。なので、なんちゃって縦書きを行う事にしました。つまり、垂直方向に位置をずらしながら1文字づつ描画します。
フォントは 源暎アンチックを使わせて頂きました。縦書きに対応した漫画向けフォントです。
ところが、いざ描画してみると、あたりまえですけれども、
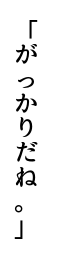
括弧や句読点、小さな「つ」など、横書き用のフォントグリフが使われてしまいます。Pillowライブラリでは、縦書きを指定をする方法が無いので、どうやっても縦書き用のグリフを使ってくれません。
手っ取り早く、どうすればいいかと考えた結果、フォントファイル自体をいじって、横書き用のグリフを縦書き用のグリフで強引に置き換えてやるという事を思いつきました。
pip install fonttools
Python製フォントツール fonttools(ttx)をインストールします。
ttxコマンドでフォントファイルを指定すると、xmlに変換してくれます。
% ttx GenEiAntiqueN-Medium.otf
Dumping "GenEiAntiqueN-Medium.otf" to "GenEiAntiqueN-Medium.ttx"...
Dumping 'GlyphOrder' table...
Dumping 'head' table...
Dumping 'hhea' table...
Dumping 'maxp' table...
Dumping 'OS/2' table...
Dumping 'name' table...
Dumping 'cmap' table...
Dumping 'post' table...
Dumping 'CFF ' table...
Dumping 'BASE' table...
Dumping 'GDEF' table...
Dumping 'GPOS' table...
Dumping 'GSUB' table...
Dumping 'VORG' table...
Dumping 'hmtx' table...
Dumping 'vhea' table...
Dumping 'vmtx' table...
今回使用するフォントはOpenType形式なので、以下で仕様の概要を確認。
OpenTypeの仕様入門 (後編)
[OpenTypeの仕様入門 (中編)]
(http://qiita.com/496_/items/4f8327fe741cf0c87736)
[OpenTypeの仕様入門 (前編)]
(http://qiita.com/496_/items/f6efb650dcf7e9d2dfe4)
上記からすると、ttxで生成されたxmlの中で重要なのは、GSUBとcmapになります。
OpenTypeは大雑把には、IDが振られたグリフ(字体)データが入っていて、
cmapテーブルに、文字(例えばUnicode)コードに対応するグリフデータIDを示す対応表が含まれています。
また、GSUBテーブル内には、特定の条件で使用するグリフが変わる場合、その変更元グリフIDと変更先のグリフIDの対応表が示されています。
なので、縦書きの場合に置き換えるグリフIDを示す対応表をGSUBテーブルの中から抜き出し、それを元に、cmapテーブルの対応表のグリフIDを置き換えてしまいます。そうすれば無条件で縦書き用のグリフを参照するようになるはずです。
変換用のスクリプトを書いてみます。
import argparse
import xml.etree.ElementTree as ET
parser = argparse.ArgumentParser()
parser.add_argument("infile")
args = parser.parse_args()
tree = ET.parse(args.infile)
root = tree.getroot()
list_index = []
cid_replace_dic = {}
for gsub_elements in root.iter('GSUB'):
for featurerecords in gsub_elements.iter('FeatureRecord'):
for featuretags in featurerecords.iter('FeatureTag'):
if featuretags.attrib['value'] == "vert" or \
featuretags.attrib['value'] == "vrt2" or \
featuretags.attrib['value'] == "vtrt":
for lookuplistindexs in featurerecords.iter('LookupListIndex'):
if not lookuplistindexs.get('value') in list_index:
list_index.append(lookuplistindexs.get('value'))
for lookup in gsub_elements.iter('Lookup'):
if lookup.get('index') in list_index:
for substitution in lookup.iter('Substitution'):
cid_replace_dic[substitution.get('in')] = substitution.get('out')
for cmap in root.iter('cmap'):
for maps in cmap.iter('map'):
if maps.get('name') in cid_replace_dic.keys():
maps.set('name', cid_replace_dic[maps.get('name')])
tree.write("output.xml")
$ python otfconv.py GenEiAntiqueN-Medium.ttx
うまくいけば、output.xmlが作成されるので、これをttxでOpenTypeファイルに戻してやります。
ちなみに自分がやったときは、以下の1行を先頭に追加しないと変換エラーになりました。(それでうまくいったので、あまり詳細を調べていません。。)
<?xml version="1.0" encoding="UTF-8"?>
ttxを使用して、xmlからotfに戻します。
$ ttx -o TateFont.otf output.xml
そうすると
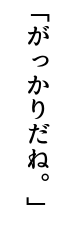
それっぽく書けました。
いくつかの必要な機能
小説体にするには、少なくともルビ、禁則処理が必要と考えました。あと、おまけで傍点。ルビは、ルビの文字高さがそれに対応する本文の文字高さを越える場合は、本文の字間を大きくしてやらなければならず、少々面倒です。

もう一つは、複数頁対応です。本文が1ページに収まらない場合は、同様のレイアウトで複数枚の画像を生成するようにします。
これで物語を書く準備が整いました。
さいごに
- ページ数の自動記入であるとか、横書きの段との混在などを対応したい。
- 結局のところ、面白い物語が思いつかない。