Lecture08: Semantic, Instance, and Panoptic Segmentation
セグメンテーションの3つの手法
前回の振り返りと今回のテーマ
第七講では、物体を四角い枠(バウンディングボックス)で囲んで特定する「物体検出」と、その代表格であるYOLOについて学びました。
今回の第八講では、画像認識タスクの中で最も精密な手法であるセグメンテーションを深掘りします。セグメンテーションには、目的や識別の細かさに応じて大きく3つの手法があります。

参考文献[1]より引用
1. セマンティック・セグメンテーション (Semantic Segmentation)
最も基礎的な手法で、画像を「意味(Semantic)」で塗り分ける技術です。
- 定義: 画像内のすべてのピクセルに対して、あらかじめ決められたクラス(背景、道路、人など)を割り当てます。
-
特徴: 「クラス」単位で分類します。
- 個体の区別なし: 同じクラス(例:人)が複数いても、すべて同じ色(同一領域)で塗りつぶされます。
- 背景の扱い: 空や道路などの境界が曖昧な領域(Stuff:非個体領域)もすべて分類対象となります。
-
活用例:
- 自動運転: 「どこが走れる道路か」という大まかな領域の把握。
- 景観解析: 都市の空、緑地、建物の比率を計算する。
2. インスタンス・セグメンテーション (Instance Segmentation)
「個体(Instance)」を見つけ出し、その形を正確に切り抜く技術です。
- 定義: 画像内にある数えられる物体(Things)を検出し、それぞれを個別に領域分割します。
-
特徴: 「個体」単位で識別します。
- 個体の区別あり: 同じクラスでも「人A」「人B」として別々に扱います。
- 背景の扱い(Stuffの除外): 空、道路、壁などの「数えられない背景」は、基本的にはターゲット(背景以外の対象物)として認識されず、無視(あるいは一律に「背景」として処理)されます。
-
活用例:
- ロボットアーム: 積み重なった部品を1つずつ識別して掴む。
- 医療診断: 複数の細胞や腫瘍を1つずつ数え、それぞれの大きさを測る。
3. パノプティック・セグメンテーション (Panoptic Segmentation)
上記2つを統合した「完全な」画像理解のための手法です。
- 定義: 画像内の全ピクセルを分類しつつ、数えられる物体の個体識別も同時に行います。
-
特徴: セマンティック(Stuff、全ピクセル)とインスタンス(Things、個体識別)の「いいとこ取り」です。
- Stuff(非個体領域): 空、道路、草などは、セマンティックとして「領域」としてラベル付けします。
- Things(個体物体): 車、人などは、インスタンスとして「個体(ID)」を割り振って識別します。
-
活用例:
- 高度な自動運転: 周囲の風景(Stuff)と、動いている歩行者や車(Things)の正確な位置関係を同時に把握し、複雑な合流や交差点を制御する。
各手法の比較まとめ
セグメンテーションを理解する鍵は、Stuff(非個体領域:空、道、水など)とThings(個体物体:人、車、犬など)の扱いの違いにあります。
| 手法 | 対象範囲 | 識別単位 | 個体(Things)の区別 | 背景(Stuff)の分類 |
|---|---|---|---|---|
| セマンティック | 全ピクセル | クラスごと | なし | あり(領域として分類) |
| インスタンス | 物体のみ | 個体ごと | あり(一画素ずつ分離) | なし(基本は無視) |
| パノプティック | 全ピクセル | クラス + 個体 | あり(個別にID付与) | あり(領域として分類) |
このように、パノプティック・セグメンテーションは「そこに何があるか(領域)」と「どれがどれか(個体)」を完全に両立した、現在の最高峰の認識タスクと言えます。
セグメンテーション技術が向上することで、AIは単に「何があるか」を知るだけでなく、世界を「形」として緻密に捉えることができるようになります。
4. 代表的なモデル:U-Net
セグメンテーション(特にセマンティック・セグメンテーション)において非常に有名なモデルが U-Net です。
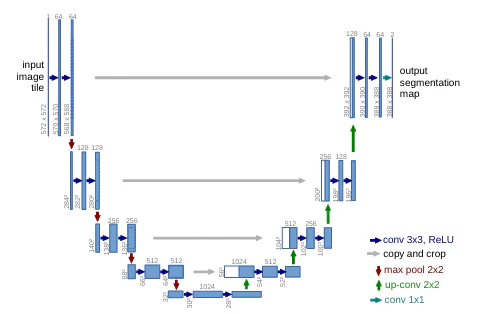
参考[2]より引用
- 特徴: 畳み込み層とプーリング層で構成され、学習に使うデータの数が少なくても高い精度を発揮します。また、学習および推論の処理が非常に高速であることも大きな特徴です。
- 名前の由来: ネットワークの構造がアルファベットの「U」の字に見えることから、U-Netと呼ばれています。前半のダウンサンプリング(Encoder)と、後半のアップサンプリング(Decoder)が対照的な構造をしています。
スキップ接続 (Skip Connection)
U-Netの最大の特徴は、スキップ接続と呼ばれる仕組みです。
- 仕組み: Encoder側の各層で出力される特徴マップを、Decoder側の対応する各層の特徴マップに直接連結(Concatenation)します。
- 目的: 畳み込みやプーリングを繰り返すと位置情報が失われがちですが、スキップ接続によってEncoderが持っていた高解像度な情報をDecoderに直接渡すことで、物体の境界などを精密に復元し、情報の損失を抑制します。
5. 実践エピソード:U-Netを用いた署名の抽出
セグメンテーション(U-Net)を実際のタスクに応用した際の実装経験をご紹介します。
タスク:書類からの「署名」の抽出
スキャンされた書類画像から、印鑑や署名部分だけをきれいに抽出(セグメンテーション)するモデルを構築しました。
-
学習データの作成:
OpenCVの単純な手法(閾値処理など)では精度が不十分だったため、GrabCutを用いて署名部分を切り抜き、U-Netの学習用教師データ(マスク画像)を作成しました。 -
モデルの実装:
PyTorchのライブラリであるsegmentation-models-pytorch(smp) を活用し、U-Netバックボーンのモデルを構築しました。 -
結果:
単純なOpenCVによる二値化や、GrabCut単体での処理に比べ、U-Netを用いたセグメンテーションの方が圧倒的に精度が高く、複雑な背景や掠れた署名でも安定して抽出することが可能になりました。
このように、古典的な画像処理(GrabCut)で高品質な教師データを作成し、それをディープラーニング(U-Net)に学習させるアプローチは、実務において非常に強力です。
参考文献
-
[1] Alexander Kirillov, et al. "Panoptic Segmentation" (CVPR 2019)
https://openaccess.thecvf.com/content_CVPR_2019/papers/Kirillov_Panoptic_Segmentation_CVPR_2019_paper.pdf -
[2] Olaf Ronneberger, et al. "U-Net: Convolutional Networks for Biomedical Image Segmentation" (MICCAI 2015)
https://arxiv.org/pdf/1505.04597
← 第七講へ | まとめページに戻る → | 第九講へ →