Lecture06: Summary of Computer Vision Tasks
画像認識タスクの整理とまとめ
前回の振り返りと今回のテーマ
第五講までで、機械学習の基礎からCNNの仕組みまでを学び、画像認識の「基礎編」が完結しました。
今回の第六講では、これから始まる「応用編 第一部」に向けて、画像認識(コンピュータビジョン)の世界でどのようなタスク(課題)があるのかを整理します。
これを知ることで、なぜ次回の第七講で学ぶ「YOLO」がそれほどまでに注目されているのか、その理由がより明確になります。
1. 主要な4つのタスク
画像認識の技術は、目的(何を知りたいか)によって大きく分類されます。
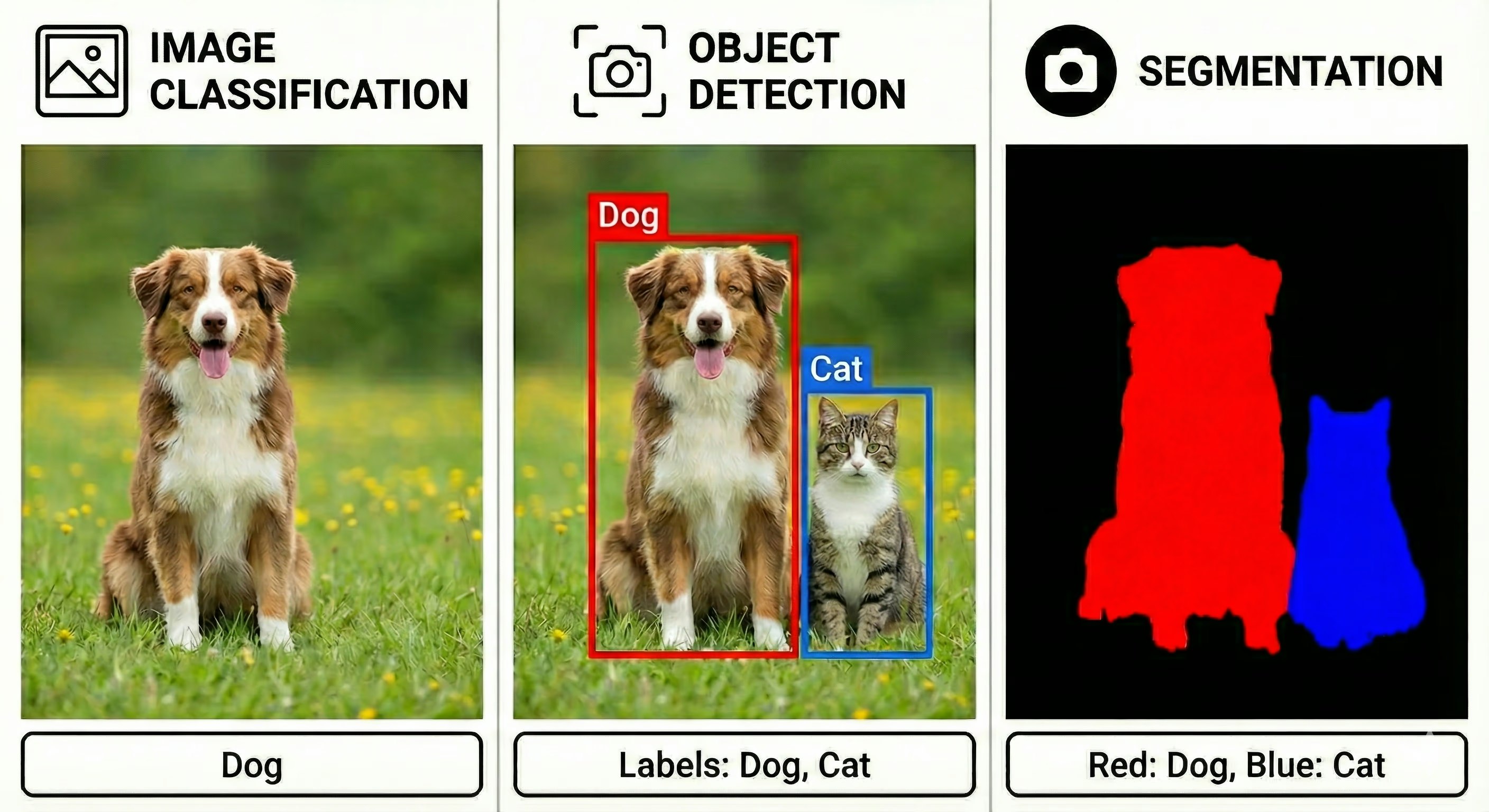
① 画像分類 (Image Classification)
- 内容: 画像全体を見て「これは何か」を判定します。
- 出力: クラス名(例:「犬」「猫」「車」)。
- 特徴: 第四講・第五講で学んだCNNの基本形です。位置までは特定しません。
② 物体検出 (Object Detection)
- 内容: 画像の中から「何が・どこに」あるかを特定します。
- 出力: クラス名 + バウンディングボックス(四角い枠)。
- 特徴: 複数の物体が同時に映っていても、それぞれを見つけ出し、座標も含めて特定します。
③ セグメンテーション (Segmentation)
- 内容: ピクセルレベルで「どこからどこまでがその物体か」を判定します。
- 出力: 物体の輪郭に沿った塗りつぶし(マスク)。
- 特徴: 最も精密な形状把握です。医療画像や背景合成などに使われます。
④ 姿勢推定 (Pose Estimation)
- 内容: 人物の「関節点(キーポイント)」を検出し、骨格を特定します。
- 出力: 関節の座標 + 関節間のつながり(スケルトン)。
- 特徴: 動作解析やスポーツ解析など、「何をしているか」の動的な理解に不可欠です。
2. タスク比較イメージと出力形式
画像認識タスクの進化は、「画像の中の情報をどれだけ細かく、具体的に取り出すか」の歴史でもあります。
■ 視覚的解像度の違い
■ 出力データの比較
タスクが高度になるにつれ、AIが返す「情報の密度」が上がっていきます。
| タスク | 出力の内容(エンジニア視点) | データの持ち方(例) | 精密度 |
|---|---|---|---|
| 画像分類 | 画像に紐づくひとつの答え | class_id: 3 (Dog) |
画像全体 |
| 物体検出 | 何がどこにあるか | [class, x, y, w, h] |
個体(Things) |
| セグメンテーション | どこまでが対象か | [0,0,1,1,0,...] |
ピクセル/領域 |
| 姿勢推定 | どんなポーズか | [kp1_x, kp1_y, conf, ...] |
人物の構造 |
3. なぜ「物体検出」が重要なのか?
ビジネスの現場において最も「費用対効果」が高く、応用範囲が広いのが 物体検出 です。
画像全体を分類するだけでは不十分で、かといって1ピクセル単位で形を切り抜くには計算コストが高すぎる——。その絶妙なバランスを実現し、リアルタイムで実用化にこぎつけたのが、次講で紹介する YOLO です。
いよいよ次回から、この中でも特に現場で大活躍している「物体検出モデル YOLO」の核心に迫ります。