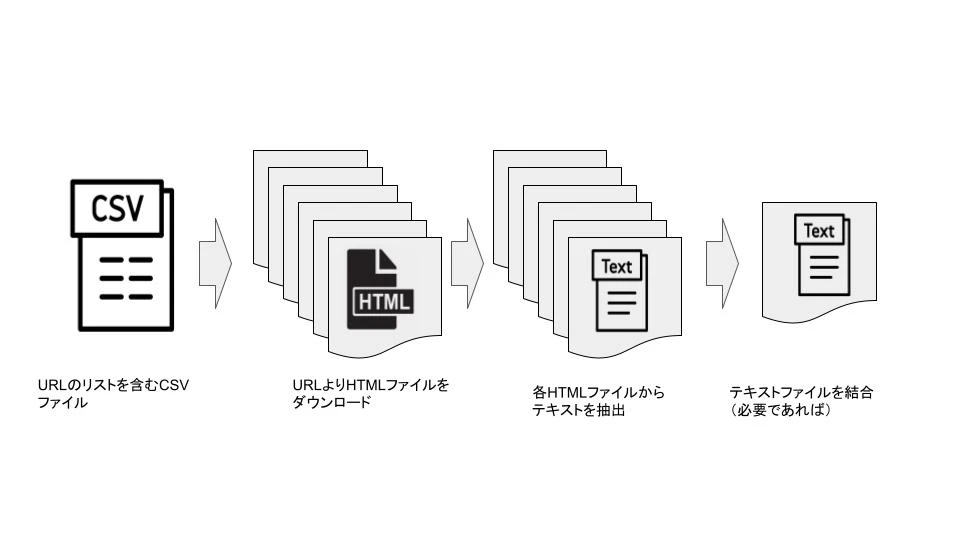
こんにちは!今回は、Pythonを使用してCSVファイル内にリストされたURLからWebページのHTMLテキストを抽出するプログラムを解説します。
1. はじめに
Webスクレイピングは、Webページから情報を自動的に取得・収集する技術のことです。プログラムを使用してWebサイトを訪問し、必要なデータを抽出する作業を行います。例えば、商品の価格や在庫情報、ニュース記事のテキストなど、様々な情報を効率的に収集するために使用されます。
しかし、スクレイピングは以下の点に注意が必要です:
法的問題:無許可でのスクレイピングは、著作権侵害や不正アクセスとみなされることがあります。
サイトの利用規約:多くのWebサイトは利用規約でスクレイピングを禁止している場合があります。
サーバーへの負荷:頻繁なアクセスはサイトのサーバーに負荷をかける可能性があります。
適切な方法で行われるスクレイピングは、データ解析や市場調査などの多岐にわたる用途で非常に有用ですが、行う前には十分な注意と配慮が必要です。
実際にスクレイピングを禁止しているWebサイトも存在し、Amazonや楽天、Twitterなど大手サイトでは利用規約でスクレイピングを禁止しています。スクレイピングを行う前に、対象サイトの利用規約やrobot.txtを確認し、必要に応じて専門家に相談するようにしましょう。
2. HTML取得関数
fetch_html関数は、指定したURLからHTMLを取得して、文字列として返します。
with urllib.request.urlopen(url) as res:: urllib.request.urlopen
は指定されたURLを開くためのPythonの関数です。with文を使用することで、レスポンスオブジェクトresを適切にクローズします(レスポンスのリソースを解放します)。
html = res.read().decode(): res.read()はURLから取得したデータ(通常はバイト型)を読み取ります。decode()メソッドはバイト型のデータを文字列(デフォルトでutf-8)に変換します。この結果として得られる文字列は、HTMLとして変数htmlに格納されます。
def fetch_html(url: str) -> str:
with urllib.request.urlopen(url) as res:
html = res.read().decode()
return html
3. 空白行の削除
remove_blank_lines関数は、テキスト内の空白の行を削除します。
def remove_blank_lines(text):
lines = text.split('\n')
non_blank_lines = [line for line in lines if line.strip()]
return '\n'.join(non_blank_lines)
4. CSVからURLのリストの作成
create_url_list関数は、指定したCSVファイルと列からURLのリストを作成します。
def create_url_list(csv_file,target_column_index):
url_list = []
with open(csv_file, 'r', encoding='SHIFT_JIS') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
if len(row) > target_column_index: # 行が指定した列を持つか確認
cell_value = row[target_column_index]
urls = re.findall(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', cell_value)
if urls:
url_list.extend(urls)
return url_list
5. 各URLからHTMLをダウンロードしてテキストに変換
download_and_process_urls関数では、URLリストから各URLのHTMLをダウンロードし、テキストに変換します。
def download_and_process_urls(url_list):
documents = [] # 各URLのテキストを格納するリスト
for url in url_list:
try:
# URLからHTMLをダウンロード
html = fetch_html(url)
# BeautifulSoupで解析(必要に応じて行う)
soup = BeautifulSoup(html, 'html.parser')
# テキストコンテンツを抽出
text = soup.get_text() # HTML内のテキストを抽出
# 空白の行を削除
result_text = remove_blank_lines(text)
# 最後の行に改行を2つ追加
result_text += '\n\n'
# テキストをファイルに保存
with open(f'{url.split("/")[-1]}.txt', 'w', encoding='utf-8') as f:
f.write(result_text)
# documentsリストにテキストを追加
documents.append(result_text)
except urllib.error.URLError as e:
print(f"URL {url} からのダウンロードエラー: {e}")
except Exception as e:
print(f"URL {url} の処理中にエラーが発生しました: {e}")
return documents
-
html = fetch_html(url): 先ほど説明したfetch_html関数を使用して、指定されたURLからHTMLをダウンロードします。 -
soup = BeautifulSoup(html, 'html.parser'): BeautifulSoupライブラリを使用してダウンロードしたHTMLを解析します。 -
text = soup.get_text(): 解析されたHTMLからテキストコンテンツを抽出します。 -
result_text = remove_blank_lines(text): 先ほど定義したこの関数を使って、テキストから(不要な)空白の行を削除します。 -
result_text += '\n\n': あとでみやすいように、最後の行に改行を2つ追加します。
6. テキストファイルとして保存
最後に、save_documents_as_text_file関数で、抽出したテキストを指定したファイルに保存します。
def save_documents_as_text_file(documents, output_file):
with open(output_file, 'w', encoding='utf-8') as f:
for document in documents:
f.write(document + '\n')
7. メイン関数
main関数で、全体の処理を実行します。
def main():
# CSVファイルとURLのある列を指定
url_list = create_url_list('./URL_list.csv', 4)
# 各URLからHTMLをダウンロードしてテキストに変換
documents = download_and_process_urls(url_list)
# documentsを一つのテキストファイルとして保存
save_documents_as_text_file(documents, './output.txt')
if __name__ == "__main__":
main()
まとめ
このプログラムを使用すると、CSVファイルにリストされたURLから簡単にWebページのテキストを抽出できます。BeautifulSoupやrequestsなどのライブラリを活用することで、効率的なWebスクレイピングが可能です。
今回はLangChainのURLLoaderを使わず、より一般的な方法で、URLをテキストファイルへ変換する方法を紹介しました。ここで生成したテキストファイルをLangChainのtext_splitterにかければ、vectorStore作成も簡単にできます。
最後にインポートが必要なライブラリを示しておきます。
import requests
from bs4 import BeautifulSoup
import urllib.request
import csv
import re
*本記事はcode snippetをもとにChatGPTに作らせています。