グラフ構造を深層学習する PyG (PyTorch Geometric) を Google Colaboratory 上で使ってみました。今回は、Node2Vec を使うことがテーマです。
PyG (PyTorch Geometric) インストール
PyG (PyTorch Geometric) のレポジトリは https://github.com/pyg-team/pytorch_geometric にあります。また、コードはチュートリアルドキュメント https://pytorch-geometric.readthedocs.io/en/latest/index.html を参考にしています。
import os
import torch
torch.manual_seed(53)
os.environ['TORCH'] = torch.__version__
print(torch.__version__)
!pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q git+https://github.com/pyg-team/pytorch_geometric.git
!pip install torch-cluster -f https://data.pyg.org/whl/torch-${TORCH}.html
import torch_cluster
import torch_geometric
1.12.0+cu113
[K |████████████████████████████████| 7.9 MB 23.5 MB/s
[K |████████████████████████████████| 3.5 MB 28.5 MB/s
[?25h Building wheel for torch-geometric (setup.py) ... [?25l[?25hdone
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Looking in links: https://data.pyg.org/whl/torch-1.12.0+cu113.html
Collecting torch-cluster
Downloading https://data.pyg.org/whl/torch-1.12.0%2Bcu113/torch_cluster-1.6.0-cp37-cp37m-linux_x86_64.whl (2.4 MB)
[K |████████████████████████████████| 2.4 MB 18.5 MB/s
[?25hInstalling collected packages: torch-cluster
Successfully installed torch-cluster-1.6.0
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#device = "cpu"
データセットの自作
今回もデータセットを自作します。自作する理由は、結果の良し悪しを自分の目で判断しやすくするためです。
GridDataset
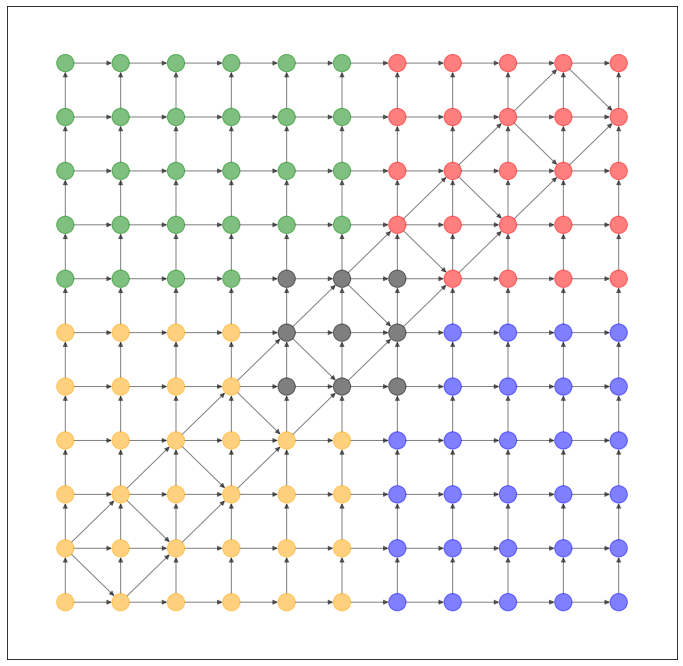
格子状のネットワークのデータセットを作ってみました。過去記事と比べて配色を変更しています。
import numpy as np
from scipy.spatial import distance
from torch_geometric.data import Data, InMemoryDataset
class GridDataset(InMemoryDataset):
def __init__(self, transform = None):
super().__init__('.', transform)
f = lambda x: np.linalg.norm(x) - np.arctan2(x[0], x[1])
embeddings = []
ys = []
for x in range(-10, 11, 2):
for y in range(-10, 11, 2):
embeddings.append([x, y])
if abs(x) < 3 and abs(y) < 3:
ys.append(4)
elif x > 0:
if y > 0:
ys.append(0)
else:
ys.append(1)
else:
if y > 0:
ys.append(2)
else:
ys.append(3)
embeddings = torch.tensor(embeddings, dtype=torch.float)
ys = torch.tensor(ys, dtype=torch.float)
dist_matrix = distance.cdist(embeddings, embeddings, metric='euclidean')
edges = []
edge_attr = []
for i in range(len(dist_matrix)):
for j in range(len(dist_matrix)):
if i < j:
if dist_matrix[i][j] == 2:
edges.append([i, j])
edge_attr.append(abs(f(embeddings[i]) - f(embeddings[j])))
elif dist_matrix[i][j] < 3 and (
embeddings[i][0] == embeddings[j][1] or
embeddings[i][1] == embeddings[j][0]
):
edges.append([i, j])
edge_attr.append(abs(f(embeddings[i]) - f(embeddings[j])))
edges = torch.tensor(edges, dtype=torch.long).T
edge_attr = torch.tensor(edge_attr, dtype=torch.long)
data = Data(x=embeddings, edge_index=edges, y=ys, edge_attr=edge_attr)
self.data, self.slices = self.collate([data])
self.data.num_nodes = len(embeddings)
def layout(self):
return {i:x.detach().numpy() for i, x in enumerate(self.data.x)}
def node_color(self):
c = {0:"red", 1:"blue", 2:"green", 3:"orange", 4:'black'}
return [c[int(x.detach().numpy())] for (i, x) in enumerate(self.data.y)]
NetworkX で可視化すると、このようなネットワークになります。
import networkx as nx
import matplotlib.pyplot as plt
dataset = GridDataset()
G = torch_geometric.utils.convert.to_networkx(dataset.data)
plt.figure(figsize=(12,12))
nx.draw_networkx(G, pos=dataset.layout(), with_labels=False, alpha=0.5, node_color=dataset.node_color())
次のようにして、データセットを選択します。
use_dataset = GridDataset
今回は、Node2vec でノード(頂点)の embedding (ベクトル化)を試みます。その性能を確認するため、x (ノードに事前に与えられた説明変数ベクトル)と edge_attr (エッジに事前に与えられた説明変数ベクトル)を全てゼロにします。ノード同士の接続関係だけから、どのような embedding ができるかを知ることが今回の目的です。
dataset = use_dataset()
data = dataset.data
data.x = torch.zeros_like(data.x)
data.edge_attr = torch.zeros_like(data.edge_attr)
学習
ノードを train, val, test に分割します。
def train_val_test_split(data, val_ratio: float = 0.15,
test_ratio: float = 0.15):
rnd = torch.rand(len(data.x))
train_mask = [False if (x > val_ratio + test_ratio) else True for x in rnd]
val_mask = [False if (val_ratio + test_ratio >= x) and (x > test_ratio) else True for x in rnd]
test_mask = [False if (test_ratio >= x) else True for x in rnd]
return torch.tensor(train_mask), torch.tensor(val_mask), torch.tensor(test_mask)
train_mask, val_mask, test_mask = train_val_test_split(data)
data.train_mask = train_mask
data.val_mask = val_mask
data.test_mask = test_mask
training のための関数です。
def train():
model.train()
total_loss = 0
for pos_rw, neg_rw in loader:
optimizer.zero_grad()
loss = model.loss(pos_rw.to(device), neg_rw.to(device))
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
test のための関数です。
@torch.no_grad()
def test():
model.eval()
z = model()
acc = model.test(z[data.train_mask], data.y[data.train_mask],
z[data.test_mask], data.y[data.test_mask],
max_iter=150)
return acc
モデルやオプティマイザをセットします。まずは embedding_dim を 2 にします。つまり、ノード同士の接続関係を2次元のベクトルで表現できるか試すことになります。
model = torch_geometric.nn.Node2Vec(
data.edge_index, embedding_dim=2, walk_length=20,
context_size=10, walks_per_node=20,
num_negative_samples=10, p=0.5, q=1, sparse=True).to(device)
loader = model.loader(batch_size=64, shuffle=True, num_workers=2)
optimizer = torch.optim.SparseAdam(list(model.parameters()), lr=0.01)
学習を実行します。
import copy
best_score = None
loss_hist = []
acc_hist = []
for epoch in range(0, 1001):
loss = train()
acc = test()
loss_hist.append(loss)
acc_hist.append(acc)
if best_score is None or best_score < acc:
best_score = acc
best_model = copy.deepcopy(model)
print(f'Epoch: {epoch+1:02d}, Loss: {loss:.5f}, Acc: {acc:.5f}')
Epoch: 01, Loss: 1.74069, Acc: 0.27660
Epoch: 06, Loss: 1.62649, Acc: 0.28723
Epoch: 27, Loss: 1.34326, Acc: 0.30851
Epoch: 28, Loss: 1.33030, Acc: 0.31915
Epoch: 34, Loss: 1.27530, Acc: 0.35106
Epoch: 38, Loss: 1.24524, Acc: 0.36170
Epoch: 49, Loss: 1.16714, Acc: 0.38298
Epoch: 53, Loss: 1.14541, Acc: 0.39362
Epoch: 55, Loss: 1.13304, Acc: 0.41489
Epoch: 59, Loss: 1.11387, Acc: 0.42553
Epoch: 61, Loss: 1.10355, Acc: 0.43617
Epoch: 62, Loss: 1.09994, Acc: 0.45745
Epoch: 65, Loss: 1.08746, Acc: 0.46809
Epoch: 72, Loss: 1.06423, Acc: 0.47872
Epoch: 113, Loss: 1.00410, Acc: 0.48936
Epoch: 114, Loss: 1.00273, Acc: 0.50000
Epoch: 115, Loss: 1.00437, Acc: 0.51064
Epoch: 124, Loss: 0.99616, Acc: 0.52128
Epoch: 127, Loss: 0.99517, Acc: 0.53191
Epoch: 129, Loss: 0.99567, Acc: 0.54255
Epoch: 130, Loss: 0.99516, Acc: 0.56383
Epoch: 131, Loss: 0.99417, Acc: 0.57447
Epoch: 143, Loss: 0.98970, Acc: 0.58511
Epoch: 144, Loss: 0.98796, Acc: 0.59574
Epoch: 151, Loss: 0.98431, Acc: 0.60638
Epoch: 156, Loss: 0.98121, Acc: 0.61702
Epoch: 158, Loss: 0.98392, Acc: 0.62766
Epoch: 165, Loss: 0.98029, Acc: 0.63830
Epoch: 166, Loss: 0.97875, Acc: 0.64894
Epoch: 174, Loss: 0.97582, Acc: 0.65957
Epoch: 179, Loss: 0.97306, Acc: 0.67021
Epoch: 194, Loss: 0.96547, Acc: 0.69149
Epoch: 203, Loss: 0.96263, Acc: 0.70213
Epoch: 214, Loss: 0.95930, Acc: 0.71277
学習結果 (embedding_dim = 2)
学習の履歴は次のようになりました。
import matplotlib.pyplot as plt
plt.plot(loss_hist, label="Loss")
plt.legend()
plt.grid()
plt.show()
plt.plot(acc_hist, label="ACC")
plt.legend()
plt.grid()
plt.show()
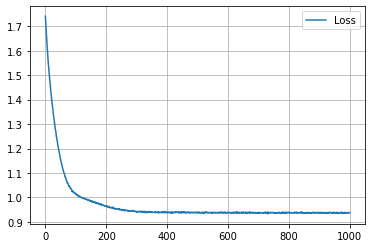
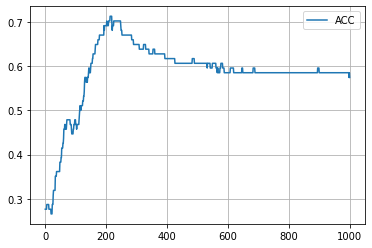
epoch = 200 付近でACCがピークを迎え、その後に下がって、上がらなくなってしまいましたね。
Node2vec は、ネットワークを生成するための方法ではありませんが、過去記事のときと同じ要領でネットワークを生成してみましょう(期待はできませんが)
z = best_model(torch.arange(data.num_nodes, device=device))
prob_adj = z @ z.T
#prob_adj = prob_adj - torch.diagonal(prob_adj)
prob_adj
tensor([[ 0.5890, 0.5896, 0.5865, ..., -1.0625, -1.5954, -2.4958],
[ 0.5896, 0.5909, 0.5855, ..., -1.0444, -1.6128, -2.4809],
[ 0.5865, 0.5855, 0.5879, ..., -1.1041, -1.5505, -2.5270],
...,
[-1.0625, -1.0444, -1.1041, ..., 2.4545, 2.4354, 4.9905],
[-1.5954, -1.6128, -1.5505, ..., 2.4354, 4.6852, 6.3580],
[-2.4958, -2.4809, -2.5270, ..., 4.9905, 6.3580, 11.0184]],
device='cuda:0', grad_fn=<MmBackward0>)
prob_adj_values = prob_adj.detach().cpu().numpy().flatten()
prob_adj_values.sort()
dataset = use_dataset()
threshold = max(0, prob_adj_values[-len(dataset.data.edge_attr)])
dataset.data.edge_index = (prob_adj >= threshold).nonzero(as_tuple=False).t()
import networkx as nx
import matplotlib.pyplot as plt
G = torch_geometric.utils.convert.to_networkx(dataset.data)
plt.figure(figsize=(12,12))
nx.draw_networkx(G, pos=dataset.layout(), with_labels=False, alpha=0.5, node_color=dataset.node_color())
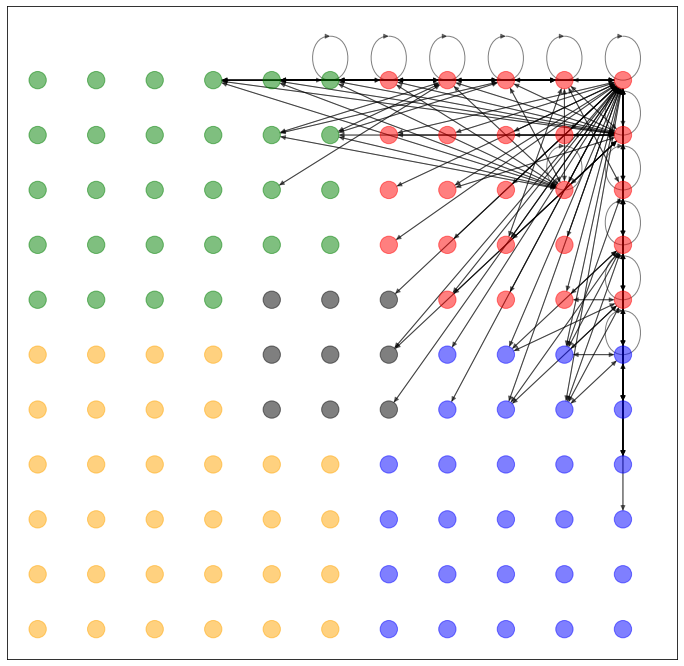
期待通り(?)、でたらめなネットワークしか生成できていないようです(なぜか赤い頂点の近くに偏ってますね)。というより、ここで求める z が、それを目的とした潜在空間ではないんですね。
では、得られた潜在空間 z を2次元平面上にマッピングします。ここで、グレーの線は自動生成されたネットワークではなく、元々のネットワークの接続関係を示します。
from sklearn.manifold import Isomap
@torch.no_grad()
def plot_points(colors):
model.eval()
z = model(torch.arange(data.num_nodes, device=device)).cpu().numpy()
#z = Isomap(n_components=2).fit_transform(z)
y = data.y.cpu().numpy()
plt.figure(figsize=(8, 8))
for i, j in data.edge_index.numpy().T:
plt.plot([z[i][0], z[j][0]], [z[i][1], z[j][1]], color="black", alpha=0.1)
for i in range(dataset.num_classes):
plt.scatter(z[y == i, 0], z[y == i, 1], s=60, color=colors[i], alpha=0.5)
plt.axis('off')
plt.show()
colors = [
'#ffc0cb', '#bada55', '#008080', '#420420', '#7fe5f0', '#065535',
'#ffd700'
]
colors = ['red', 'blue', 'green', 'orange', 'black']
plot_points(colors)

赤だけなぜか特別扱いされていたり、グリッド構造がつぶれていたりしてますが、「ノード(頂点)間の接続関係」だけから、ノードの座標(embedding)がわりとよく表されているように見えますね。
学習結果 (embedding_dim = 4)
続いて、embedding_dim = 4 で学習してみました。潜在空間の次元を上げるとどのような効果が得られるか確認したかったからです。コードは省略しますので、結果だけどうぞ。
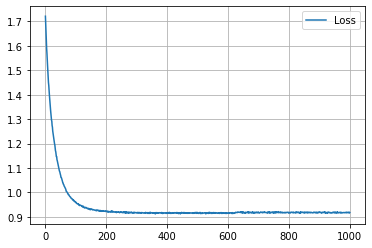
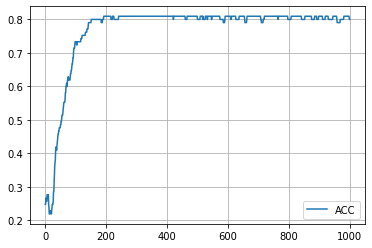
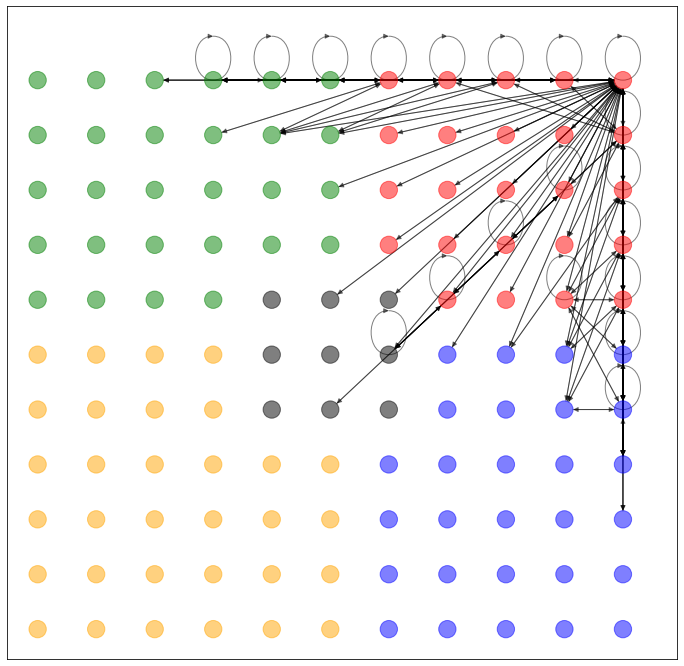
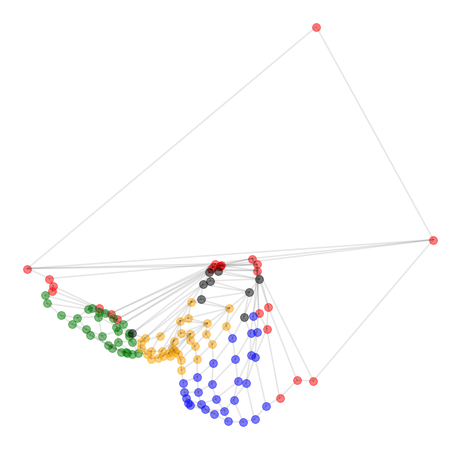
ACC が上昇して、高止まりするようになりましたね。それ以外は、embedding_dim = 2 のときと比べて大差なさそうです。
学習結果 (embedding_dim = 8)
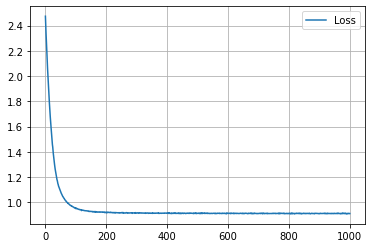
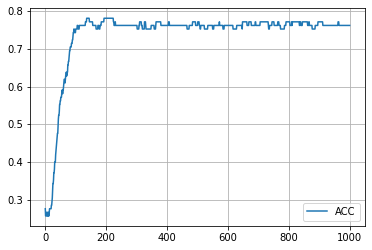
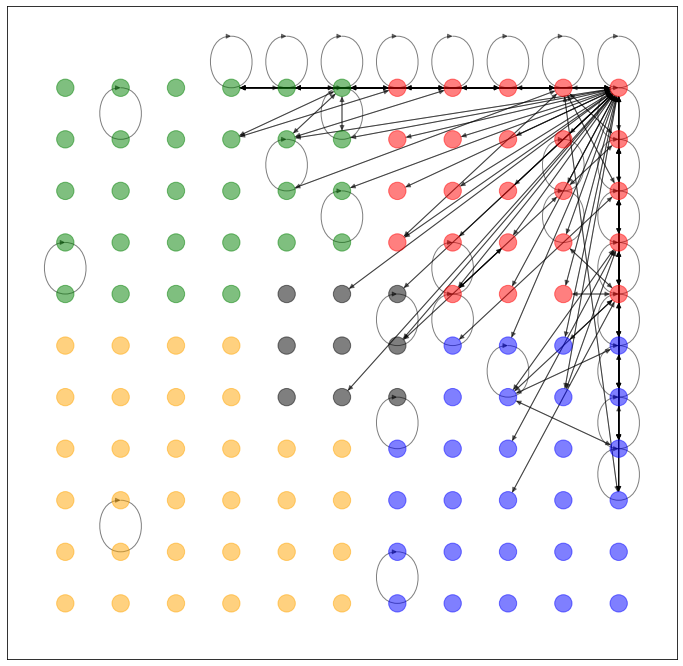
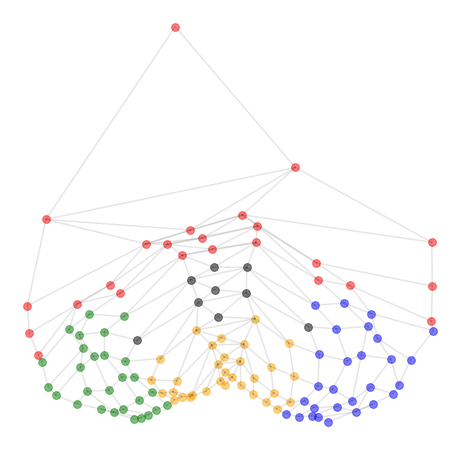
embedding_dim = 4 のときと比べて、 ACC の値は少し下がりました。ですが、潜在空間を2次元上にプロットした時のネットワークの広がり方は、よくなった感がありますね(主観的に)。
学習結果 (embedding_dim = 16)
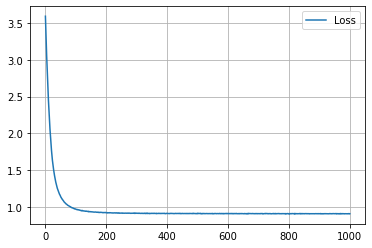
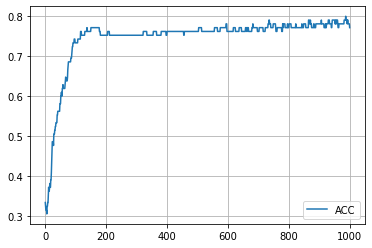
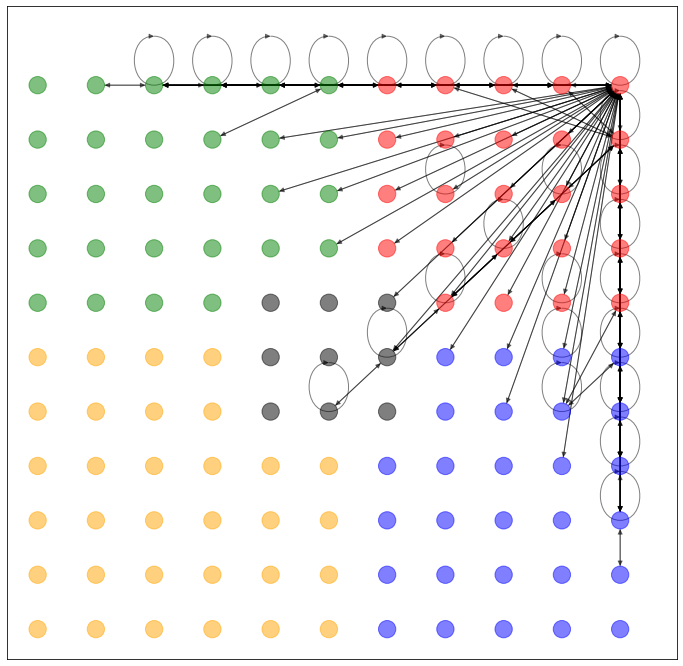
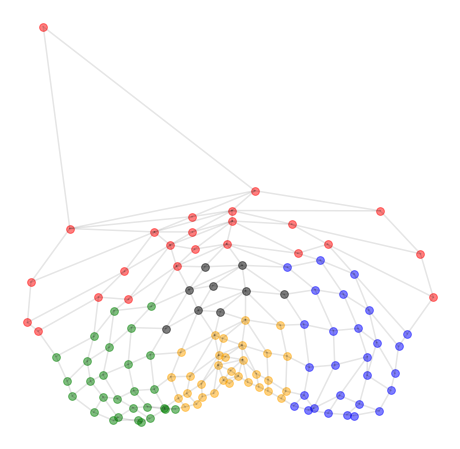
ACC の上がり方を見ると、エポック数をもっと増やせばもう少し改善の余地があるのかもしれません。潜在空間の2次元プロットは、あまり変わってないようにも見えるし、少しくらいは改善したように見えなくもないです(主観)。
学習結果 (embedding_dim = 32)
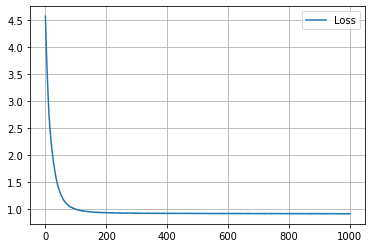
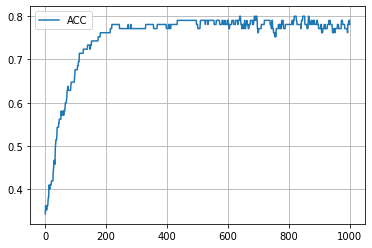
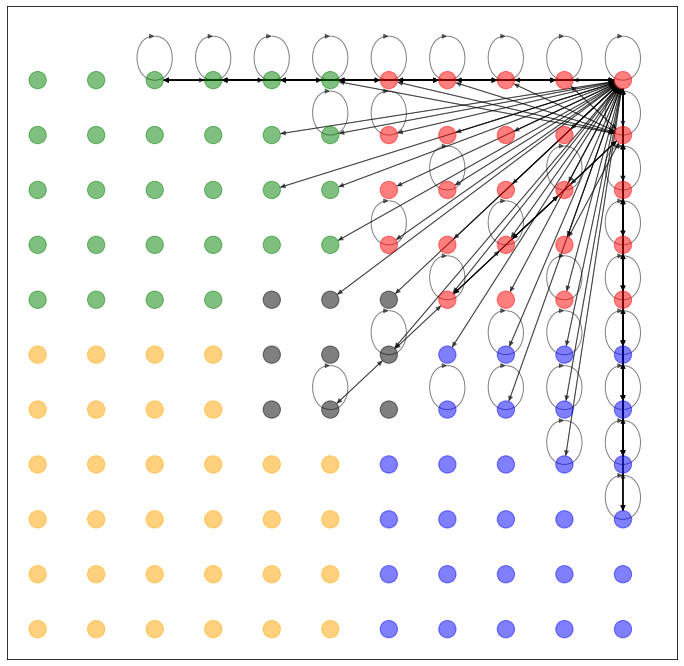
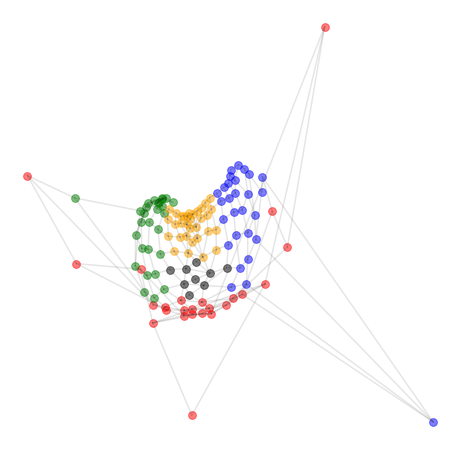
学習曲線の ACC が、最後の方フラフラするようになりました。潜在空間の2次元プロットが、なんか潰れ始めたような気がします。潜在空間の次元を大きくしすぎると、良くないのかもしれません。
学習結果 (embedding_dim = 64)
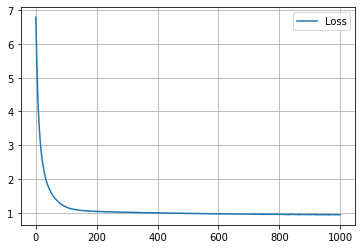
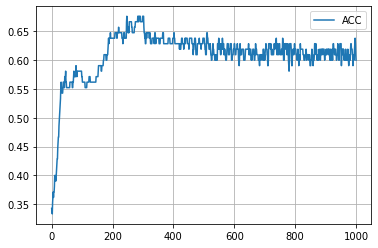
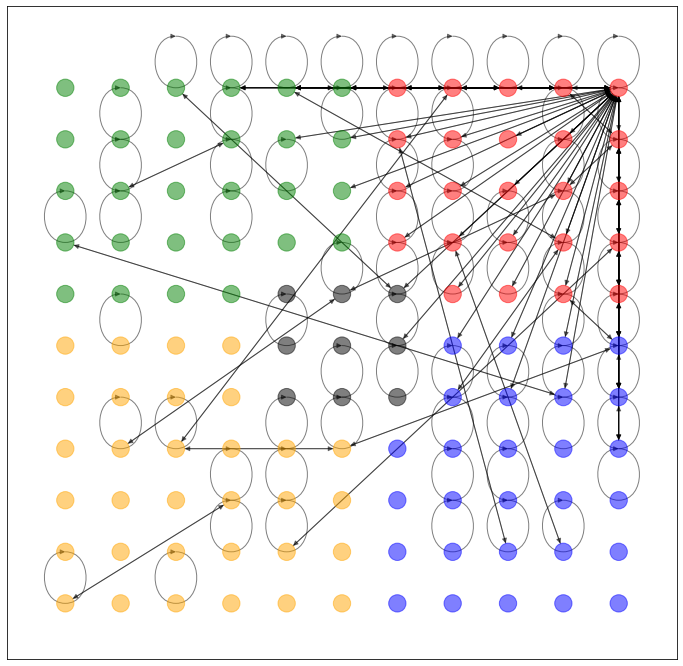
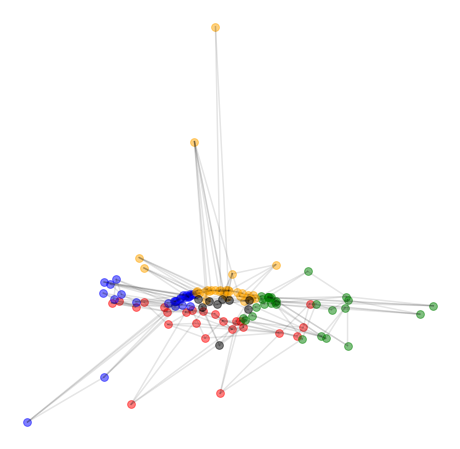
潜在空間の次元をさらに上げると、 Loss も最後の方ちょっと下がらなくなってきたし、ACC の学習曲線もガタついてきたし、生成ネットワーク(?)も変に広がってきたし、潜在空間の2次元プロットも潰れてしまいました。これはこれで意味があるのか?(なさそう)
学習結果 (embedding_dim = 128)
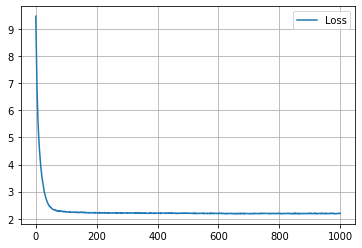
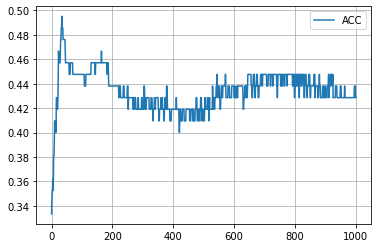

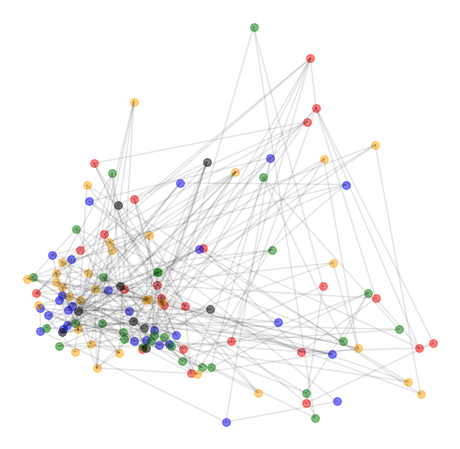
最後に embedding_dim = 128 にすると、 Loss もさらに悪くなったし、 ACC もさらに悪くなったし、生成ネットワーク(?)も、潜在空間の2次元プロットも、全部悪くなったように見えますね。
まとめ
Node2Vec の挙動を確認するため、2次元平面上でグリッド上に見えるネットワークを Node2Vec で node embedding してみました。今回のネットワークに対しては、潜在空間の次元は embedding_dim = 16 前後が最適な気がします。次元を上げすぎても良くないだろうということが実感できました。