これは2017年WebRTCアドベントカレンダーの22日目の記事です。
はじめに
WebRTCで映像配信をする際に、映像から自分の姿を消し去りたいというニーズがあります(私には)。特にTHETA Vなどの360度カメラの場合、どこに居ても自分が写り込んでしまいます。これを、居なかったことにしようというのが、今回の取り組みです。
厳密に言うと今回はP2P通信の手前までの話なので「WebRTCじゃない」とツッコミたくなると思いますが、そこはWebRTC通信を前提とした話として、多めに見ていただけるとありがたいです。
やりたいこと
基本的な流れ
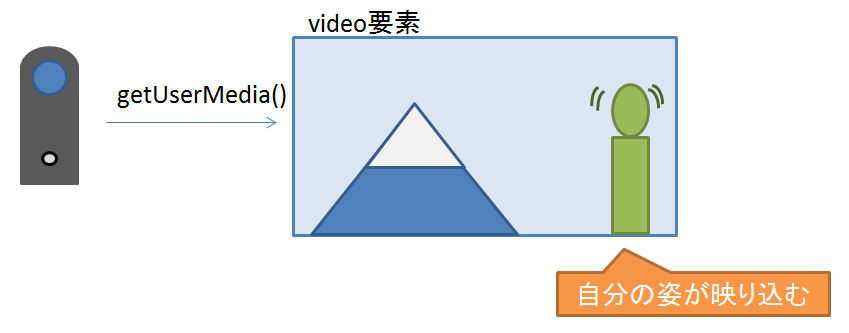
- (1) カメラ映像を取得、video要素に表示
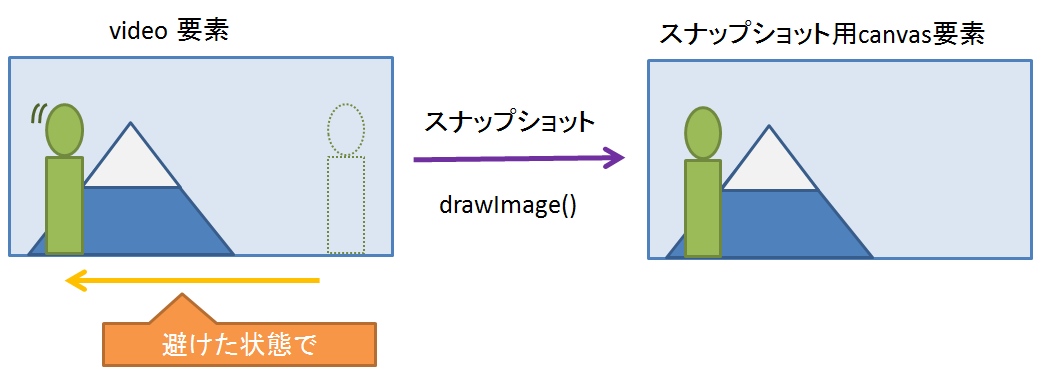
- (2) いったん横に避けた状態で、video要素からスナップショットを静止画として取得
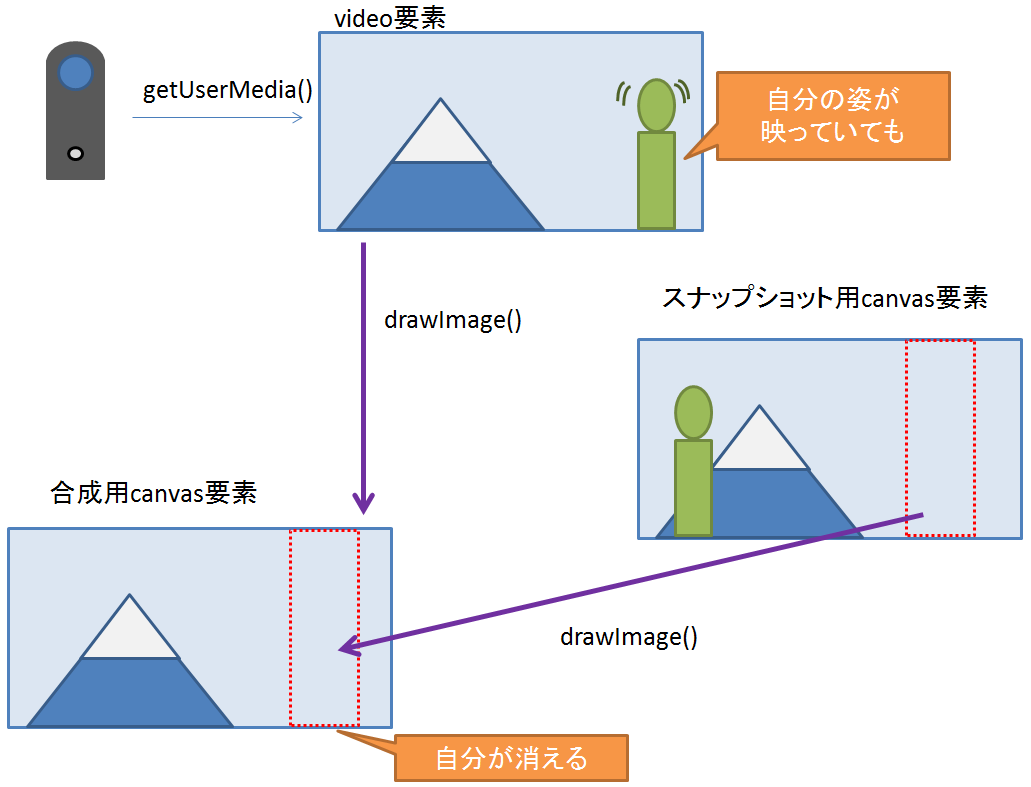
- (3) Canvasで合成
- Canvasに(1)の映像を転写
- そこに領域を指定して(2)の静止画の一部を合成し、自分の姿を消去
- アニメーションイベントで繰り返す
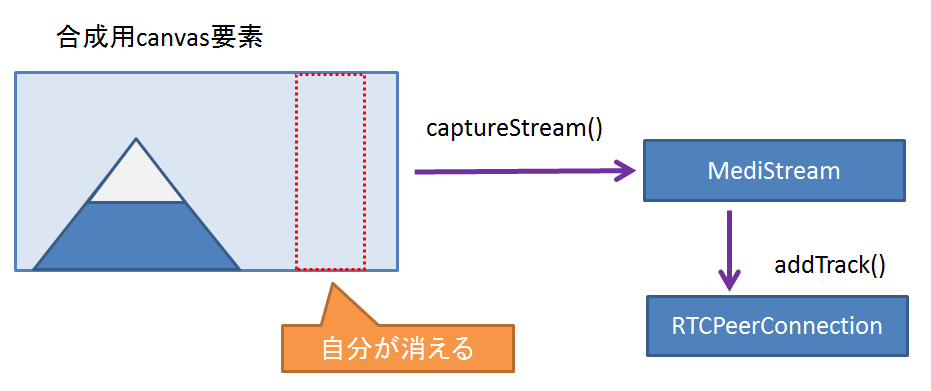
- (4) CanvasからMediaStreamを取得
- その後はRTCPeerConnectionで通信に使うことが可能
これを図にするとこんな感じです。
(1) カメラ映像を取得
(2) 避けてスナップショットを取得
(3) 合成して自分を消去
(4) MediaStream取得
顔検出による領域の自動判定
最終的には、Chrome で #enable-experimental-web-platform-features フラグを有効にすると使える、FaceDetector を使って自分の写っている領域を自動判定させてみたいと思います。
- (5) Canvas合成の領域を、顔検出を使って決定
図にするとこんな感じです。
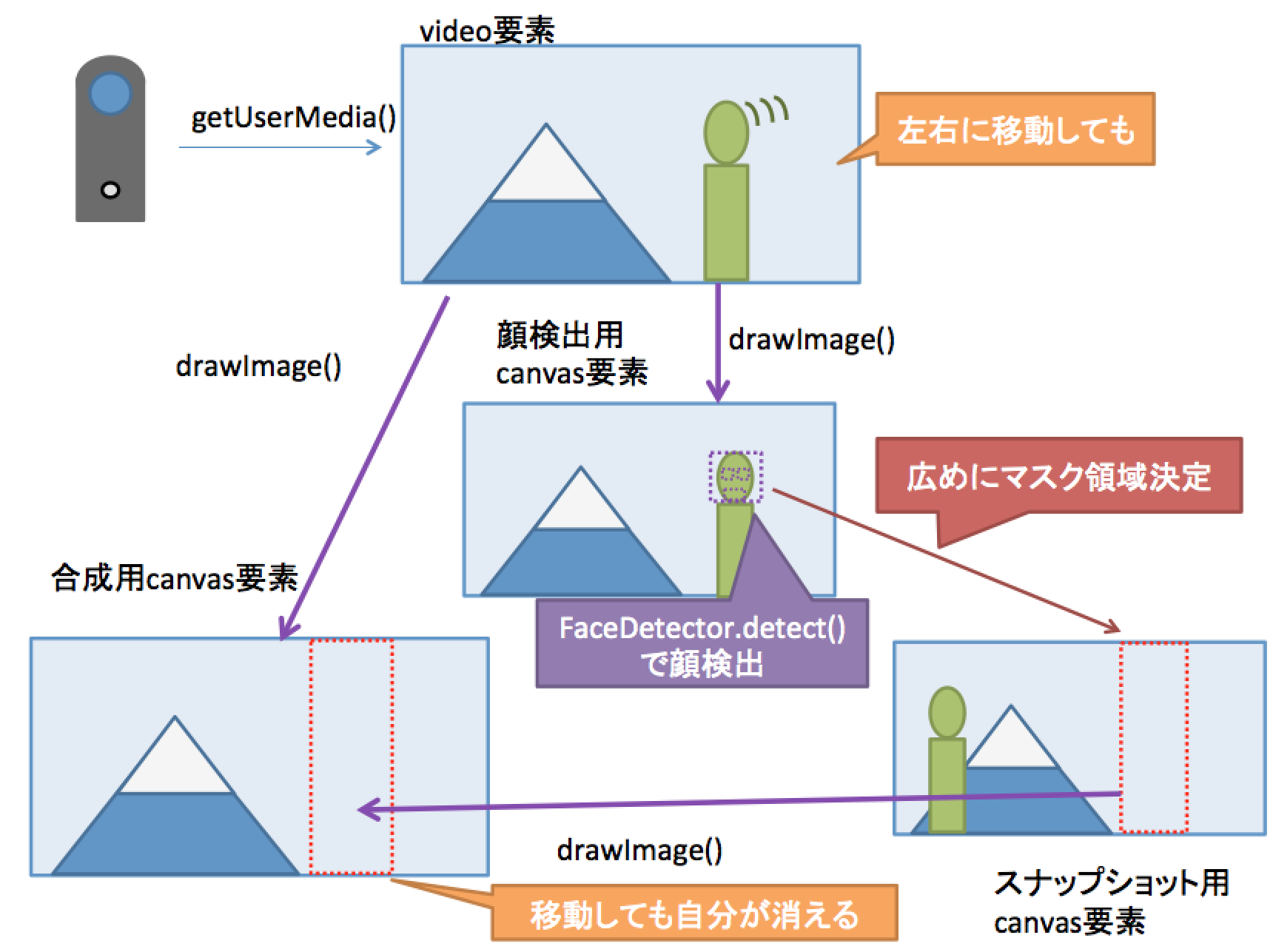
※Chrome 63 では、FaceDetector を使うためにはフラグを有効にする必要があります。
対応している360度映像の形式
360度カメラの映像の形状には、大きく2種類があります。
- Dual-Fisheye ... 魚眼映像x2個の形状。THETA S はこの形状
- Equirectangular ... パノラマ状の映像。THETA V はこの形状
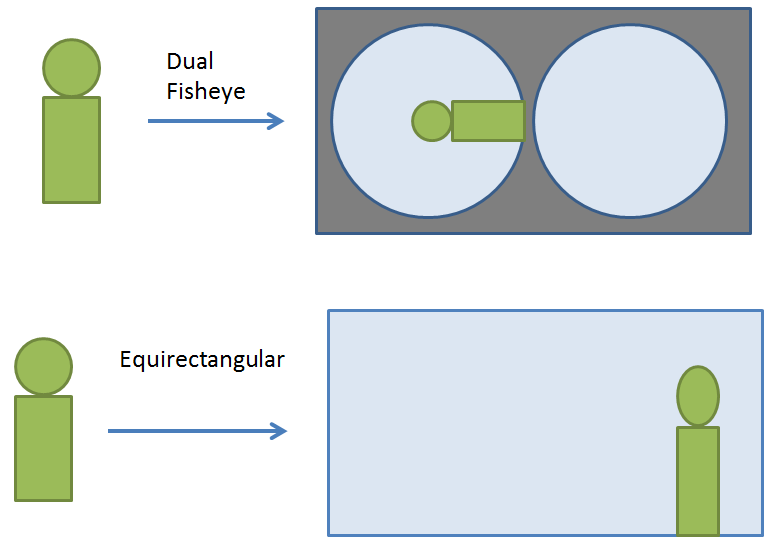
前者の場合は、形状の歪みが大きいので色々大変です。今回は合成形状と顔検出の容易さから、後者のみ対象としています(手抜き)。
もちろん、360度ではない通常のカメラの映像でも大丈夫です。
動かしている様子
動かしているところの画面のキャプチャーを撮ってみました。(GitHub Pagesでも公開しているので、ご自分でも試してみてください)
- GitHub pages で試す (Chrome 63, Firefox 57) ... 360 Mask
※ Firefoxでは顔検出は利用できません。
領域指定
上記の(1)~(3)の様子です。一番上がカメラから取得した映像、2番目がスナップショット、3番目が合成されたCanvasです。

- [Get Device]ボタンをクリック
- → カメラのリストが取得される(THETA Vが接続されていれば、自動で選択)
- 取得するカメラ、映像のサイズを選択
- [Start Video]ボタンをクリック
- カメラから映像が取得され、表示される
- [Take Snap]ボタンをクリック
- カウントダウンが始まるので、定常位置から避ける
- → 3,2,1,0でスナップショットが取得される
- Conver to Streamの[Start]ボタンをクリックする
- Canvasを使った映像合成が開始
- Canvas上でマスクしたい領域をマウスでドラッグ
- → ドラッグを終了すると、領域が決定
- マスクした領域が、先ほど取得したスナップショットでマスクされる
- 領域の中にいれば、自分は消える
- 領域かから外に出れば、姿が現れる
この例では「Mask inside area」を選んでいるので、指定した領域の内側がスナップショットでマスクされます。領域の中にいる限りは、自分の姿が消えます。領域から顔を出せば、当然表示されてしまいます。
「Mask outside area」を選んだ場合には、指定した領域の外側がマスクされます(内側だけ動画になる)
顔検出
上記(5)の場合の様子です。「use Face Detection」をチェックします。
カメラから取得した映像は見えていません。1番目がスナップショット、次が合成されたCanvas、一番下は顔検出用のCanvasです。

- [use Face Detection]をチェックする
- Conver to Streamの[Start]ボタンをクリックする
- 顔検出が始まり、検出された領域がマスクされる
- 斜めや横を向いたり、カメラから離れて顔が小さくなると検出できなくなる
※Chrome 63現在では、あらかじめ chrome://flags で "Experimental Web Platform features" を「有効」にしておく必要があります。
処理の紹介
一部を抜粋してご紹介します。全体のソースはこちらにあります。
- GitHubでソースを見る ... mask_face.html
- GitHub pages で試す (Chrome 63-) ... 360 Mask
(1) カメラ映像の取得
普通にgetUserMedia()で映像を取得しますが、今回は事前にvideoデバイスの一覧を取得し、選べるようにしてみました。
- mediaDevices.enumDevices() で、videoデバイスのリストを取得
- このときデバイス名が取得できるように、mediaDevices.getUserMedia()でユーザーの許可を得ておく
- デバイスリストにTHETA があったら、それを選択する
- mediaDevices.getUserMedia()で選択されたvideoデバイス、解像度で映像を取得
- videoElement.srcObject にセットして映像を再生
// -- enum device --
let videoSelect = document.getElementById('videoSource');
navigator.mediaDevices.getUserMedia({video: true, audio: true})
.then(stream => callBackDeviceList(stream))
.catch(err => console.error(err));
function callBackDeviceList(stream) {
navigator.mediaDevices.enumerateDevices()
.then(function(devices) {
devices.forEach(function(device) {
if (device.kind === 'videoinput') {
var id = device.deviceId;
var label = device.label || 'camera' + '(' + id + ')';
var option = document.createElement('option');
option.setAttribute('value', id);
option.innerHTML = label;
videoSelect.appendChild(option);
}
});
})
.catch(function(err) {
console.log(err.name + ": " + error.message);
});
stopLocalStream(stream);
}
function stopLocalStream(stream) {
let tracks = stream.getTracks();
for (let track of tracks) {
track.stop();
}
}
// 映像取得
let options = getMediaOptions();
navigator.mediaDevices.getUserMedia(option)
.then(/*-- 省略 --*/)
.catch(/*-- 省略 --*/);
function getMediaOptions() {
let options = { video: true, audio: false};
// -- 解像度 ---
const sizeString = cameraSizeSelect.options[cameraSizeSelect.selectedIndex].value;
if (sizeString === 'VGA') {
options.video = { width: { min: 640, max: 640}, height: { min: 480, max: 480 } };
}
// ... 省略 ...
else if (sizeString === 'THETA-V-FHD') {
options.video = { width: { min: 1920, max: 1920}, height: { min: 960, max: 960 } };
}
// --- videoデバイス ---
const videoSource = videoSelect.value;
if (videoSource) {
options.video.deviceId = {exact: videoSource};
}
return options;
}
(2) video要素スナップショットを取得
メディアストリームを表示中のvideo要素から、CanvasにdrawImage()を使って転写します。
let ctx = shapshotCanvas.getContext('2d');
drawVideToCanvas(video, shapshotCanvas, ctx);
// --- canvasに映像を描画 ---
function drawVideoToCanvas(video, canvas, ctx) {
const srcLeft = 0;
const srcTop = 0;
const srcWidth = video.videoWidth;
const srcHeight = video.videoHeight;
const destCanvasLeft = 0;
const destCanvasTop = 0;
const destCanvasWidth = canvas.width;
const destCanvasHeight = canvas.height;
ctx.drawImage(video, srcLeft, srcTop, srcWidth, srcHeight,
destCanvasLeft, destCanvasTop, destCanvasWidth , destCanvasHeight
);
}
実際のコードでは、スナップショットを取るまでに自分が程よい位置に移動できるように、タイマーを仕掛けるようにしています。
(3) Canvasを使って、カメラの映像と静止画を合成
準備ができたら、映像と先ほどのスナップショットを合成して、自分の姿を消し去ります。
- もう一つCanvasを用意して、drawImage()を使ってカメラ映像を転写
- その上に、領域を指定してスナップショットを保持したCanvasから静止画を転写
- 領域はマウスのドラッグで指定。左右のみ指定し、上下はぶち抜きに
- requestAnimationFrame()を使って、継続的に描画を繰り返す
おまけとして、2種類の合成を選べるようにしてみました。
- 選択した領域の内側に静止画を転写 ... 自分を消す
- 選択した領域の外側に静止画を転写 ... 自分以外を消す
もしかしたら後者の方が使いたい場面が多いかもしれません。
let ctxDuplicate = duplicateCanvas.getContext('2d');
// --- マスクする領域を保持する変数。マウス操作で決定される --
let maskSrcLeft, maskSrcTop, maskSrcWidth, maskSrcHeight,
maskDestLeft, maskDestTop, maskDestWidth , maskDestHeight;
function drawCanvas() {
// --- draw video ---
drawVideoToDuplicateCanvas();
// --- mask with snapshot --
drawMaskToCanvas();
// --- draw drag area --
drawDragArea();
// --- keep animation ---
animationId = window.requestAnimationFrame(drawCanvas);
}
// --- カメラ映像を描画 ---
function drawVideoToDuplicateCanvas() {
drawVideoToCanvas(localVideo, duplicateCanvas, ctxDuplicate);
}
// --- 静止画でマスク ---
function drawMaskToCanvas() {
if (maskOutsideRadio.checked) {
drawMaskOutsideToCanvas();
}
else {
drawMaskInsideToCanvas();
}
}
// -- 選択領域の内側をマスク --
function drawMaskInsideToCanvas() {
if ( (maskSrcWidth < 1) || (maskDestWidth < 1) ) {
return;
}
ctxDuplicate.drawImage(snapshotCanvas, maskSrcLeft, maskSrcTop, maskSrcWidth, maskSrcHeight,
maskDestLeft, maskDestTop, maskDestWidth , maskDestHeight
);
}
// --選択領域の外側をマスク --
function drawMaskOutsideToCanvas() {
const maskSrcLeft1 = 0;
const maskSrcWidth1 = maskSrcLeft;
const maskDestLeft1 = 0;
const maskDestWidth1 = maskDestLeft;
ctxDuplicate.drawImage(snapshotCanvas, maskSrcLeft1, maskSrcTop, maskSrcWidth1, maskSrcHeight,
maskDestLeft1, maskDestTop, maskDestWidth1 , maskDestHeight
);
const maskSrcLeft2 = maskSrcLeft + maskSrcWidth;
const maskSrcWidth2 = snapshotCanvas.width - maskSrcLeft2;
const maskDestLeft2 = maskDestLeft + maskDestWidth;
const maskDestWidth2 = duplicateCanvas.width - maskDestLeft2;
ctxDuplicate.drawImage(snapshotCanvas, maskSrcLeft2, maskSrcTop, maskSrcWidth2, maskSrcHeight,
maskDestLeft2, maskDestTop, maskDestWidth2 , maskDestHeight
);
}
(4) CanvasからMediaStreamを取得
シンプルに、captureStream()を使ってメディアストリームを取得します。
let duplicateStream = duplicateCanvas.captureStream(30);
あとはこのストリームをRTCPeerConnectionに渡してやれば、通信することができます。
FaceDetectorによる顔検出
前準備
もう少し前から使えたようですが、Chrome 63ではフラグを指定することで FaceDetector を使うことができます。
- chrome://flags にアクセス
- "Experimental Web Platform features" を「有効」に
- Chromeを再起動

FaceDetector とは
FaceDetector は W3Cの Web Platform Incubator Community Group で Shape Detection API として提案されている仕様の一部です。
- Accelerated Shape Detection in Images (Editor’s Draft, 21 October 2017)
- 紹介記事 Face detection using Shape Detection API
こちらは標準化されたものでも、標準化の手続きに乗っかっているものでもありません。Chrome以外では全く実装は行われていないようです。
FaceDetectorを使うと、顔の輪郭の矩形と、ランドマーク(目、口)の座標を取得することができます。仕様をみると、1つだけでなく複数の顔の位置を取得できるようです。
※あくまで顔の領域を検出するのが目的で、特定の個人を識別することはできません。
ちなみに Shape Detection APIには、他にバーコードを読み取る BarcodeDetector があります。
FaceDetectorの使い方
- FaceDetector のインスタンスを生成
- detect()に img/video/canvas/blob を渡す
- 検出結果は Promise で返される
- 動画から検出する場合は、一定間隔で繰り返す
今回はこんな感じで使っています。videoから顔検出用に別のCanvasに転写して、そこから検出するようにしています。
let faceDetector = new FaceDetector();
let ctxFace = faceCanvas.getContext('2d');
setInterval(detectFace, 500);
function detectFace() {
drawVideoToCanvas(localVideo, faceCanvas, ctxFace);
faceDetector.detect(faceCanvas) // detect from canvas
.then(faces => {
if (faces.length > 0) {
let face = faces[0];
const top = 0; // 顔より上もマスクする
const left = face.boundingBox.x - 20; // 左右は少し広げる
const width = face.boundingBox.width + 20*2; // 左右は少し広げる
const height = faceCanvas.height; // 顔より下もマスクする
// --- 領域の矩形を描画 ---
drawRectFace(ctxFace, left, top, width, height); // draw for canvas
// --- 領域を覚える処理 ---
setMaskAreaFromFace(left, top, width, height);
}
else {
// --- 顔が見つからない場合 ---
}
})
.catch(e => {
console.error("Face Detection failed: " + e);
});
}
FaceDetectorは基本的に正面を向いた顔を検出するようです。大きく斜めを向いたり、横顔になると検出はできません。また、あまり距離が遠く小さい顔は検出できません。
通常のWebカメラでは十分な顔の大きなになりますが、THETA Vのような360度カメラや、超広角のカメラでは顔が小さくなりやすいので、注意が必要です。
(5) FaceDetectorを使って、自分の姿を消してみる
やっていることは、マスク領域をマウスでドラッグして指定した場合と同じです。まず、検出した領域をマスク領域として覚えます。
function setMaskAreaFromFace(left, top, width, height) {
maskDestLeft = Math.floor(left * (duplicateCanvas.width / faceCanvas.width));
maskDestTop = 0;
maskDestWidth = Math.floor(width * (duplicateCanvas.width / faceCanvas.width));
maskDestHeight = duplicateCanvas.height;
maskSrcLeft = Math.floor(maskDestLeft * (snapshotCanvas.width / duplicateCanvas.width));
maskSrctTop = 0;
maskSrcWidth = Math.floor(maskDestWidth * (snapshotCanvas.width / duplicateCanvas.width));
maskSrcHeight = snapshotCanvas.height;
}
合成する処理は、(3)と同じです。
- drawImage()を使ってカメラ映像を転写
- その上に、領域を指定してスナップショットを保持したCanvasから静止画を転写
- 領域は顔検出を使って指定。左右は余裕をもたせて指定し、上下はぶち抜きに
- requestAnimationFrame()を使って、継続的に描画を繰り返す
同様に、領域の内側をマスクしたり、外側をマスクすることもできるようにしています。
おわりに
Canvasを使って動画と静止画を合成することで、擬似的に自分の姿を消してみました。これをMediaStreamとして取得し、WebRTCを使った通信に利用することができます。
また、試験的な試みですがブラウザで顔検出も利用することができるようになりました。将来的には機械学習を使った物体識別などもブラウザだけでできるようになると面白いな、と期待してしまします。