テーブルデータの機械学習モデルとして注目されている TabNet なるものを、私も使ってみようとしました。まずは「回帰編」としてお届けします。
TabNet インストール
!pip install git+https://github.com/dreamquark-ai/tabnet
「ワインの品質」データ読み込み
データは UC Irvine Machine Learning Repository から取得したものを少し改変しました。
-
赤ワイン https://raw.githubusercontent.com/chemo-wakate/tutorial-6th/master/beginner/data/winequality-red.txt
- fixed acidity : 不揮発酸濃度(ほぼ酒石酸濃度)
- volatile acidity : 揮発酸濃度(ほぼ酢酸濃度)
- citric acid : クエン酸濃度
- residual sugar : 残存糖濃度
- chlorides : 塩化物濃度
- free sulfur dioxide : 遊離亜硫酸濃度
- total sulfur dioxide : 亜硫酸濃度
- density : 密度
- pH : pH
- sulphates : 硫酸塩濃度
- alcohol : アルコール度数
- quality (score between 0 and 10) : 0-10 の値で示される品質のスコア
import pandas as pd
red_wine = pd.read_csv('https://raw.githubusercontent.com/chemo-wakate/tutorial-6th/master/beginner/data/winequality-red.txt', sep='\t', index_col=0)
red_wine
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.700 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.99780 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.880 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.99680 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.760 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.99700 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.280 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.99800 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.700 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.99780 | 3.51 | 0.56 | 9.4 | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1594 | 6.2 | 0.600 | 0.08 | 2.0 | 0.090 | 32.0 | 44.0 | 0.99490 | 3.45 | 0.58 | 10.5 | 5 |
| 1595 | 5.9 | 0.550 | 0.10 | 2.2 | 0.062 | 39.0 | 51.0 | 0.99512 | 3.52 | 0.76 | 11.2 | 6 |
| 1596 | 6.3 | 0.510 | 0.13 | 2.3 | 0.076 | 29.0 | 40.0 | 0.99574 | 3.42 | 0.75 | 11.0 | 6 |
| 1597 | 5.9 | 0.645 | 0.12 | 2.0 | 0.075 | 32.0 | 44.0 | 0.99547 | 3.57 | 0.71 | 10.2 | 5 |
| 1598 | 6.0 | 0.310 | 0.47 | 3.6 | 0.067 | 18.0 | 42.0 | 0.99549 | 3.39 | 0.66 | 11.0 | 6 |
1599 rows × 12 columns
import pandas as pd
white_wine = pd.read_csv('https://raw.githubusercontent.com/chemo-wakate/tutorial-6th/master/beginner/data/winequality-white.txt', sep='\t', index_col=0)
white_wine
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.0 | 0.27 | 0.36 | 20.7 | 0.045 | 45.0 | 170.0 | 1.00100 | 3.00 | 0.45 | 8.8 | 6 |
| 1 | 6.3 | 0.30 | 0.34 | 1.6 | 0.049 | 14.0 | 132.0 | 0.99400 | 3.30 | 0.49 | 9.5 | 6 |
| 2 | 8.1 | 0.28 | 0.40 | 6.9 | 0.050 | 30.0 | 97.0 | 0.99510 | 3.26 | 0.44 | 10.1 | 6 |
| 3 | 7.2 | 0.23 | 0.32 | 8.5 | 0.058 | 47.0 | 186.0 | 0.99560 | 3.19 | 0.40 | 9.9 | 6 |
| 4 | 7.2 | 0.23 | 0.32 | 8.5 | 0.058 | 47.0 | 186.0 | 0.99560 | 3.19 | 0.40 | 9.9 | 6 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4893 | 6.2 | 0.21 | 0.29 | 1.6 | 0.039 | 24.0 | 92.0 | 0.99114 | 3.27 | 0.50 | 11.2 | 6 |
| 4894 | 6.6 | 0.32 | 0.36 | 8.0 | 0.047 | 57.0 | 168.0 | 0.99490 | 3.15 | 0.46 | 9.6 | 5 |
| 4895 | 6.5 | 0.24 | 0.19 | 1.2 | 0.041 | 30.0 | 111.0 | 0.99254 | 2.99 | 0.46 | 9.4 | 6 |
| 4896 | 5.5 | 0.29 | 0.30 | 1.1 | 0.022 | 20.0 | 110.0 | 0.98869 | 3.34 | 0.38 | 12.8 | 7 |
| 4897 | 6.0 | 0.21 | 0.38 | 0.8 | 0.020 | 22.0 | 98.0 | 0.98941 | 3.26 | 0.32 | 11.8 | 6 |
4898 rows × 12 columns
from sklearn.model_selection import train_test_split
random_state = 0
X_train, X_test, y_train, y_test = train_test_split(red_wine.iloc[:, :-1].values, red_wine.iloc[:, [-1]].values, test_size=.3, random_state=random_state)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=.3, random_state=random_state)
X_train.shape, y_train.shape
((783, 11), (783, 1))
X_valid.shape, y_valid.shape
((336, 11), (336, 1))
X_test.shape, y_test.shape
((480, 11), (480, 1))
以上のように、赤ワインのデータと白ワインのデータがありますが、赤ワインの品質を回帰モデルで予測してみようと思います。このデータを用いるのが適切ではない可能性もありますが、まあそれはおいといて。白ワインのデータは、下記にあるように「事前学習」に使ってみます。
事前学習なしでTabNet学習
まずは事前学習なしで、赤ワインのデータのみを用いて回帰モデルを作って性能を見てみます。n_steps という変数は、ニューラルネットワークにおける層の数みたいなもので、どの特徴量を使ってdecision makingをしたかを表すものだと理解しています(この理解が間違ってたらすみません)。n_stepを変えると挙動がだいぶ変わります。
import torch
from pytorch_tabnet.tab_model import TabNetRegressor
# from pytorch_tabnet.tab_model import TabNetClassifier
SEED = 53
N_STEPS = 3
tabnet_params = dict(n_d=8, n_a=8, n_steps=N_STEPS, gamma=1.3,
n_independent=2, n_shared=2,
seed=SEED, lambda_sparse=1e-3,
optimizer_fn=torch.optim.Adam,
optimizer_params=dict(lr=2e-2),
mask_type="entmax",
scheduler_params=dict(mode="min",
patience=5,
min_lr=1e-5,
factor=0.9,),
scheduler_fn=torch.optim.lr_scheduler.ReduceLROnPlateau,
verbose=10
)
model = TabNetRegressor(**tabnet_params)
# model = TabNetClassifier()
model.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
max_epochs=5000,
patience=100,
eval_metric={'rmse'} # 'rmsle', 'mse', 'mae'
# from_unsupervised=pretrainer
)
Device used : cuda
epoch 0 | loss: 32.64989| val_0_rmse: 11.13777| 0:00:00s
epoch 10 | loss: 4.0107 | val_0_rmse: 9.12493 | 0:00:00s
epoch 20 | loss: 0.82725 | val_0_rmse: 2.45153 | 0:00:01s
epoch 30 | loss: 0.53165 | val_0_rmse: 7.55144 | 0:00:02s
epoch 40 | loss: 0.44194 | val_0_rmse: 5.80592 | 0:00:02s
epoch 50 | loss: 0.40315 | val_0_rmse: 4.01958 | 0:00:03s
epoch 60 | loss: 0.39364 | val_0_rmse: 3.2229 | 0:00:04s
epoch 70 | loss: 0.35804 | val_0_rmse: 3.16619 | 0:00:04s
epoch 80 | loss: 0.37049 | val_0_rmse: 2.94055 | 0:00:05s
epoch 90 | loss: 0.32763 | val_0_rmse: 2.65781 | 0:00:06s
epoch 100| loss: 0.33686 | val_0_rmse: 2.25962 | 0:00:07s
epoch 110| loss: 0.33178 | val_0_rmse: 2.03964 | 0:00:07s
epoch 120| loss: 0.3237 | val_0_rmse: 1.88684 | 0:00:08s
epoch 130| loss: 0.29202 | val_0_rmse: 1.67104 | 0:00:09s
epoch 140| loss: 0.3079 | val_0_rmse: 1.55122 | 0:00:10s
epoch 150| loss: 0.29544 | val_0_rmse: 1.39493 | 0:00:10s
epoch 160| loss: 0.28853 | val_0_rmse: 1.25286 | 0:00:11s
epoch 170| loss: 0.29431 | val_0_rmse: 1.19063 | 0:00:12s
epoch 180| loss: 0.27545 | val_0_rmse: 1.15625 | 0:00:13s
epoch 190| loss: 0.28683 | val_0_rmse: 1.09202 | 0:00:13s
epoch 200| loss: 0.27095 | val_0_rmse: 0.99627 | 0:00:14s
epoch 210| loss: 0.28285 | val_0_rmse: 0.96371 | 0:00:15s
epoch 220| loss: 0.26719 | val_0_rmse: 0.90612 | 0:00:16s
epoch 230| loss: 0.27271 | val_0_rmse: 0.88299 | 0:00:16s
epoch 240| loss: 0.2663 | val_0_rmse: 0.82608 | 0:00:17s
epoch 250| loss: 0.25915 | val_0_rmse: 0.82236 | 0:00:18s
epoch 260| loss: 0.24917 | val_0_rmse: 0.80364 | 0:00:19s
epoch 270| loss: 0.25684 | val_0_rmse: 0.77136 | 0:00:19s
epoch 280| loss: 0.24275 | val_0_rmse: 0.78264 | 0:00:20s
epoch 290| loss: 0.23762 | val_0_rmse: 0.77993 | 0:00:21s
epoch 300| loss: 0.26254 | val_0_rmse: 0.77074 | 0:00:21s
epoch 310| loss: 0.25207 | val_0_rmse: 0.76689 | 0:00:22s
epoch 320| loss: 0.23648 | val_0_rmse: 0.74517 | 0:00:23s
epoch 330| loss: 0.25361 | val_0_rmse: 0.73926 | 0:00:23s
epoch 340| loss: 0.24606 | val_0_rmse: 0.72841 | 0:00:24s
epoch 350| loss: 0.24784 | val_0_rmse: 0.72501 | 0:00:25s
epoch 360| loss: 0.23659 | val_0_rmse: 0.71072 | 0:00:26s
epoch 370| loss: 0.24355 | val_0_rmse: 0.71563 | 0:00:26s
epoch 380| loss: 0.23749 | val_0_rmse: 0.7265 | 0:00:27s
epoch 390| loss: 0.22572 | val_0_rmse: 0.71044 | 0:00:28s
epoch 400| loss: 0.22856 | val_0_rmse: 0.7037 | 0:00:28s
epoch 410| loss: 0.22577 | val_0_rmse: 0.70413 | 0:00:29s
epoch 420| loss: 0.26083 | val_0_rmse: 0.70473 | 0:00:30s
epoch 430| loss: 0.2384 | val_0_rmse: 0.70011 | 0:00:31s
epoch 440| loss: 0.23224 | val_0_rmse: 0.70506 | 0:00:31s
epoch 450| loss: 0.23907 | val_0_rmse: 0.70495 | 0:00:32s
epoch 460| loss: 0.24532 | val_0_rmse: 0.70434 | 0:00:33s
epoch 470| loss: 0.24456 | val_0_rmse: 0.70559 | 0:00:33s
epoch 480| loss: 0.22083 | val_0_rmse: 0.70538 | 0:00:34s
epoch 490| loss: 0.2365 | val_0_rmse: 0.70484 | 0:00:35s
epoch 500| loss: 0.24641 | val_0_rmse: 0.70772 | 0:00:35s
epoch 510| loss: 0.22065 | val_0_rmse: 0.70898 | 0:00:36s
epoch 520| loss: 0.22796 | val_0_rmse: 0.70955 | 0:00:37s
epoch 530| loss: 0.21979 | val_0_rmse: 0.711 | 0:00:37s
Early stopping occurred at epoch 530 with best_epoch = 430 and best_val_0_rmse = 0.70011
Best weights from best epoch are automatically used!
学習が終わったようなので学習の経過を確認しましょう。
import matplotlib.pyplot as plt
for param in ['loss', 'lr', 'val_0_rmse']:
plt.plot(model.history[param], label=param)
plt.xlabel('epoch')
plt.grid()
plt.legend()
plt.show()



性能評価
from sklearn.metrics import mean_squared_error
test_score = mean_squared_error(model.predict(X_test), y_test)
print(f"BEST VALID SCORE: {model.best_cost}")
print(f"FINAL TEST SCORE: {test_score}")
BEST VALID SCORE: 0.7001122835576945
FINAL TEST SCORE: 0.5577702945336053
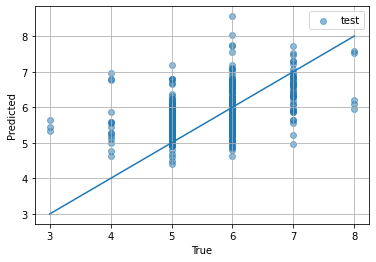
予測結果と真の値とを比較するプロット。今回はワインの品質として整数値を与えるのが本当なので、プロットの形もこんなのになります。
for name, X, y in [["training", X_train, y_train], ["validation", X_valid, y_valid], ["test", X_test, y_test]]:
plt.scatter(y, model.predict(X), alpha=0.5, label=name)
plt.plot([3, 8], [3, 8])
plt.grid()
plt.legend()
plt.xlabel("True")
plt.ylabel("Predicted")
plt.show()


自己事前学習ありでTabNet学習
TabNetでは次のようにして「事前学習」を行なえます。果たしてこれで性能が向上するでしょうか?
from pytorch_tabnet.pretraining import TabNetPretrainer
pretrainer = TabNetPretrainer(**tabnet_params)
pretrainer.fit(
X_train,
eval_set=[X_valid],
max_epochs=5000,
patience=100,
)
Device used : cuda
epoch 0 | loss: 84416.57031| val_0_unsup_loss: 33251194.0| 0:00:00s
epoch 10 | loss: 2395.65454| val_0_unsup_loss: 19814.19141| 0:00:01s
epoch 20 | loss: 301.95297| val_0_unsup_loss: 5600.98291| 0:00:01s
epoch 30 | loss: 153.68903| val_0_unsup_loss: 3039.54907| 0:00:02s
epoch 40 | loss: 51.07078| val_0_unsup_loss: 736.71814| 0:00:03s
epoch 50 | loss: 69.6201 | val_0_unsup_loss: 442.73096| 0:00:04s
epoch 60 | loss: 34.41461| val_0_unsup_loss: 233.06084| 0:00:05s
epoch 70 | loss: 47.174 | val_0_unsup_loss: 247.93704| 0:00:06s
epoch 80 | loss: 28.79832| val_0_unsup_loss: 293.99844| 0:00:07s
epoch 90 | loss: 37.22774| val_0_unsup_loss: 248.3813| 0:00:07s
epoch 100| loss: 22.29504| val_0_unsup_loss: 187.73672| 0:00:08s
epoch 110| loss: 22.49255| val_0_unsup_loss: 158.42435| 0:00:09s
epoch 120| loss: 14.54969| val_0_unsup_loss: 144.55991| 0:00:10s
epoch 130| loss: 12.70208| val_0_unsup_loss: 104.17162| 0:00:11s
epoch 140| loss: 12.65242| val_0_unsup_loss: 94.375 | 0:00:12s
epoch 150| loss: 7.38195 | val_0_unsup_loss: 101.70587| 0:00:13s
epoch 160| loss: 9.93811 | val_0_unsup_loss: 71.79494| 0:00:13s
epoch 170| loss: 14.58065| val_0_unsup_loss: 41.21515| 0:00:14s
epoch 180| loss: 12.00856| val_0_unsup_loss: 38.96758| 0:00:15s
epoch 190| loss: 15.64681| val_0_unsup_loss: 27.69069| 0:00:16s
epoch 200| loss: 5.2482 | val_0_unsup_loss: 23.3637 | 0:00:17s
epoch 210| loss: 19.1653 | val_0_unsup_loss: 27.76682| 0:00:18s
epoch 220| loss: 6.18701 | val_0_unsup_loss: 18.53819| 0:00:18s
epoch 230| loss: 4.77499 | val_0_unsup_loss: 19.45325| 0:00:19s
epoch 240| loss: 6.98359 | val_0_unsup_loss: 18.99881| 0:00:20s
epoch 250| loss: 21.51803| val_0_unsup_loss: 33.55697| 0:00:21s
epoch 260| loss: 5.4652 | val_0_unsup_loss: 11.66067| 0:00:22s
epoch 270| loss: 7.04799 | val_0_unsup_loss: 13.46543| 0:00:23s
epoch 280| loss: 4.69859 | val_0_unsup_loss: 13.60153| 0:00:23s
epoch 290| loss: 4.7595 | val_0_unsup_loss: 12.37127| 0:00:24s
epoch 300| loss: 5.02166 | val_0_unsup_loss: 13.52421| 0:00:25s
epoch 310| loss: 3.72067 | val_0_unsup_loss: 15.02659| 0:00:26s
epoch 320| loss: 3.20332 | val_0_unsup_loss: 14.02866| 0:00:27s
epoch 330| loss: 3.21631 | val_0_unsup_loss: 14.31985| 0:00:27s
epoch 340| loss: 3.85526 | val_0_unsup_loss: 15.13815| 0:00:28s
epoch 350| loss: 3.31001 | val_0_unsup_loss: 13.70876| 0:00:29s
epoch 360| loss: 3.56261 | val_0_unsup_loss: 13.16991| 0:00:30s
epoch 370| loss: 3.35176 | val_0_unsup_loss: 14.11328| 0:00:31s
epoch 380| loss: 2.76765 | val_0_unsup_loss: 13.73672| 0:00:31s
Early stopping occurred at epoch 382 with best_epoch = 282 and best_val_0_unsup_loss = 10.97403
Best weights from best epoch are automatically used!
事前学習の学習履歴を表示します。
import matplotlib.pyplot as plt
for param in ['loss', 'lr', 'val_0_unsup_loss']:
plt.plot(pretrainer.history[param])
plt.xlabel('epoch')
plt.ylabel(param)
plt.grid()
plt.show()



事前学習した結果を from_unsupervised=pretrainer として利用して学習します。
import torch
from pytorch_tabnet.tab_model import TabNetRegressor
# from pytorch_tabnet.tab_model import TabNetClassifier
model = TabNetRegressor(**tabnet_params)
# model = TabNetClassifier()
model.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
max_epochs=5000,
patience=100,
eval_metric={'rmse'}, # 'rmsle', 'mse', 'mae'
from_unsupervised=pretrainer
)
Device used : cuda
Loading weights from unsupervised pretraining
epoch 0 | loss: 44.76851| val_0_rmse: 6.73764 | 0:00:00s
epoch 10 | loss: 7.06438 | val_0_rmse: 1.96124 | 0:00:00s
epoch 20 | loss: 1.31673 | val_0_rmse: 2.24009 | 0:00:01s
epoch 30 | loss: 0.59232 | val_0_rmse: 0.97692 | 0:00:02s
epoch 40 | loss: 0.49472 | val_0_rmse: 0.78751 | 0:00:03s
epoch 50 | loss: 0.43891 | val_0_rmse: 0.93067 | 0:00:03s
epoch 60 | loss: 0.40727 | val_0_rmse: 0.88366 | 0:00:04s
epoch 70 | loss: 0.40231 | val_0_rmse: 0.83118 | 0:00:05s
epoch 80 | loss: 0.39851 | val_0_rmse: 0.81392 | 0:00:05s
epoch 90 | loss: 0.37589 | val_0_rmse: 0.7614 | 0:00:06s
epoch 100| loss: 0.37226 | val_0_rmse: 0.74418 | 0:00:07s
epoch 110| loss: 0.36799 | val_0_rmse: 0.74657 | 0:00:08s
epoch 120| loss: 0.3517 | val_0_rmse: 0.71815 | 0:00:08s
epoch 130| loss: 0.34294 | val_0_rmse: 0.70896 | 0:00:09s
epoch 140| loss: 0.3428 | val_0_rmse: 0.69662 | 0:00:10s
epoch 150| loss: 0.33453 | val_0_rmse: 0.69915 | 0:00:11s
epoch 160| loss: 0.33938 | val_0_rmse: 0.70477 | 0:00:11s
epoch 170| loss: 0.32963 | val_0_rmse: 0.71207 | 0:00:12s
epoch 180| loss: 0.33767 | val_0_rmse: 0.71087 | 0:00:13s
epoch 190| loss: 0.33722 | val_0_rmse: 0.70626 | 0:00:13s
epoch 200| loss: 0.33723 | val_0_rmse: 0.70464 | 0:00:14s
epoch 210| loss: 0.32091 | val_0_rmse: 0.70531 | 0:00:15s
epoch 220| loss: 0.30413 | val_0_rmse: 0.7041 | 0:00:15s
epoch 230| loss: 0.30876 | val_0_rmse: 0.70894 | 0:00:16s
Early stopping occurred at epoch 239 with best_epoch = 139 and best_val_0_rmse = 0.69576
Best weights from best epoch are automatically used!
その結果。
import matplotlib.pyplot as plt
for param in ['loss', 'lr', 'val_0_rmse']:
plt.plot(model.history[param], label=param)
plt.xlabel('epoch')
plt.grid()
plt.legend()
plt.show()



性能は向上したでしょうか。
from sklearn.metrics import mean_squared_error
test_score = mean_squared_error(model.predict(X_test), y_test)
print(f"BEST VALID SCORE: {model.best_cost}")
print(f"FINAL TEST SCORE: {test_score}")
BEST VALID SCORE: 0.6957614248635677
FINAL TEST SCORE: 0.4984989548147685
「今回は」性能が向上したようです。私の少ない経験上、train_test_split による分割が変化しても、random seed が変化しても、n_steps が変化しても、性能が向上するどころかむしろ悪化するケースが多いように思います。
for name, X, y in [["training", X_train, y_train], ["validation", X_valid, y_valid], ["test", X_test, y_test]]:
plt.scatter(y, model.predict(X), alpha=0.5, label=name)
plt.plot([3, 8], [3, 8])
plt.grid()
plt.legend()
plt.xlabel("True")
plt.ylabel("Predicted")
plt.show()



転移学習?半教師あり学習?
ここまでは、赤ワインのデータのみを用いて、赤ワインの品質を予測しました。事前学習も、赤ワインのデータのみ(ラベルデータなし)を用いました。次は、試しに白ワインのデータ(ラベルデータなし)を事前学習に用いてみます。これって、転移学習と呼べるのかな?半教師あり学習と呼べるのかな?という疑問が浮かびましたがよく分かりません。
from sklearn.model_selection import train_test_split
random_state = 53
X_train2, X_valid2, y_train2, y_valid2 = train_test_split(white_wine.iloc[:, :-1].values, white_wine.iloc[:, [-1]].values, test_size=.3, random_state=random_state)
X_train2.shape, y_train2.shape
((3428, 11), (3428, 1))
X_valid2.shape, y_valid2.shape
((1470, 11), (1470, 1))
事前学習用のデータを置き換えるだけで、それ以外は特に変わりませんね。
from pytorch_tabnet.pretraining import TabNetPretrainer
import numpy as np
pretrainer = TabNetPretrainer(**tabnet_params)
pretrainer.fit(
np.concatenate([X_train, X_train2]),
eval_set=[np.concatenate([X_valid, X_valid2])],
max_epochs=5000,
patience=100,
)
Device used : cuda
epoch 0 | loss: 16660.33889| val_0_unsup_loss: 2446820.75| 0:00:00s
epoch 10 | loss: 28.30764| val_0_unsup_loss: 613.03979| 0:00:04s
epoch 20 | loss: 27.08781| val_0_unsup_loss: 283.35773| 0:00:07s
epoch 30 | loss: 3.24114 | val_0_unsup_loss: 62.06253| 0:00:11s
epoch 40 | loss: 7.27796 | val_0_unsup_loss: 91.33012| 0:00:15s
epoch 50 | loss: 13.21588| val_0_unsup_loss: 15.54838| 0:00:18s
epoch 60 | loss: 20.57722| val_0_unsup_loss: 32.31664| 0:00:22s
epoch 70 | loss: 3.17627 | val_0_unsup_loss: 11.90612| 0:00:25s
epoch 80 | loss: 1.67535 | val_0_unsup_loss: 39.38104| 0:00:29s
epoch 90 | loss: 1.55993 | val_0_unsup_loss: 32.15377| 0:00:32s
epoch 100| loss: 3.09699 | val_0_unsup_loss: 34.45182| 0:00:36s
epoch 110| loss: 2.2177 | val_0_unsup_loss: 36.49228| 0:00:39s
epoch 120| loss: 2.08958 | val_0_unsup_loss: 32.53637| 0:00:43s
epoch 130| loss: 1.42668 | val_0_unsup_loss: 38.60402| 0:00:46s
epoch 140| loss: 1.40155 | val_0_unsup_loss: 44.6946 | 0:00:50s
epoch 150| loss: 1.37884 | val_0_unsup_loss: 40.0892 | 0:00:54s
epoch 160| loss: 1.3745 | val_0_unsup_loss: 41.22863| 0:00:57s
epoch 170| loss: 1.56642 | val_0_unsup_loss: 41.14534| 0:01:01s
Early stopping occurred at epoch 170 with best_epoch = 70 and best_val_0_unsup_loss = 11.90612
Best weights from best epoch are automatically used!
import matplotlib.pyplot as plt
for param in ['loss', 'lr', 'val_0_unsup_loss']:
plt.plot(pretrainer.history[param])
plt.xlabel('epoch')
plt.ylabel(param)
plt.grid()
plt.show()



事前学習を終えて、本番の学習です。
import torch
from pytorch_tabnet.tab_model import TabNetRegressor
# from pytorch_tabnet.tab_model import TabNetClassifier
model = TabNetRegressor(**tabnet_params)
# model = TabNetClassifier()
model.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)],
max_epochs=5000,
patience=100,
eval_metric={'rmse'}, # 'rmsle', 'mse', 'mae'
from_unsupervised=pretrainer
)
Device used : cuda
Loading weights from unsupervised pretraining
epoch 0 | loss: 45.92977| val_0_rmse: 7.19955 | 0:00:00s
epoch 10 | loss: 9.63374 | val_0_rmse: 2.01992 | 0:00:00s
epoch 20 | loss: 2.10203 | val_0_rmse: 0.92411 | 0:00:01s
epoch 30 | loss: 0.73812 | val_0_rmse: 0.98633 | 0:00:02s
epoch 40 | loss: 0.55103 | val_0_rmse: 1.05893 | 0:00:03s
epoch 50 | loss: 0.43789 | val_0_rmse: 0.9111 | 0:00:03s
epoch 60 | loss: 0.42148 | val_0_rmse: 0.8362 | 0:00:04s
epoch 70 | loss: 0.4075 | val_0_rmse: 0.8341 | 0:00:05s
epoch 80 | loss: 0.42913 | val_0_rmse: 0.78552 | 0:00:05s
epoch 90 | loss: 0.38573 | val_0_rmse: 0.76019 | 0:00:06s
epoch 100| loss: 0.38899 | val_0_rmse: 0.74047 | 0:00:07s
epoch 110| loss: 0.36617 | val_0_rmse: 0.73821 | 0:00:08s
epoch 120| loss: 0.35307 | val_0_rmse: 0.715 | 0:00:08s
epoch 130| loss: 0.34752 | val_0_rmse: 0.70871 | 0:00:09s
epoch 140| loss: 0.33744 | val_0_rmse: 0.69098 | 0:00:10s
epoch 150| loss: 0.34046 | val_0_rmse: 0.69176 | 0:00:11s
epoch 160| loss: 0.31546 | val_0_rmse: 0.68321 | 0:00:11s
epoch 170| loss: 0.32649 | val_0_rmse: 0.67995 | 0:00:12s
epoch 180| loss: 0.32596 | val_0_rmse: 0.68038 | 0:00:13s
epoch 190| loss: 0.30284 | val_0_rmse: 0.67161 | 0:00:13s
epoch 200| loss: 0.31748 | val_0_rmse: 0.67932 | 0:00:14s
epoch 210| loss: 0.30808 | val_0_rmse: 0.67495 | 0:00:15s
epoch 220| loss: 0.30112 | val_0_rmse: 0.67347 | 0:00:15s
epoch 230| loss: 0.29536 | val_0_rmse: 0.67413 | 0:00:16s
epoch 240| loss: 0.29671 | val_0_rmse: 0.67068 | 0:00:17s
epoch 250| loss: 0.28007 | val_0_rmse: 0.66754 | 0:00:18s
epoch 260| loss: 0.2999 | val_0_rmse: 0.66688 | 0:00:18s
epoch 270| loss: 0.29132 | val_0_rmse: 0.66692 | 0:00:19s
epoch 280| loss: 0.28029 | val_0_rmse: 0.66665 | 0:00:20s
epoch 290| loss: 0.278 | val_0_rmse: 0.66944 | 0:00:21s
epoch 300| loss: 0.29261 | val_0_rmse: 0.66767 | 0:00:21s
epoch 310| loss: 0.28728 | val_0_rmse: 0.66728 | 0:00:22s
epoch 320| loss: 0.27489 | val_0_rmse: 0.66367 | 0:00:23s
epoch 330| loss: 0.26925 | val_0_rmse: 0.66052 | 0:00:23s
epoch 340| loss: 0.26379 | val_0_rmse: 0.65765 | 0:00:24s
epoch 350| loss: 0.28442 | val_0_rmse: 0.65711 | 0:00:25s
epoch 360| loss: 0.28069 | val_0_rmse: 0.65617 | 0:00:26s
epoch 370| loss: 0.28303 | val_0_rmse: 0.65606 | 0:00:26s
epoch 380| loss: 0.29653 | val_0_rmse: 0.65791 | 0:00:27s
epoch 390| loss: 0.27669 | val_0_rmse: 0.65919 | 0:00:28s
epoch 400| loss: 0.2771 | val_0_rmse: 0.66249 | 0:00:28s
epoch 410| loss: 0.26686 | val_0_rmse: 0.66416 | 0:00:29s
epoch 420| loss: 0.26393 | val_0_rmse: 0.66477 | 0:00:30s
epoch 430| loss: 0.26517 | val_0_rmse: 0.66507 | 0:00:31s
epoch 440| loss: 0.28231 | val_0_rmse: 0.66406 | 0:00:31s
epoch 450| loss: 0.26679 | val_0_rmse: 0.66527 | 0:00:32s
epoch 460| loss: 0.27933 | val_0_rmse: 0.66518 | 0:00:33s
Early stopping occurred at epoch 461 with best_epoch = 361 and best_val_0_rmse = 0.6559
Best weights from best epoch are automatically used!
import matplotlib.pyplot as plt
for param in ['loss', 'lr', 'val_0_rmse']:
plt.plot(model.history[param], label=param)
plt.xlabel('epoch')
plt.grid()
plt.legend()
plt.show()



from sklearn.metrics import mean_squared_error
test_score = mean_squared_error(model.predict(X_test), y_test)
print(f"BEST VALID SCORE: {model.best_cost}")
print(f"FINAL TEST SCORE: {test_score}")
BEST VALID SCORE: 0.6558970337385635
FINAL TEST SCORE: 0.48485043537972694
おお、向上しましたね。今までで一番良い数字です。ですがこれも、私の少ない経験上、train_test_split による分割が変化しても、random seed が変化しても、n_steps が変化しても、性能が向上するどころかむしろ悪化するケースが多いように思います。
for name, X, y in [["training", X_train, y_train], ["validation", X_valid, y_valid], ["test", X_test, y_test]]:
plt.scatter(y, model.predict(X), alpha=0.5, label=name)
plt.plot([3, 8], [3, 8])
plt.grid()
plt.legend()
plt.xlabel("True")
plt.ylabel("Predicted")
plt.show()



Feature importance (Global interpretability)
TabNetの特徴として、RandomForestなどと類似した Feature importanceが算出できることが挙げられます。TabNetでは、Global interpretability とも呼ばれます。
plt.barh(list(red_wine.columns[:-1])[::-1], model.feature_importances_[::-1])
plt.grid()
plt.show()

Mask (Local interpretability)
TabNetではそれに加えて、どの特徴量を使うか decision making するのに用いた mask というのを見ることができます。Local interpretability とも呼ばれます。mask は n_steps の数だけあります。ここでは、予測したデータの先頭 50 個についてのみ図示してみます。
explain_matrix, masks = model.explain(X_test)
fig, axs = plt.subplots(N_STEPS, 1, figsize=(21, 3*N_STEPS))
for i in range(N_STEPS):
axs[i].imshow(masks[i][:50].T)
axs[i].set_title(f"mask {i}")
axs[i].set_yticks(range(len(red_wine.columns[:-1])))
axs[i].set_yticklabels(list(red_wine.columns[:-1]))

ScikitAllstarsと比較
ScikitAllstars は、scikit-learn の主要な教師あり機械学習モデルをひとまとめに oputuna でハイパラチューニングするツールです。上記と同じデータを予測して比較してみましょう。
# Optuna のインストール
!pip install optuna
# ScikitAllStars のインストール
!pip install git+https://github.com/maskot1977/scikitallstars.git
import pandas as pd
red_wine = pd.read_csv('https://raw.githubusercontent.com/chemo-wakate/tutorial-6th/master/beginner/data/winequality-red.txt', sep='\t', index_col=0)
red_wine
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.700 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.99780 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.880 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.99680 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.760 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.99700 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.280 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.99800 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.700 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.99780 | 3.51 | 0.56 | 9.4 | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1594 | 6.2 | 0.600 | 0.08 | 2.0 | 0.090 | 32.0 | 44.0 | 0.99490 | 3.45 | 0.58 | 10.5 | 5 |
| 1595 | 5.9 | 0.550 | 0.10 | 2.2 | 0.062 | 39.0 | 51.0 | 0.99512 | 3.52 | 0.76 | 11.2 | 6 |
| 1596 | 6.3 | 0.510 | 0.13 | 2.3 | 0.076 | 29.0 | 40.0 | 0.99574 | 3.42 | 0.75 | 11.0 | 6 |
| 1597 | 5.9 | 0.645 | 0.12 | 2.0 | 0.075 | 32.0 | 44.0 | 0.99547 | 3.57 | 0.71 | 10.2 | 5 |
| 1598 | 6.0 | 0.310 | 0.47 | 3.6 | 0.067 | 18.0 | 42.0 | 0.99549 | 3.39 | 0.66 | 11.0 | 6 |
1599 rows × 12 columns
from sklearn.model_selection import train_test_split
random_state = 0
X_train, X_test, y_train, y_test = train_test_split(red_wine.iloc[:, :-1].values, red_wine.iloc[:, [-1]].values, test_size=.3, random_state=random_state)
AllstarsModel の学習
from scikitallstars import allstars, depict
allstars_model = allstars.fit(X_train, y_train, timeout=1000, n_trials=100, feature_selection=True)
feature selection: X_train (1119, 11) -> (1119, 3)
{'GradientBoosting': 0.4388699431816158, 'ExtraTrees': 0.49443573617340997, 'RandomForest': 0.4434120482153883, 'AdaBoost': 0.4073180139136409, 'MLP': 0.3670088611377368, 'SVR': 0.40403614655933495, 'kNN': 0.43064459007357375, 'Ridge': 0.39026600919071514, 'Lasso': 0.39172487228440867, 'PLS': 0.39819809406714757, 'LinearRegression': 0.4125666488108234}
from sklearn.metrics import mean_squared_error
test_score = mean_squared_error(allstars_model.predict(X_test), y_test)
print(f"FINAL TEST SCORE: {test_score}")
FINAL TEST SCORE: 0.42362855816765
import matplotlib.pyplot as plt
for name, X, y in [["training", X_train, y_train], ["test", X_test, y_test]]:
plt.scatter(y, allstars_model.predict(X), alpha=0.5, label=name)
plt.plot([3, 8], [3, 8])
plt.grid()
plt.legend()
plt.xlabel("True")
plt.ylabel("Predicted")
plt.show()


StackingModel の学習
stacking_model = allstars.get_best_stacking(allstars_model, X_train, y_train, timeout=1000, n_trials=100)
from sklearn.metrics import mean_squared_error
test_score = mean_squared_error(stacking_model.predict(X_test), y_test)
print(f"FINAL TEST SCORE: {test_score}")
FINAL TEST SCORE: 0.4301126301454623
import matplotlib.pyplot as plt
for name, X, y in [["training", X_train, y_train], ["test", X_test, y_test]]:
plt.scatter(y, stacking_model.predict(X), alpha=0.5, label=name)
plt.plot([3, 8], [3, 8])
plt.grid()
plt.legend()
plt.xlabel("True")
plt.ylabel("Predicted")
plt.show()


結果
あれ? TabNet 負けちゃった。まあ、どんなデータでも勝てるわけじゃないんでしょうね。あるいは私の TabNet に対する理解が足りなくて、しょぼい使い方しかできてない可能性も。
今回は回帰モデルを作ってみましたが、そのうち分類とかもやります。そのうち。