はじめに
以前 MySQLのマネージドサービスを探していたときに「PlanetScale」というサービスを知りました。どうやら単にMySQLを運用しているのではなく、可用性とスケーラビリティを実現したMySQL互換のNewSQLサービスだということを知りました。
そこで興味を持ったNewSQLについて、今回私の理解を整理してみました。間違っている箇所については指摘いただけると嬉しいです。
NewSQLとは
NewSQLはRDB(SQL)に対して台頭したNoSQL(キーバリューストアやドキュメント型DBなど)の限界に対する解決策といて登場したと捉えています。そのため最初にNoSQLの限界について整理した方が、その意義が分かりやすいでしょう。
NoSQLの限界
NoSQLはRDB(SQL)に比較して、高い可用性とスケールアウトによる巨大データとアクセス数の増大に対応することを可能にました。シンプルなデータアクセスにはとても高い性能を発揮します。
一方そのために割り切った(切り捨てた)側面が多く、使い方に工夫が必要となっています。
- 複雑なクエリーができない(SQLが使えない)
- データの一貫性がない(トランザクションが使えない)
NewSQLの登場
SQLが使える分散型データベースとしてNewSQLが登場します。
- 初期のNewSQL
- インメモリデータベースのクラスター
- SQLが使える
- VoltaDBなど(2011〜)
- Google Spanner 以降(2012〜)
- SQLが使える
- データの一貫性を保つ(ACIDトランザクションをサポート)
- ストレージへの書き込みも含めてスケールアウトできる
Google Spanner以降、さまざま実装が登場してます。
3つの比較
私の理解で比較表を作りました。
| SQL(RDB) | NewSQL | NoSQL | |
|---|---|---|---|
| 長所 | SQLによる複雑なクエリーが可能 トランザクションによる強い一貫性 |
可用性とスケーラビリティを確保 SQLサポート 一貫性あり |
可用性とスケーラビリティ |
| 短所 | 可用性の確保が難しい スケーラビリティの確保が難しい(特に書き込み) |
構成が複雑(高価になる傾向) トップスピードは他に劣る(※) |
複雑なクエリーができない 複雑な関連が持てない トランザクションがく一貫性が弱い |
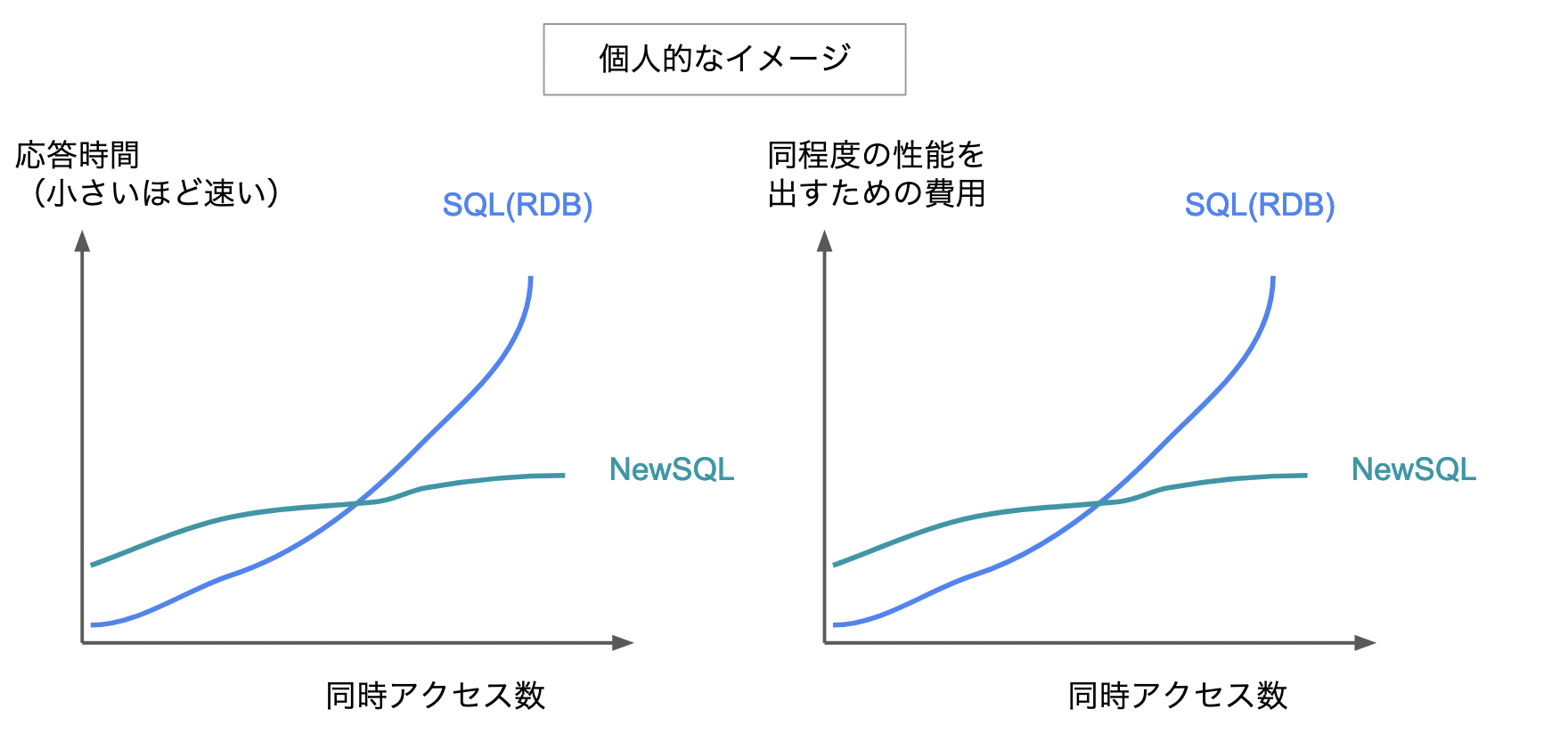
NewSQLの「トップスピードは他に劣る」については、次の理解です。
- 単純なデータの読み書きならNoSQLの方が速い
- 凝ったクエリーでも、同時アクセス数が少ない状況ならSQL(RDB)の方が速い
- 凝ったクエリかつ同時アクセス数が増えて負荷が高くなった状況ではNewSQLはパフォーマンスの低下が少ない
可用性、スケーラビリティ、データの一貫性を保つために、他の方式よりもノード数(サーバー数)が多く必要で、コストが高くなる傾向があると考えています。
CAP定理との対応
私の理解では、 次の対応と捉えています。
| SQL(RDB) | NewSQL | NoSQL | |
|---|---|---|---|
| 一貫性 (Consistency) | ◎ | ○ | × |
| 可用性 (Availability) | △ | ○ | ◎ |
| 断耐性 (Partition-tolerance) | ー | ◎ | ◎ |
NewSQLはCAPに対して欲張ったバランスを狙っています。
NewSQLの互換性
NewSQLには、既存のSQL(RDB)と互換性があるものと、独自のものがあります。
互換性があるものはSQLの方言や型が使えるケースが多いですが、ストアドプロシージャや一部の機能は使えないケースが多いようです。
- 独自
- VoltDB ... https://www.voltactivedata.com
- Google Spanner(※当初)
- NuoDB ... ダッソー・システムズが買収(2020)
- FoundationDB ... Appleが買収(2015)、その後オープンソース化(2018)
- PostgreSQL互換
- CockroachDB ... https://www.cockroachlabs.com
- YugabyteDB ... https://www.yugabyte.com
- Google AlloyDB
- Google Spanner PosgreSQl互換インターフェイス(2022)
- MySQL互換
- TiDB ... https://www.pingcap.com
- TiDB Cloud ... マネージドサービス
- Vitess ... https://vitess.io
- PlanetScale ... マネージドサービス
- Clustrix ... MariaDBが買収(2018)
- MemSQL ... SingleStoreに改名(2020)
- TiDB ... https://www.pingcap.com
NewSQLの仕組み
NewSQLが強い一貫性と、可用性&スケールアウトの良いとこ取りを実現しているには、次の仕組みが関与しています。
分散の仕組み
SQL(RDB)ではパフォーマンスを上げるためには、次の仕組みが用いられます。
- プライマリー(書き込み用)+ 複数のリードレプリカ(読み出し用)
- シャーディング ... データを主キーの範囲で複数のDBサーバーに分割
NewSQLではシャーディングの考え方は活かしたまま、書き込み時のプライマリーを分散させてLeader-Followerの形を取っています。
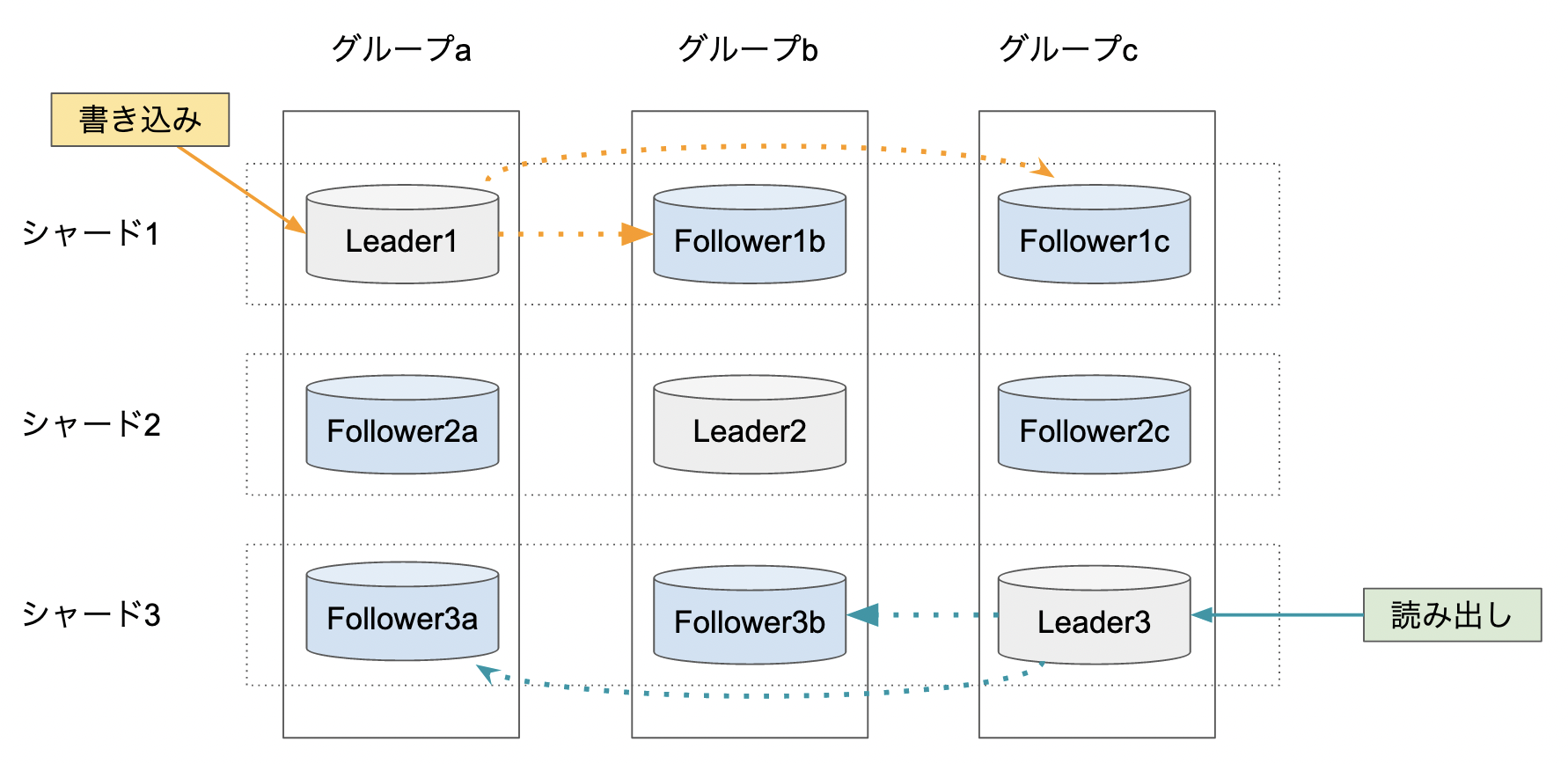
[書き込み時]
- シャードに応じたLeaderに書き込みをリクエストする
- Leaderは同じシャードのFollower全てに書き込みを指示する
- 過半数のFollowerから書き込みOKの応答があれば、Leader自身もコミットして応答を返す
- 書き込みOKのFollowerが過半数に満たなければ、Followerには取り消しの指示を伝え、自分自身も書き込みを取り消す
全てのFollowerに書き込みますが全ての応答を待たなくても良いのが、分散のオーバーヘッドを減らす効果を持っていると理解しています。
[読み出し時]
- シャードに応じたLeaderに読み出しをリクエストする
- Leaderは同じシャードのFollower全てに読み出し確認を行う
- 過半数のFollowerから読み出しの応答があり値が確認できれば、Leaderは値を返す
- 読み出し確認できたFollowerの数が過半数に満たなければ、Leaderは読み出しエラーを返す
[クオリア]
このような分散の仕組みはクオリアと呼ばれ、Followerの応答を待つ数は実装や設定によって必ずしも過半数ではないことがあります。
一般に次の関係が成り立つように実装/設定することで、値の整合性を保証します。
- n ... LeaderとFollowerの総数
- w ... 書き込み時に確認を取るLeaderとFollowerの合計
- r ... 読み出し時に確認を取るLeaderとFollowerの合計
- w + r > n になるようにw,rを選ぶ
ストレージエンジン
実際にデータを格納するストレージの構造も違いがあり、書き込みに強くなっています。
- B+Tree
- SQL(RDB)で長らく使われてきた構造。Readには強いがWriteの効率は良くない
- LSM-Tree
- 多くのNewSQLや分散ストレージで使われる構造
- Immutableで追記型。Writeの効率とSpace効率も良い
- Readには強くない
まとめ
書き込みが少なく、読み出しに偏っているシステムであれば、SQL(RDB)を中心として次の構成で対応可能です。
- RDB + キャッシュ
- RDBでプライマリー + 複数のリードレプリカの構成
一方書き込みも多いシステムでは、上記の構成では負荷に耐えきれないことがあります。NewSQLはそんなケースに対して有効な選択肢になりそうです。
参考資料
- logmi: Spannerの登場で急拡大したNewSQL 分散トランザクションの課題をどう解決したか
- 書籍: データ指向アプリケーションデザイン
- 5 レプリケーション
- Google Spanner のアーキテクチャを知る
- Podcast: fukabori.fm 34. NewSQLとは w/ tzkb
- Qiita: [論文まとめ] 「NewSQL」 の 「New」 の部分は一体何ですか
- Qiita: 2020年現在のNewSQLについて